Время на прочтение
8 мин
Количество просмотров 429K
Один преподаватель как-то сказал мне, что если поискать аналог программиста в мире книг, то окажется, что программисты похожи не на учебники, а на оглавления учебников: они не помнят всего, но знают, как быстро найти то, что им нужно.
Возможность быстро находить описания функций позволяет программистам продуктивно работать, не теряя состояния потока. Поэтому я и создал представленную здесь шпаргалку по pandas и включил в неё то, чем пользуюсь каждый день, создавая веб-приложения и модели машинного обучения.

Нельзя сказать, что это — исчерпывающий список возможностей pandas, но сюда входят функции, которыми я пользуюсь чаще всего, примеры и мои пояснения по поводу ситуаций, в которых эти функции особенно полезны.
1. Подготовка к работе
Если вы хотите самостоятельно опробовать то, о чём тут пойдёт речь, загрузите набор данных Anime Recommendations Database с Kaggle. Распакуйте его и поместите в ту же папку, где находится ваш Jupyter Notebook (далее — блокнот).
Теперь выполните следующие команды.
import pandas as pd
import numpy as np
anime = pd.read_csv('anime-recommendations-database/anime.csv')
rating = pd.read_csv('anime-recommendations-database/rating.csv')
anime_modified = anime.set_index('name')
После этого у вас должна появиться возможность воспроизвести то, что я покажу в следующих разделах этого материала.
2. Импорт данных
▍Загрузка CSV-данных
Здесь я хочу рассказать о преобразовании CSV-данных непосредственно в датафреймы (в объекты Dataframe). Иногда при загрузке данных формата CSV нужно указывать их кодировку (например, это может выглядеть как encoding='ISO-8859–1'). Это — первое, что стоит попробовать сделать в том случае, если оказывается, что после загрузки данных датафрейм содержит нечитаемые символы.
anime = pd.read_csv('anime-recommendations-database/anime.csv')

Загруженные CSV-данные
Существует похожая функция для загрузки данных из Excel-файлов — pd.read_excel.
▍Создание датафрейма из данных, введённых вручную
Это может пригодиться тогда, когда нужно вручную ввести в программу простые данные. Например — если нужно оценить изменения, претерпеваемые данными, проходящими через конвейер обработки данных.
df = pd.DataFrame([[1,'Bob', 'Builder'],
[2,'Sally', 'Baker'],
[3,'Scott', 'Candle Stick Maker']],
columns=['id','name', 'occupation'])

Данные, введённые вручную
▍Копирование датафрейма
Копирование датафреймов может пригодиться в ситуациях, когда требуется внести в данные изменения, но при этом надо и сохранить оригинал. Если датафреймы нужно копировать, то рекомендуется делать это сразу после их загрузки.
anime_copy = anime.copy(deep=True)

Копия датафрейма
3. Экспорт данных
▍Экспорт в формат CSV
При экспорте данных они сохраняются в той же папке, где находится блокнот. Ниже показан пример сохранения первых 10 строк датафрейма, но то, что именно сохранять, зависит от конкретной задачи.
rating[:10].to_csv('saved_ratings.csv', index=False)
Экспортировать данные в виде Excel-файлов можно с помощью функции df.to_excel.
4. Просмотр и исследование данных
▍Получение n записей из начала или конца датафрейма
Сначала поговорим о выводе первых n элементов датафрейма. Я часто вывожу некоторое количество элементов из начала датафрейма где-нибудь в блокноте. Это позволяет мне удобно обращаться к этим данным в том случае, если я забуду о том, что именно находится в датафрейме. Похожую роль играет и вывод нескольких последних элементов.
anime.head(3)
rating.tail(1)

Данные из начала датафрейма

Данные из конца датафрейма
▍Подсчёт количества строк в датафрейме
Функция len(), которую я тут покажу, не входит в состав pandas. Но она хорошо подходит для подсчёта количества строк датафреймов. Результаты её работы можно сохранить в переменной и воспользоваться ими там, где они нужны.
len(df)
#=> 3
▍Подсчёт количества уникальных значений в столбце
Для подсчёта количества уникальных значений в столбце можно воспользоваться такой конструкцией:
len(ratings['user_id'].unique())
▍Получение сведений о датафрейме
В сведения о датафрейме входит общая информация о нём вроде заголовка, количества значений, типов данных столбцов.
anime.info()

Сведения о датафрейме
Есть ещё одна функция, похожая на df.info — df.dtypes. Она лишь выводит сведения о типах данных столбцов.
▍Вывод статистических сведений о датафрейме
Знание статистических сведений о датафрейме весьма полезно в ситуациях, когда он содержит множество числовых значений. Например, знание среднего, минимального и максимального значений столбца rating даёт нам некоторое понимание того, как, в целом, выглядит датафрейм. Вот соответствующая команда:
anime.describe()

Статистические сведения о датафрейме
▍Подсчёт количества значений
Для того чтобы подсчитать количество значений в конкретном столбце, можно воспользоваться следующей конструкцией:
anime.type.value_counts()

Подсчёт количества элементов в столбце
5. Извлечение информации из датафреймов
▍Создание списка или объекта Series на основе значений столбца
Это может пригодиться в тех случаях, когда требуется извлекать значения столбцов в переменные x и y для обучения модели. Здесь применимы следующие команды:
anime['genre'].tolist()
anime['genre']

Результаты работы команды anime[‘genre’].tolist()

Результаты работы команды anime[‘genre’]
▍Получение списка значений из индекса
Поговорим о получении списков значений из индекса. Обратите внимание на то, что я здесь использовал датафрейм anime_modified, так как его индексные значения выглядят интереснее.
anime_modified.index.tolist()

Результаты выполнения команды
▍Получение списка значений столбцов
Вот команда, которая позволяет получить список значений столбцов:
anime.columns.tolist()

Результаты выполнения команды
6. Добавление данных в датафрейм и удаление их из него
▍Присоединение к датафрейму нового столбца с заданным значением
Иногда мне приходится добавлять в датафреймы новые столбцы. Например — в случаях, когда у меня есть тестовый и обучающий наборы в двух разных датафреймах, и мне, прежде чем их скомбинировать, нужно пометить их так, чтобы потом их можно было бы различить. Для этого используется такая конструкция:
anime['train set'] = True
▍Создание нового датафрейма из подмножества столбцов
Это может пригодиться в том случае, если требуется сохранить в новом датафрейме несколько столбцов огромного датафрейма, но при этом не хочется выписывать имена столбцов, которые нужно удалить.
anime[['name','episodes']]

Результат выполнения команды
▍Удаление заданных столбцов
Этот приём может оказаться полезным в том случае, если из датафрейма нужно удалить лишь несколько столбцов. Если удалять нужно много столбцов, то эта задача может оказаться довольно-таки утомительной, поэтому тут я предпочитаю пользоваться возможностью, описанной в предыдущем разделе.
anime.drop(['anime_id', 'genre', 'members'], axis=1).head()

Результаты выполнения команды
▍Добавление в датафрейм строки с суммой значений из других строк
Для демонстрации этого примера самостоятельно создадим небольшой датафрейм, с которым удобно работать. Самое интересное здесь — это конструкция df.sum(axis=0), которая позволяет получать суммы значений из различных строк.
df = pd.DataFrame([[1,'Bob', 8000],
[2,'Sally', 9000],
[3,'Scott', 20]], columns=['id','name', 'power level'])
df.append(df.sum(axis=0), ignore_index=True)

Результат выполнения команды
Команда вида df.sum(axis=1) позволяет суммировать значения в столбцах.
Похожий механизм применим и для расчёта средних значений. Например — df.mean(axis=0).
7. Комбинирование датафреймов
▍Конкатенация двух датафреймов
Эта методика применима в ситуациях, когда имеются два датафрейма с одинаковыми столбцами, которые нужно скомбинировать.
В данном примере мы сначала разделяем датафрейм на две части, а потом снова объединяем эти части:
df1 = anime[0:2]
df2 = anime[2:4]
pd.concat([df1, df2], ignore_index=True)

Датафрейм df1

Датафрейм df2

Датафрейм, объединяющий df1 и df2
▍Слияние датафреймов
Функция df.merge, которую мы тут рассмотрим, похожа на левое соединение SQL. Она применяется тогда, когда два датафрейма нужно объединить по некоему столбцу.
rating.merge(anime, left_on=’anime_id’, right_on=’anime_id’, suffixes=(‘_left’, ‘_right’))

Результаты выполнения команды
8. Фильтрация
▍Получение строк с нужными индексными значениями
Индексными значениями датафрейма anime_modified являются названия аниме. Обратите внимание на то, как мы используем эти названия для выбора конкретных столбцов.
anime_modified.loc[['Haikyuu!! Second Season','Gintama']]

Результаты выполнения команды
▍Получение строк по числовым индексам
Эта методика отличается от той, которая описана в предыдущем разделе. При использовании функции df.iloc первой строке назначается индекс 0, второй — индекс 1, и так далее. Такие индексы назначаются строкам даже в том случае, если датафрейм был модифицирован и в его индексном столбце используются строковые значения.
Следующая конструкция позволяет выбрать три первых строки датафрейма:
anime_modified.iloc[0:3]

Результаты выполнения команды
▍Получение строк по заданным значениям столбцов
Для получения строк датафрейма в ситуации, когда имеется список значений столбцов, можно воспользоваться следующей командой:
anime[anime['type'].isin(['TV', 'Movie'])]

Результаты выполнения команды
Если нас интересует единственное значение — можно воспользоваться такой конструкцией:
anime[anime[‘type’] == 'TV']
▍Получение среза датафрейма
Эта техника напоминает получение среза списка. А именно, речь идёт о получении фрагмента датафрейма, содержащего строки, соответствующие заданной конфигурации индексов.
anime[1:3]

Результаты выполнения команды
▍Фильтрация по значению
Из датафреймов можно выбирать строки, соответствующие заданному условию. Обратите внимание на то, что при использовании этого метода сохраняются существующие индексные значения.
anime[anime['rating'] > 8]

Результаты выполнения команды
9. Сортировка
Для сортировки датафреймов по значениям столбцов можно воспользоваться функцией df.sort_values:
anime.sort_values('rating', ascending=False)

Результаты выполнения команды
10. Агрегирование
▍Функция df.groupby и подсчёт количества записей
Вот как подсчитать количество записей с различными значениями в столбцах:
anime.groupby('type').count()

Результаты выполнения команды
▍Функция df.groupby и агрегирование столбцов различными способами
Обратите внимание на то, что здесь используется reset_index(). В противном случае столбец type становится индексным столбцом. В большинстве случаев я рекомендую делать то же самое.
anime.groupby(["type"]).agg({
"rating": "sum",
"episodes": "count",
"name": "last"
}).reset_index()
▍Создание сводной таблицы
Для того чтобы извлечь из датафрейма некие данные, нет ничего лучше, чем сводная таблица. Обратите внимание на то, что здесь я серьёзно отфильтровал датафрейм, что ускорило создание сводной таблицы.
tmp_df = rating.copy()
tmp_df.sort_values('user_id', ascending=True, inplace=True)
tmp_df = tmp_df[tmp_df.user_id < 10]
tmp_df = tmp_df[tmp_df.anime_id < 30]
tmp_df = tmp_df[tmp_df.rating != -1]
pd.pivot_table(tmp_df, values='rating', index=['user_id'], columns=['anime_id'], aggfunc=np.sum, fill_value=0)

Результаты выполнения команды
11. Очистка данных
▍Запись в ячейки, содержащие значение NaN, какого-то другого значения
Здесь мы поговорим о записи значения 0 в ячейки, содержащие значение NaN. В этом примере мы создаём такую же сводную таблицу, как и ранее, но без использования fill_value=0. А затем используем функцию fillna(0) для замены значений NaN на 0.
pivot = pd.pivot_table(tmp_df, values='rating', index=['user_id'], columns=['anime_id'], aggfunc=np.sum)
pivot.fillna(0)

Таблица, содержащая значения NaN

Результаты замены значений NaN на 0
12. Другие полезные возможности
▍Отбор случайных образцов из набора данных
Я использую функцию df.sample каждый раз, когда мне нужно получить небольшой случайный набор строк из большого датафрейма. Если используется параметр frac=1, то функция позволяет получить аналог исходного датафрейма, строки которого будут перемешаны.
anime.sample(frac=0.25)

Результаты выполнения команды
▍Перебор строк датафрейма
Следующая конструкция позволяет перебирать строки датафрейма:
for idx,row in anime[:2].iterrows():
print(idx, row)

Результаты выполнения команды
▍Борьба с ошибкой IOPub data rate exceeded
Если вы сталкиваетесь с ошибкой IOPub data rate exceeded — попробуйте, при запуске Jupyter Notebook, воспользоваться следующей командой:
jupyter notebook — NotebookApp.iopub_data_rate_limit=1.0e10
Итоги
Здесь я рассказал о некоторых полезных приёмах использования pandas в среде Jupyter Notebook. Надеюсь, моя шпаргалка вам пригодится.
Уважаемые читатели! Есть ли какие-нибудь возможности pandas, без которых вы не представляете своей повседневной работы?

В прошлой главе мы познакомились с библиотекой numpy и узнали, что она позволяет существенно ускорить вычисления в Python. А сейчас мы рассмотрим библиотеку pandas, которая применяется для обработки и анализа табличных данных. В этой библиотеке используется numpy для удобного хранения данных и вычислений.
Для установки pandas выполним в командной строке команду:
pip install pandas
Во всех примерах предполагается, что библиотеки numpy и pandas импортированы следующим образом:
import numpy as np
import pandas as pd
В библиотеке pandas определены два класса объектов для работы с данными:
Series— одномерный массив, который может хранить значения любого типа данных;DataFrame— двумерный массив (таблица), в котором столбцами являются объекты классаSeries.
Создать объект класса Series можно следующим образом:
s = pd.Series(data, index=index)
В качестве data могут выступать: массив numpy, словарь, число. В аргумент index передаётся список меток осей. Метка может быть числом, но чаще используются метки-строки.
Если data является массивом numpy, то index должен иметь такую же длину, как и data. Если аргумент index не передаётся, то по умолчанию для index автоматически назначается список [0, …, len(data) — 1]:
s = pd.Series(np.arange(5), index=["a", "b", "c", "d", "e"])
print(s)
print()
s = pd.Series(np.linspace(0, 1, 5))
print(s)
Вывод программы:
a 0 b 1 c 2 d 3 e 4 dtype: int32 0 0.00 1 0.25 2 0.50 3 0.75 4 1.00 dtype: float64
Из вывода программы видно, что Series фактически является аналогом словаря, так как вместо числовых индексов может использовать метки в виде строк.
Если data задаётся словарём, а index не передаётся, то в качестве индекса используются ключи-словари. Если index передаётся, то его длина может не совпадать с длиной словаря data. В таком случае по индексам, для которых нет ключа с соответствующим значением в словаре, будут храниться значения NaN — стандартное обозначение отсутствия данных в библиотеке pandas.
d = {"a": 10, "b": 20, "c": 30, "g": 40}
print(pd.Series(d))
print()
print(pd.Series(d, index=["a", "b", "c", "d"]))
a 10 b 20 c 30 g 40 dtype: int64 a 10.0 b 20.0 c 30.0 d NaN dtype: float64
Если data задаётся числом, то index нужно обязательно передать. Количество элементов в Series будет равно числу меток в index, а значения будут равны data:
index = ["a", "b", "c"]
print(pd.Series(5, index=index))
Вывод программы:
a 5 b 5 c 5 dtype: int64
Для Series доступно взятие элемента по индексу, срезы, поэлементные математические операции аналогично массивам numpy.
s = pd.Series(np.arange(5), index=["a", "b", "c", "d", "e"])
print("Выбор одного элемента")
print(s["a"])
print("Выбор нескольких элементов")
print(s[["a", "d"]])
print("Срез")
print(s[1:])
print("Поэлементное сложение")
print(s + s)
Вывод программы:
Выбор одного элемента 0 Выбор нескольких элементов a 0 d 3 dtype: int32 Срез b 1 c 2 d 3 e 4 dtype: int32 Поэлементное сложение a 0 b 2 c 4 d 6 e 8 dtype: int32
Для Series можно применять фильтрацию данных по условию, записанному в качестве индекса:
s = pd.Series(np.arange(5), index=["a", "b", "c", "d", "e"])
print("Фильтрация")
print(s[s > 2])
Вывод программы:
Фильтрация d 3 e 4 dtype: int32
Объекты Series имеют атрибут name со значением имени набора данных, а также атрибут index.name с именем для индексов:
s = pd.Series(np.arange(5), index=["a", "b", "c", "d", "e"])
s.name = "Данные"
s.index.name = "Индекс"
print(s)
Вывод программы:
Индекс a 0 b 1 c 2 d 3 e 4 Name: Данные, dtype: int32
Объект класса DataFrame работает с двумерными табличными данными. Создать DataFrame проще всего из словаря Python следующим образом:
students_marks_dict = {"student": ["Студент_1", "Студент_2", "Студент_3"],
"math": [5, 3, 4],
"physics": [4, 5, 5]}
students = pd.DataFrame(students_marks_dict)
print(students)
Вывод программы:
student math physics 0 Студент_1 5 4 1 Студент_2 3 5 2 Студент_3 4 5
У объекта класса DataFrame есть индексы по строкам (index) и столбцам (columns):
print(students.index)
print(students.columns)
Вывод программы:
RangeIndex(start=0, stop=3, step=1) Index(['student', 'math', 'physics'], dtype='object')
Для индекса по строке по умолчанию задаётся числовое значение. Значения индекса можно заменить путём записи списка в атрибут index:
students.index = ["A", "B", "C"]
print(students)
Вывод программы:
student math physics A Студент_1 5 4 B Студент_2 3 5 C Студент_3 4 5
Для доступа к записям таблицы по строковой метке используется атрибут loc. При использовании строковой метки доступна операция среза:
print(students.loc["B":])
Вывод программы:
student math physics B Студент_2 3 5 C Студент_3 4 5
Убедимся, что столбцы у DataFrame являются объектами класса Series:
print(type(students["student"]))
Вывод программы:
<class 'pandas.core.series.Series'>
Обычно табличные данные хранятся в файлах. Такие наборы данных принято называть дата-сетами. Файлы с дата-сетом могут иметь различный формат. Pandas поддерживает операции чтения и записи для CSV, Excel 2007+, SQL, HTML, JSON, буфер обмена и др.
Несколько примеров, как получить дата-сет из файлов разных форматов:
- CSV. Используется функция
read_csv(). Аргументfileявляется строкой, в которой записан путь до файла с дата-сетом. Для записи данных изDataFrameв CSV-файл используется методto_csv(file). - Excel. Используется функция
read_excel(). Для записи данных изDataFrameв Excel-файл используется методto_excel(). - JSON. Используется функция
read_json(). Для записи данных изDataFrameв JSON используется методto_json().
Для работы с другими форматами файлов в pandas есть функции, работающие аналогично рассмотренным. С ними можно ознакомиться в документации.
Одним из самых популярных форматов хранения табличных данных является CSV (Comma Separated Values, значения с разделителем-запятой). В файлах этого формата данные хранятся в текстовом виде. Строки таблицы записываются в файле с новой строки, а столбцы разделяются определённым символом, чаще всего запятой ‘,’ или точкой с запятой ‘;’. Первая строка, как правило, содержит заголовки столбцов таблицы. Пример части CSV-файла с информацией о результатах прохождения тестов студентами и некоторой дополнительной информацией:
"gender","race/ethnicity","parental level of education","lunch","test preparation course","math score","reading score","writing score" "female","group B","bachelor's degree","standard","none","72","72","74" "female","group C","some college","standard","completed","69","90","88"
Для дальнейшей работы скачайте данный файл с дата-сетом.
Получим дата-сет из CSV-файла с данными о студентах:
import numpy as np
import pandas as pd
students = pd.read_csv("StudentsPerformance.csv")
Полученный объект students относится к классу DataFrame.
Для получения первых n строк дата-сета используется метод head(n). По умолчанию возвращается пять первых строк:
print(students.head())
Вывод программы:
gender race/ethnicity ... reading score writing score 0 female group B ... 72 74 1 female group C ... 90 88 2 female group B ... 95 93 3 male group A ... 57 44 4 male group C ... 78 75 [5 rows x 8 columns]
Для получения последних n строк используется метод tail(n). По умолчанию возвращается пять последних строк:
print(student.tail(3))
Вывод программы:
gender race/ethnicity ... reading score writing score 997 female group C ... 71 65 998 female group D ... 78 77 999 female group D ... 86 86 [3 rows x 8 columns]
Для получения части дата-сета можно использовать срез:
print(students[10:13])
gender race/ethnicity ... reading score writing score 10 male group C ... 54 52 11 male group D ... 52 43 12 female group B ... 81 73 [3 rows x 8 columns]
В качестве индекса можно использовать условия для фильтрации данных. Выберем пять первых результатов теста по математике для студентов, прошедших подготовительный курс.
print(students[students["test preparation course"] == "completed"]["math score"].head())
Вывод программы:
1 69 6 88 8 64 13 78 18 46 Name: math score, dtype: int64
Выведем пять лучших результатов тестов по трём дисциплинам для предыдущей выборки с помощью сортировки методом sort_values(). Сортировка по умолчанию производится в порядке возрастания значений. Для сортировки по убыванию в именованный аргумент ascending передаётся значение False.
with_course = students[students["test preparation course"] == "completed"]
print(with_course[["math score",
"reading score",
"writing score"]].sort_values(["math score",
"reading score",
"writing score"], ascending=False).head())
Вывод программы:
math score reading score writing score 916 100 100 100 149 100 100 93 625 100 97 99 623 100 96 86 114 99 100 100
При сортировке сравнивались последовательно значения в перечисленных столбцах. Проведём сортировку по сумме баллов за тесты. Для этого создадим ещё один столбец total_score и произведём по нему сортировку:
with_course = students[students["test preparation course"] == "completed"]
students["total score"] = students["math score"] + students["reading score"] + students["writing score"]
print(students.sort_values(["total score"], ascending=False).head())
Вывод программы:
gender race/ethnicity ... writing score total score 916 male group E ... 100 300 458 female group E ... 100 300 962 female group E ... 100 300 114 female group E ... 100 299 179 female group D ... 100 297 [5 rows x 9 columns]
Чтобы в таблицу добавить колонку, подойдёт метод assign(). Данный метод даёт возможность создавать колонки при помощи лямбда-функции. Обратите внимание: данный метод возвращает новую таблицу, а не меняет исходную. Перепишем предыдущий пример с использованием assign():
scores = students.assign(total_score=lambda x: x["math score"] + x["reading score"] + x["writing score"])
print(scores.sort_values(["total_score"], ascending=False).head())
Вывод программы:
gender race/ethnicity ... writing score total_score 916 male group E ... 100 300 458 female group E ... 100 300 962 female group E ... 100 300 114 female group E ... 100 299 179 female group D ... 100 297
При анализе данных часто требуется сгруппировать записи по какому-то признаку. Для выполнения операции группировки в pandas используется метод groupby(). Сама по себе группировка для рассматриваемого дата-сета даёт мало информации. Поэтому воспользуемся методом count(), чтобы определить количество сгруппированных записей. Получим информацию о количестве студентов мужского и женского пола (поле «gender»), прошедших курс по подготовке к тестированию (поле «test preparation course»):
print(students.groupby(["gender", "test preparation course"])["writing score"].count())
Вывод программы:
gender test preparation course
female completed 184
none 334
male completed 174
none 308
Name: race/ethnicity, dtype: int64
Если необходимо выполнить операцию, которая позволяет получить сводные данные, то такая операция называется агрегацией. Примерами функции агрегации являются сумма, среднее арифметическое, минимум, максимум и др. Для применения функции агрегации к нескольким столбцам подойдёт метод agg(), в который можно передать словарь с ключами — названиями столбцов, а значения по ключам могут быть списками функций агрегации.
Покажем использование агрегации на примере. Определим среднее арифметическое и медианное значения балла за тест по математике для студентов мужского и женского пола в зависимости от прохождения подготовительного курса:
agg_functions = {"math score": ["mean", "median"]}
print(students.groupby(["gender", "test preparation course"]).agg(agg_functions))
Вывод программы:
math score
mean median
gender test preparation course
female completed 67.195652 67.0
none 61.670659 62.0
male completed 72.339080 73.0
none 66.688312 67.0
Для визуализации данных pandas использует библиотеку matplotlib. Для её установки выполните в командной строке следующую команду:
pip install matplotlib
Для использования визуализации добавьте следующую строку импорта в начало программы:
import matplotlib.pyplot as plt
Построим гистограмму, которая показывает распределение количества студентов по баллам за тест по математике:
plt.hist(students["math score"], label="Тест по математике")
plt.xlabel("Баллы за тест")
plt.ylabel("Количество студентов")
plt.legend()
plt.show()
В результате работы программы получим следующую гистограмму:

Ещё по теме
Библиотека pandas предоставляет широкие возможности по обработке и анализу данных, поэтому в этой главе мы рассмотрели лишь базовые методы обработки, анализа и визуализации данных. Для более детального изучения советуем почитать документацию.
pandas это высокоуровневая Python библиотека для анализа данных. Почему я её называю высокоуровневой, потому что построена она поверх более низкоуровневой библиотеки NumPy (написана на Си), что является большим плюсом в производительности. В экосистеме Python, pandas является наиболее продвинутой и быстроразвивающейся библиотекой для обработки и анализа данных. В своей работе мне приходится пользоваться ею практически каждый день, поэтому я пишу эту краткую заметку для того, чтобы в будущем ссылаться к ней, если вдруг что-то забуду. Также надеюсь, что читателям блога заметка поможет в решении их собственных задач с помощью pandas, и послужит небольшим введением в возможности этой библиотеки.
DataFrame и Series
Чтобы эффективно работать с pandas, необходимо освоить самые главные структуры данных библиотеки: DataFrame и Series. Без понимания что они из себя представляют, невозможно в дальнейшем проводить качественный анализ.
Series
Структура/объект Series представляет из себя объект, похожий на одномерный массив (питоновский список, например), но отличительной его чертой является наличие ассоциированных меток, т.н. индексов, вдоль каждого элемента из списка. Такая особенность превращает его в ассоциативный массив или словарь в Python.
>>> import pandas as pd
>>> my_series = pd.Series([5, 6, 7, 8, 9, 10])
>>> my_series
0 5
1 6
2 7
3 8
4 9
5 10
dtype: int64
>>>
В строковом представлении объекта Series, индекс находится слева, а сам элемент справа. Если индекс явно не задан, то pandas автоматически создаёт RangeIndex от 0 до N-1, где N общее количество элементов. Также стоит обратить, что у Series есть тип хранимых элементов, в нашем случае это int64, т.к. мы передали целочисленные значения.
У объекта Series есть атрибуты через которые можно получить список элементов и индексы, это values и index соответственно.
>>> my_series.index
RangeIndex(start=0, stop=6, step=1)
>>> my_series.values
array([ 5, 6, 7, 8, 9, 10], dtype=int64)
Доступ к элементам объекта Series возможны по их индексу (вспоминается аналогия со словарем и доступом по ключу).
>>> my_series[4]
9
Индексы можно задавать явно:
>>> my_series2 = pd.Series([5, 6, 7, 8, 9, 10], index=['a', 'b', 'c', 'd', 'e', 'f'])
>>> my_series2['f']
10
Делать выборку по нескольким индексам и осуществлять групповое присваивание:
>>> my_series2[['a', 'b', 'f']]
a 5
b 6
f 10
dtype: int64
>>> my_series2[['a', 'b', 'f']] = 0
>>> my_series2
a 0
b 0
c 7
d 8
e 9
f 0
dtype: int64
Фильтровать Series как душе заблагорассудится, а также применять математические операции и многое другое:
>>> my_series2[my_series2 > 0]
c 7
d 8
e 9
dtype: int64
>>> my_series2[my_series2 > 0] * 2
c 14
d 16
e 18
dtype: int64
Если Series напоминает нам словарь, где ключом является индекс, а значением сам элемент, то можно сделать так:
>>> my_series3 = pd.Series({'a': 5, 'b': 6, 'c': 7, 'd': 8})
>>> my_series3
a 5
b 6
c 7
d 8
dtype: int64
>>> 'd' in my_series3
True
У объекта Series и его индекса есть атрибут name, задающий имя объекту и индексу соответственно.
>>> my_series3.name = 'numbers'
>>> my_series3.index.name = 'letters'
>>> my_series3
letters
a 5
b 6
c 7
d 8
Name: numbers, dtype: int64
Индекс можно поменять «на лету», присвоив список атрибуту index объекта Series
>>> my_series3.index = ['A', 'B', 'C', 'D']
>>> my_series3
A 5
B 6
C 7
D 8
Name: numbers, dtype: int64
Имейте в виду, что список с индексами по длине должен совпадать с количеством элементов в Series.
DataFrame
Объект DataFrame лучше всего представлять себе в виде обычной таблицы и это правильно, ведь DataFrame является табличной структурой данных. В любой таблице всегда присутствуют строки и столбцы. Столбцами в объекте DataFrame выступают объекты Series, строки которых являются их непосредственными элементами.
DataFrame проще всего сконструировать на примере питоновского словаря:
>>> df = pd.DataFrame({
... 'country': ['Kazakhstan', 'Russia', 'Belarus', 'Ukraine'],
... 'population': [17.04, 143.5, 9.5, 45.5],
... 'square': [2724902, 17125191, 207600, 603628]
... })
>>> df
country population square
0 Kazakhstan 17.04 2724902
1 Russia 143.50 17125191
2 Belarus 9.50 207600
3 Ukraine 45.50 603628
Чтобы убедиться, что столбец в DataFrame это Series, извлекаем любой:
>>> df['country']
0 Kazakhstan
1 Russia
2 Belarus
3 Ukraine
Name: country, dtype: object
>>> type(df['country'])
<class 'pandas.core.series.Series'>
Объект DataFrame имеет 2 индекса: по строкам и по столбцам. Если индекс по строкам явно не задан (например, колонка по которой нужно их строить), то pandas задаёт целочисленный индекс RangeIndex от 0 до N-1, где N это количество строк в таблице.
>>> df.columns
Index([u'country', u'population', u'square'], dtype='object')
>>> df.index
RangeIndex(start=0, stop=4, step=1)
В таблице у нас 4 элемента от 0 до 3.
Доступ по индексу в DataFrame
Индекс по строкам можно задать разными способами, например, при формировании самого объекта DataFrame или «на лету»:
>>> df = pd.DataFrame({
... 'country': ['Kazakhstan', 'Russia', 'Belarus', 'Ukraine'],
... 'population': [17.04, 143.5, 9.5, 45.5],
... 'square': [2724902, 17125191, 207600, 603628]
... }, index=['KZ', 'RU', 'BY', 'UA'])
>>> df
country population square
KZ Kazakhstan 17.04 2724902
RU Russia 143.50 17125191
BY Belarus 9.50 207600
UA Ukraine 45.50 603628
>>> df.index = ['KZ', 'RU', 'BY', 'UA']
>>> df.index.name = 'Country Code'
>>> df
country population square
Country Code
KZ Kazakhstan 17.04 2724902
RU Russia 143.50 17125191
BY Belarus 9.50 207600
UA Ukraine 45.50 603628
Как видно, индексу было задано имя — Country Code. Отмечу, что объекты Series из DataFrame будут иметь те же индексы, что и объект DataFrame:
>>> df['country']
Country Code
KZ Kazakhstan
RU Russia
BY Belarus
UA Ukraine
Name: country, dtype: object
Доступ к строкам по индексу возможен несколькими способами:
- .loc — используется для доступа по строковой метке
- .iloc — используется для доступа по числовому значению (начиная от 0)
>>> df.loc['KZ']
country Kazakhstan
population 17.04
square 2724902
Name: KZ, dtype: object
>>> df.iloc[0]
country Kazakhstan
population 17.04
square 2724902
Name: KZ, dtype: object
Можно делать выборку по индексу и интересующим колонкам:
>>> df.loc[['KZ', 'RU'], 'population']
Country Code
KZ 17.04
RU 143.50
Name: population, dtype: float64
Как можно заметить, .loc в квадратных скобках принимает 2 аргумента: интересующий индекс, в том числе поддерживается слайсинг и колонки.
>>> df.loc['KZ':'BY', :]
country population square
Country Code
KZ Kazakhstan 17.04 2724902
RU Russia 143.50 17125191
BY Belarus 9.50 207600
Фильтровать DataFrame с помощью т.н. булевых массивов:
>>> df[df.population > 10][['country', 'square']]
country square
Country Code
KZ Kazakhstan 2724902
RU Russia 17125191
UA Ukraine 603628
Кстати, к столбцам можно обращаться, используя атрибут или нотацию словарей Python, т.е. df.population и df[‘population’] это одно и то же.
Сбросить индексы можно вот так:
>>> df.reset_index()
Country Code country population square
0 KZ Kazakhstan 17.04 2724902
1 RU Russia 143.50 17125191
2 BY Belarus 9.50 207600
3 UA Ukraine 45.50 603628
pandas при операциях над DataFrame, возвращает новый объект DataFrame.
Добавим новый столбец, в котором население (в миллионах) поделим на площадь страны, получив тем самым плотность:
>>> df['density'] = df['population'] / df['square'] * 1000000
>>> df
country population square density
Country Code
KZ Kazakhstan 17.04 2724902 6.253436
RU Russia 143.50 17125191 8.379469
BY Belarus 9.50 207600 45.761079
UA Ukraine 45.50 603628 75.377550
Не нравится новый столбец? Не проблема, удалим его:
>>> df.drop(['density'], axis='columns')
country population square
Country Code
KZ Kazakhstan 17.04 2724902
RU Russia 143.50 17125191
BY Belarus 9.50 207600
UA Ukraine 45.50 603628
Особо ленивые могут просто написать del df[‘density’].
Переименовывать столбцы нужно через метод rename:
>>> df = df.rename(columns={'Country Code': 'country_code'})
>>> df
country_code country population square
0 KZ Kazakhstan 17.04 2724902
1 RU Russia 143.50 17125191
2 BY Belarus 9.50 207600
3 UA Ukraine 45.50 603628
В этом примере перед тем как переименовать столбец Country Code, убедитесь, что с него сброшен индекс, иначе не будет никакого эффекта.
Чтение и запись данных
pandas поддерживает все самые популярные форматы хранения данных: csv, excel, sql, буфер обмена, html и многое другое:
Чаще всего приходится работать с csv-файлами. Например, чтобы сохранить наш DataFrame со странами, достаточно написать:
>>> df.to_csv('filename.csv')Функции to_csv ещё передаются различные аргументы (например, символ разделителя между колонками) о которых подробнее можно узнать в официальной документации.
Считать данные из csv-файла и превратить в DataFrame можно функцией read_csv.
>>> df = pd.read_csv('filename.csv', sep=',')
Аргумент sep указывает разделитесь столбцов. Существует ещё масса способов сформировать DataFrame из различных источников, но наиболее часто используют CSV, Excel и SQL. Например, с помощью функции read_sql, pandas может выполнить SQL запрос и на основе ответа от базы данных сформировать необходимый DataFrame. За более подробной информацией стоит обратиться к официальной документации.
Группировка и агрегирование в pandas
Группировка данных один из самых часто используемых методов при анализе данных. В pandas за группировку отвечает метод .groupby. Я долго думал какой пример будет наиболее наглядным, чтобы продемонстрировать группировку, решил взять стандартный набор данных (dataset), использующийся во всех курсах про анализ данных — данные о пассажирах Титаника. Скачать CSV файл можно тут.
>>> titanic_df = pd.read_csv('titanic.csv')
>>> print(titanic_df.head())
PassengerID Name PClass Age
0 1 Allen, Miss Elisabeth Walton 1st 29.00
1 2 Allison, Miss Helen Loraine 1st 2.00
2 3 Allison, Mr Hudson Joshua Creighton 1st 30.00
3 4 Allison, Mrs Hudson JC (Bessie Waldo Daniels) 1st 25.00
4 5 Allison, Master Hudson Trevor 1st 0.92
Sex Survived SexCode
0 female 1 1
1 female 0 1
2 male 0 0
3 female 0 1
4 male 1 0
Необходимо подсчитать, сколько женщин и мужчин выжило, а сколько нет. В этом нам поможет метод .groupby.
>>> print(titanic_df.groupby(['Sex', 'Survived'])['PassengerID'].count())
Sex Survived
female 0 154
1 308
male 0 709
1 142
Name: PassengerID, dtype: int64
А теперь проанализируем в разрезе класса кабины:
>>> print(titanic_df.groupby(['PClass', 'Survived'])['PassengerID'].count())
PClass Survived
* 0 1
1st 0 129
1 193
2nd 0 160
1 119
3rd 0 573
1 138
Name: PassengerID, dtype: int64
Сводные таблицы в pandas
Термин «сводная таблица» хорошо известен тем, кто не по наслышке знаком с инструментом Microsoft Excel или любым иным, предназначенным для обработки и анализа данных. В pandas сводные таблицы строятся через метод .pivot_table. За основу возьмём всё тот же пример с Титаником. Например, перед нами стоит задача посчитать сколько всего женщин и мужчин было в конкретном классе корабля:
>>> titanic_df = pd.read_csv('titanic.csv')
>>> pvt = titanic_df.pivot_table(index=['Sex'], columns=['PClass'], values='Name', aggfunc='count')
В качестве индекса теперь у нас будет пол человека, колонками станут значения из PClass, функцией агрегирования будет count (подсчёт количества записей) по колонке Name.
>>> print(pvt.loc['female', ['1st', '2nd', '3rd']])
PClass
1st 143.0
2nd 107.0
3rd 212.0
Name: female, dtype: float64
Всё очень просто.
Анализ временных рядов
В pandas очень удобно анализировать временные ряды. В качестве показательного примера я буду использовать цену на акции корпорации Apple за 5 лет по дням. Файл с данными можно скачать тут.
>>> import pandas as pd
>>> df = pd.read_csv('apple.csv', index_col='Date', parse_dates=True)
>>> df = df.sort_index()
>>> print(df.info())
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 1258 entries, 2017-02-22 to 2012-02-23
Data columns (total 6 columns):
Open 1258 non-null float64
High 1258 non-null float64
Low 1258 non-null float64
Close 1258 non-null float64
Volume 1258 non-null int64
Adj Close 1258 non-null float64
dtypes: float64(5), int64(1)
memory usage: 68.8 KB
Здесь мы формируем DataFrame с DatetimeIndex по колонке Date и сортируем новый индекс в правильном порядке для работы с выборками. Если колонка имеет формат даты и времени отличный от ISO8601, то для правильного перевода строки в нужный тип, можно использовать метод pandas.to_datetime.
Давайте теперь узнаем среднюю цену акции (mean) на закрытии (Close):
>>> df.loc['2012-Feb', 'Close'].mean()
528.4820021999999
А если взять промежуток с февраля 2012 по февраль 2015 и посчитать среднее:
>>> df.loc['2012-Feb':'2015-Feb', 'Close'].mean()
430.43968317018414
А что если нам нужно узнать среднюю цену закрытия по неделям?!
>>> df.resample('W')['Close'].mean()
Date
2012-02-26 519.399979
2012-03-04 538.652008
2012-03-11 536.254004
2012-03-18 576.161993
2012-03-25 600.990001
2012-04-01 609.698003
2012-04-08 626.484993
2012-04-15 623.773999
2012-04-22 591.718002
2012-04-29 590.536005
2012-05-06 579.831995
2012-05-13 568.814001
2012-05-20 543.593996
2012-05-27 563.283995
2012-06-03 572.539994
2012-06-10 570.124002
2012-06-17 573.029991
2012-06-24 583.739993
2012-07-01 574.070004
2012-07-08 601.937489
2012-07-15 606.080008
2012-07-22 607.746011
2012-07-29 587.951999
2012-08-05 607.217999
2012-08-12 621.150003
2012-08-19 635.394003
2012-08-26 663.185999
2012-09-02 670.611995
2012-09-09 675.477503
2012-09-16 673.476007
...
2016-08-07 105.934003
2016-08-14 108.258000
2016-08-21 109.304001
2016-08-28 107.980000
2016-09-04 106.676001
2016-09-11 106.177498
2016-09-18 111.129999
2016-09-25 113.606001
2016-10-02 113.029999
2016-10-09 113.303999
2016-10-16 116.860000
2016-10-23 117.160001
2016-10-30 115.938000
2016-11-06 111.057999
2016-11-13 109.714000
2016-11-20 108.563999
2016-11-27 111.637503
2016-12-04 110.587999
2016-12-11 111.231999
2016-12-18 115.094002
2016-12-25 116.691998
2017-01-01 116.642502
2017-01-08 116.672501
2017-01-15 119.228000
2017-01-22 119.942499
2017-01-29 121.164000
2017-02-05 125.867999
2017-02-12 131.679996
2017-02-19 134.978000
2017-02-26 136.904999
Freq: W-SUN, Name: Close, dtype: float64
Resampling мощный инструмент при работе с временными рядами (time series), помогающий переформировать выборку так, как удобно вам. Метод resample первым аргументом принимает строку rule. Все доступные значения можно найти в документации.
Визуализация данных в pandas
Для визуального анализа данных, pandas использует библиотеку matplotlib. Продемонстрирую простейший способ визуализации в pandas на примере с акциями Apple.
Берём цену закрытия в промежутке между 2012 и 2017.
>>> import matplotlib.pyplot as plt
>>> new_sample_df = df.loc['2012-Feb':'2017-Feb', ['Close']]
>>> new_sample_df.plot()
>>> plt.show()
И видим вот такую картину:
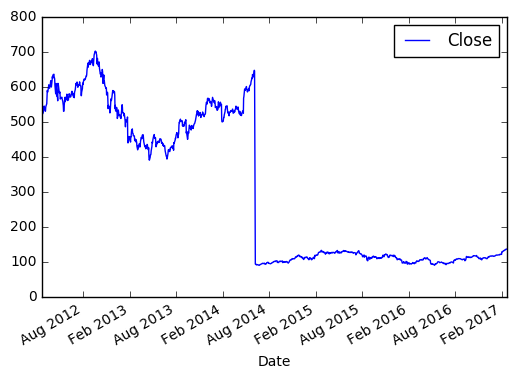
По оси X, если не задано явно, всегда будет индекс. По оси Y в нашем случае цена закрытия. Если внимательно посмотреть, то в 2014 году цена на акцию резко упала, это событие было связано с тем, что Apple проводила сплит 7 к 1. Так мало кода и уже более-менее наглядный анализ 
Эта заметка демонстрирует лишь малую часть возможностей pandas. Со своей стороны я постараюсь по мере своих сил обновлять и дополнять её.
Полезные ссылки
- pandas cheatsheet
- Официальная документация pandas
- Почему Python
- Python Data Science Handbook
💌 Присоединяйтесь к рассылке
Понравился контент? Пожалуйста, подпишись на рассылку.
#статьи
- 23 ноя 2022
-

0
Разбираемся в том, как работает библиотека Pandas и проводим первый анализ данных.
Иллюстрация: Катя Павловская для Skillbox Media

Изучает Python, его библиотеки и занимается анализом данных. Любит путешествовать в горах.
Python используют для анализа данных и машинного обучения, подключая к нему различные библиотеки: Pandas, Matplotlib, NumPy, TensorFlow и другие. Каждая из них используется для решения конкретных задач.
Сегодня мы поговорим про Pandas: узнаем, для чего нужна эта библиотека, как импортировать её в Python, а также проанализируем свой первый датасет и выясним, в какой стране самый быстрый и самый медленный интернет.
Pandas — главная библиотека в Python для работы с данными. Её активно используют аналитики данных и дата-сайентисты. Библиотека была создана в 2008 году компанией AQR Capital, а в 2009 году она стала проектом с открытым исходным кодом с поддержкой большого комьюнити.
Вот для каких задач используют библиотеку:
Аналитика данных: продуктовая, маркетинговая и другая. Работа с любыми данными требует анализа и подготовки: необходимо удалить или заполнить пропуски, отфильтровать, отсортировать или каким-то образом изменить данные. Pandas в Python позволяет быстро выполнить все эти действия, а в большинстве случаев ещё и автоматизировать их.
Data science и работа с большими данными. Pandas помогает подготовить и провести первичный анализ данных, чтобы потом использовать их в машинном или глубоком обучении.
Статистика. Библиотека поддерживает основные статистические методы, которые необходимы для работы с данными. Например, расчёт средних значений, их распределения по квантилям и другие.
Для анализа данных и машинного обучения обычно используются особые инструменты: Google Colab или Jupyter Notebook. Это специализированные IDE, позволяющие работать с данными пошагово и итеративно, без необходимости создавать полноценное приложение.
В этой статье мы посмотрим на Google Colab, облачное решение для работы с данными, которое можно запустить в браузере на любом устройстве: десктопе, ноутбуке, планшете или даже смартфоне.
Каждая строчка кода на скриншоте — это одно действие, результат которого Google Colab и Jupyter Notebook сразу демонстрируют пользователю. Это удобно в задачах, связанных с аналитикой и data science.
Устанавливать Pandas при работе с Jupyter Notebook или Colab не требуется. Это стандартная библиотека, которая уже будет доступна сразу после их запуска. Останется только импортировать её в ваш код.
import pandas as pd
pd — общепринятое сокращение для Pandas в коде. Оно встречается в книгах, статьях и учебных курсах. Используйте его и в своих программах, чтобы не писать длинное pandas.
Данные в Pandas представлены в двух видах: Series и DataFrame. Разберёмся с каждым из них.
Series — это объект, который похож на одномерный массив и может содержать любые типы данных. Проще всего представить его как столбец таблицы, с последовательностью каких-либо значений, у каждого из которых есть индекс — номер строки.
Создадим простой Series:
import pandas as pd #Импортируем библиотеку Pandas. series_example = pd.Series([4, 7, -5, 3]) #Создаём объект Series, содержащий числа. series_example #Выводим объект на экран.
Теперь выведем его на экран:

Series отображается в виде таблицы с индексами элементов в первом столбце и значениями во втором.
DataFrame — основной тип данных в Pandas, вокруг которого строится вся работа. Его можно представить в виде обычной таблицы с любым количеством столбцов и строк. Внутри ячеек такой «таблицы» могут быть данные самого разного типа: числовые, булевы, строковые и так далее.
У DataFrame есть и индексы строк, и индексы столбцов. Это позволяет удобно сортировать и фильтровать данные, а также быстро находить нужные ячейки.
Создадим простой DataFrame с помощью словаря и посмотрим на его отображение:
import pandas as pd #Импортируем библиотеку Pandas. city = {'Город': ['Москва', 'Санкт-Петербург', 'Новосибирск', 'Екатеринбург'], 'Год основания': [1147, 1703, 1893, 1723], 'Население': [11.9, 4.9, 1.5, 1.4]} #Создаём словарь с нужной информацией о городах. df = pd.DataFrame(city) #Превращаем словарь в DataFrame, используя стандартный метод библиотеки. df #Выводим DataFrame на экран.
Посмотрим на результат:
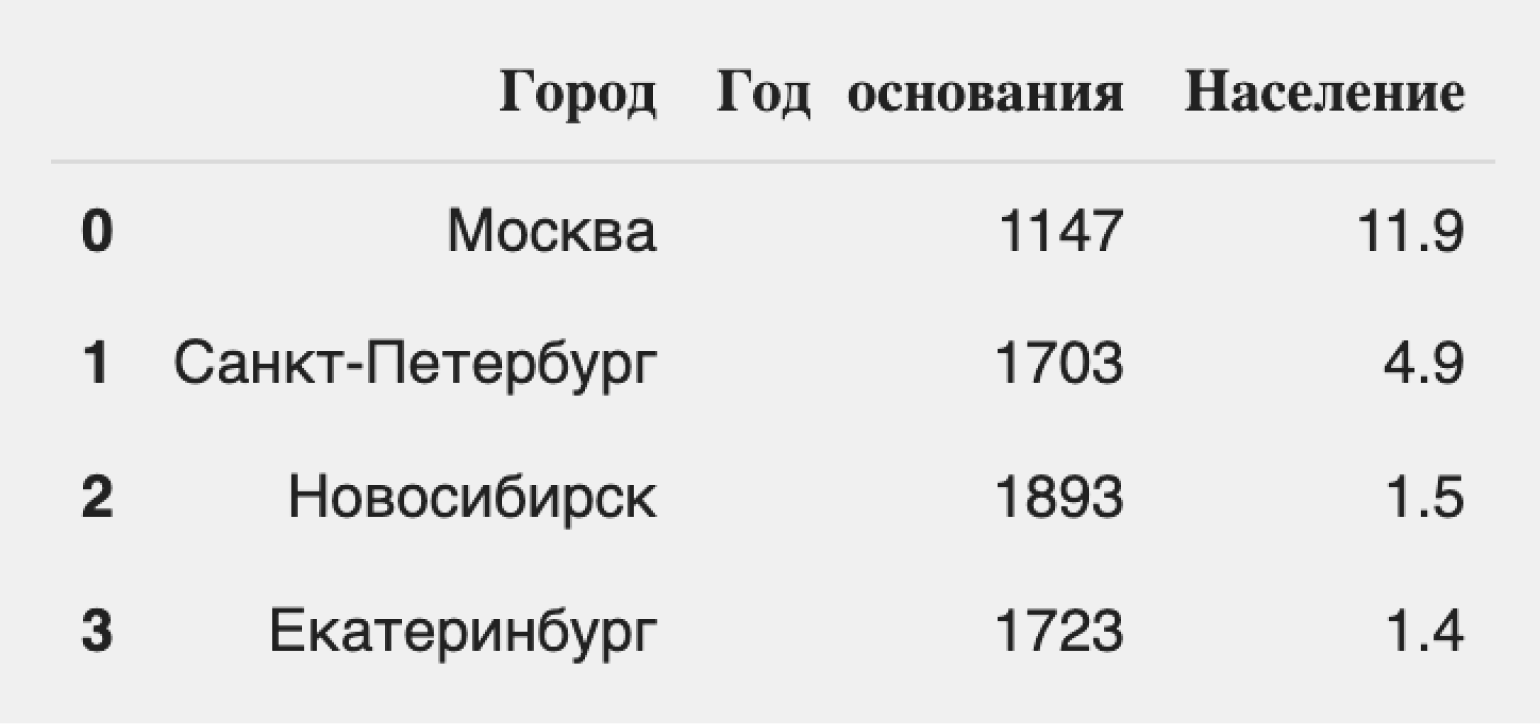
Мы видим таблицу, строки которой имеют индексы от 0 до 3, а «индексы» столбцов соответствуют их названиям. Легко заметить, что DataFrame состоит из трёх Series: «Город», «Год основания» и «Население». Оба типа индексов можно использовать для навигации по данным.
Pandas позволяет импортировать данные разными способами. Например, прочесть их из словаря, списка или кортежа. Самый популярный способ — это работа с файлами .csv, которые часто применяются в анализе данных. Для импорта используют команду pd.read_csv().
read_csv имеет несколько параметров для управления импортом:
- sep — позволяет явно указать разделитель, который используется в импортируемом файле. По умолчанию значение равно ,, что соответствует разделителю данных в файлах формата .csv. Этот параметр полезен при нестандартных разделителях в исходном файле, например табуляции или точки с запятой;
- dtype — позволяет явно указать на тип данных в столбцах. Полезно в тех случаях, когда формат данных автоматически определился неверно. Например, даты часто импортируются в виде строковых переменных, хотя для них существует отдельный тип.
Подробно параметры, позволяющие настроить импорт, описаны в документации.
Давайте импортируем датасет с информацией о скорости мобильного и стационарного интернета в отдельных странах. Готовый датасет скачиваем с Kaggle. Параметры для read_csv не указываем, так как наши данные уже подготовлены для анализа.
df = pd.read_csv('/content/Internet Speed 2022.csv')
Теперь посмотрим на получившийся датафрейм:
df
Важно! При работе в Google Colab или Jupyter Notebook для вывода DataFrame или Series на экран не используется команда print. Pandas умеет показывать данные и без неё. Если же написать print(df), то табличная вёрстка потеряется. Попробуйте вывести данные двумя способами и посмотрите на результат.
На экране появилась вот такая таблица:
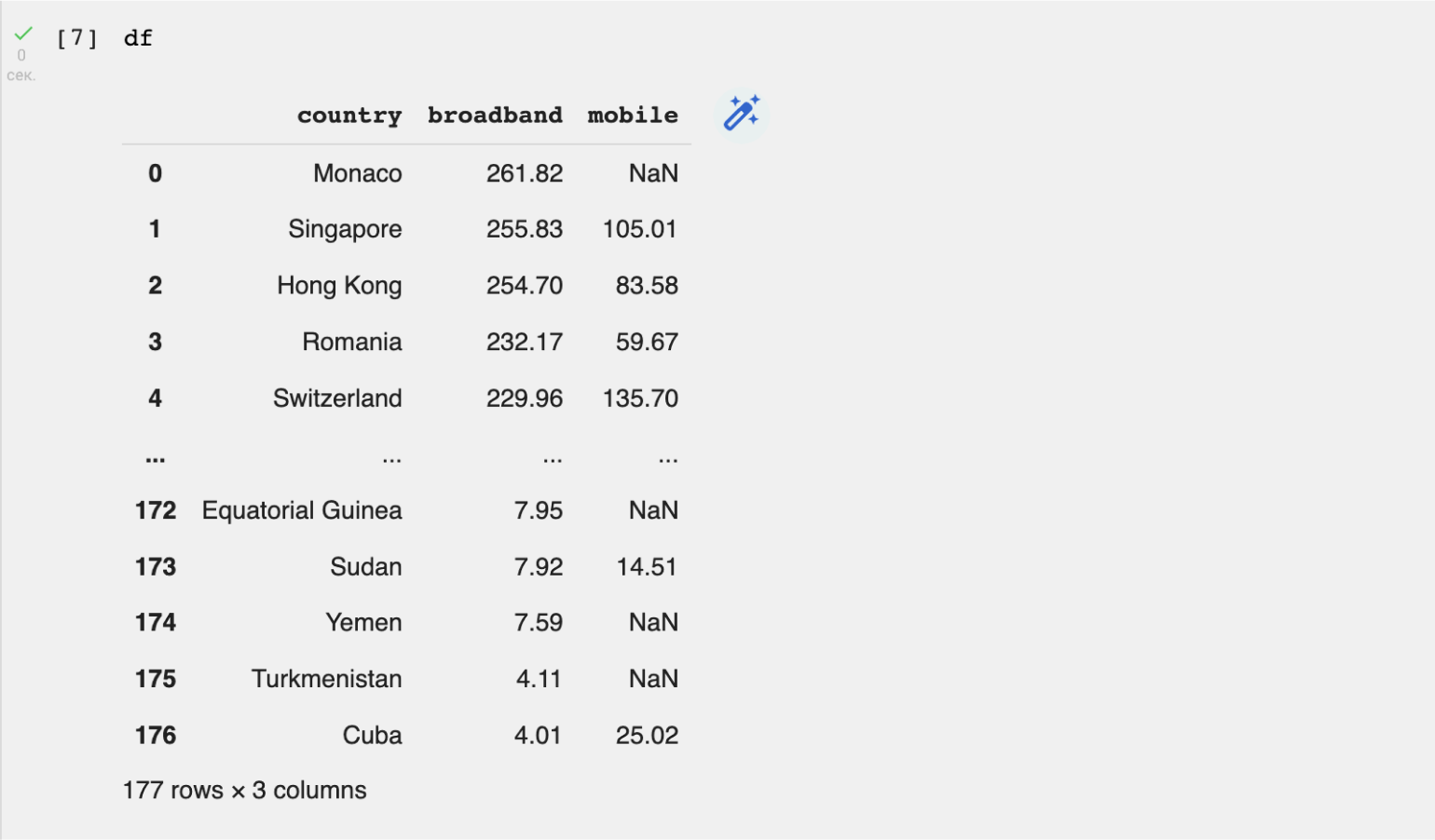
В верхней части таблицы мы видим названия столбцов: country (страна), broadband (средняя скорость интернета) и mobile (средняя скорость мобильного интернета). Слева указаны индексы — от 0 до 176. То есть всего у нас 177 строк. В нижней части таблицы Pandas отображает и эту информацию.
Выводить таблицу полностью необязательно. Для первого знакомства с данными достаточно показать пять первых или пять последних строк. Сделать это можно с помощью df.head() или df.tail() соответственно. В скобках можно указать число строк, которое требуется указать. По умолчанию параметр равен 5.
df.head()
Результат:

Так намного удобнее. Мы можем сразу увидеть названия столбцов и тип данных в столбцах. Также в некоторых ячейках мы видим значение NaN — к нему мы вернёмся позже.
Теперь нам надо изучить импортированные данные. Действовать будем пошагово.
Шаг 1. Проверяем тип данных в таблице. Это поможет понять, в каком виде представлена информация в датасете — а иногда и найти аномалии. Например, даты могут быть сохранены в виде строк, что неудобно для последующего анализа. Проверить это можно с помощью стандартного метода:
df.dtypes
На экране появится таблица с обозначением типа данных в каждом столбце:

Что мы видим:
- столбец country представляет собой тип object. Это тип данных для строковых и смешанных значений;
- столбцы broadband и mobile имеют тип данных float, то есть относятся к числам с плавающей точкой.
Шаг 2. Быстро оцениваем данные и делаем предварительные выводы. Сделать это можно очень просто: для этого в Pandas существует специальный метод describe(). Он показывает среднее со стандартным отклонением, максимальные, минимальные значения переменных и их разделение по квантилям.
Посмотрим на этот метод в деле:
df.describe()
Результат:

Пройдёмся по каждой строчке:
- count — это количество заполненных строк в каждом столбце. Мы видим, что в столбце с данными о скорости мобильного интернета есть пропуски.
- mean — среднее значение скорости обычного и мобильного интернета. Уже можно сделать вывод, что мобильный интернет в большинстве стран медленнее, чем кабельный.
- std — стандартное отклонение. Важный статистический показатель, показывающий разброс значений.
- min и max — минимальное и максимальное значение.
- 25%, 50% и 75% — значения скорости интернета по процентилям. Если не углубляться в статистику, то процентиль — это число, которое показывает распределение значений в выборке. Например, в выборке с мобильным интернетом процентиль 25% показывает, что 25% от всех значений скорости интернета меньше, чем 24,4.
Обратите внимание, что этот метод работает только для чисел. Информация для столбца с названиями стран отсутствует.
Какой вывод делаем? Проводной интернет в большинстве стран работает быстрее, чем мобильный. При этом скорость проводного интернета в 75% случаев не превышает 110 Мбит/сек, а мобильного — 69 Мбит/сек.
Шаг 3. Сортируем и фильтруем записи. В нашем датафрейме данные уже отсортированы от большего к меньшему по скорости проводного интернета. Попробуем найти страну с наилучшим мобильным интернетом. Для этого используем стандартный метод sort_values, который принимает два параметра:
- название столбца, по которому происходит сортировка, — обязательно должно быть заключено в одинарные или двойные кавычки;
- параметр ascending= — указывает на тип сортировки. Если мы хотим отсортировать значения от большего к меньшему, то параметру присваиваем False. Для сортировки от меньшего к большему используем True.
Перейдём к коду:
df.sort_values('mobile', ascending=False).head()
Результат:
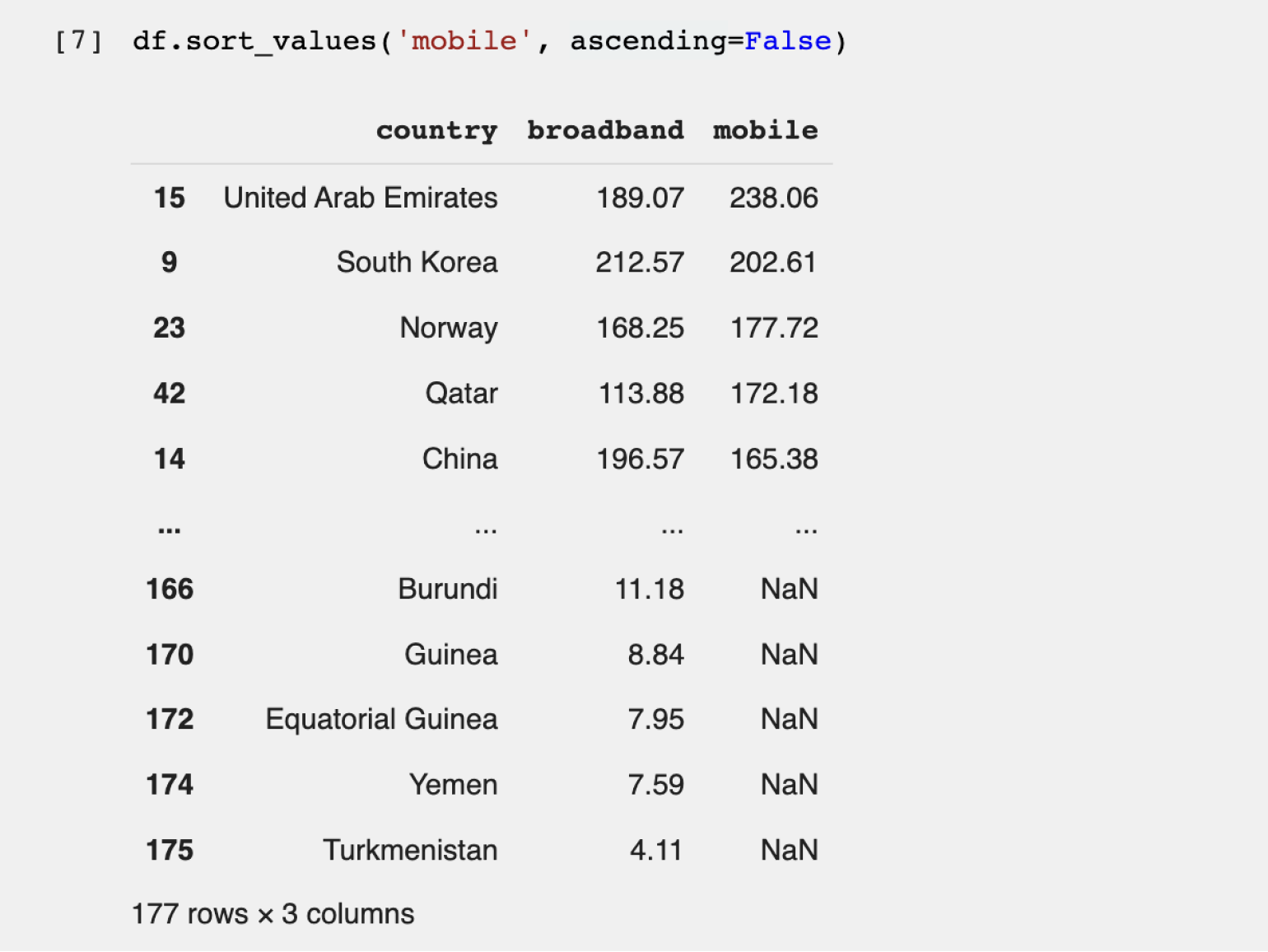
Теперь рейтинг стран другой — пятёрка лидеров поменялась (потому что мы отсортировали данные по другому значению). Мы выяснили, что самый быстрый мобильный интернет в ОАЭ.
Но есть нюанс. Если вернуться к первоначальной таблице, отсортированной по скорости проводного интернета, можно заметить, что у лидера — Монако — во втором столбце написано NaN. NaN в Python указывает на отсутствие данных. Поэтому мы не знаем скорость мобильного интернета в Монако из этого датасета и не можем сделать однозначный вывод о лидерах в мире мобильной связи.
Попробуем отфильтровать значения, убрав страны с неизвестной скоростью мобильного интернета, и посмотрим на худшие по показателю страны (если оставить NaN, он будет засорять «дно» таблицы и увидеть реальные значения по самому медленному мобильному интернету будет сложновато).
В Pandas существуют различные способы фильтрации для удаления NaN. Мы воспользуемся методом dropna(), который удаляет все строки с пропусками. Важно, что удаляется полностью строка, содержащая NaN, а не только ячейки с пропущенными значениями в столбце с пропусками.
df.dropna()
Результат:
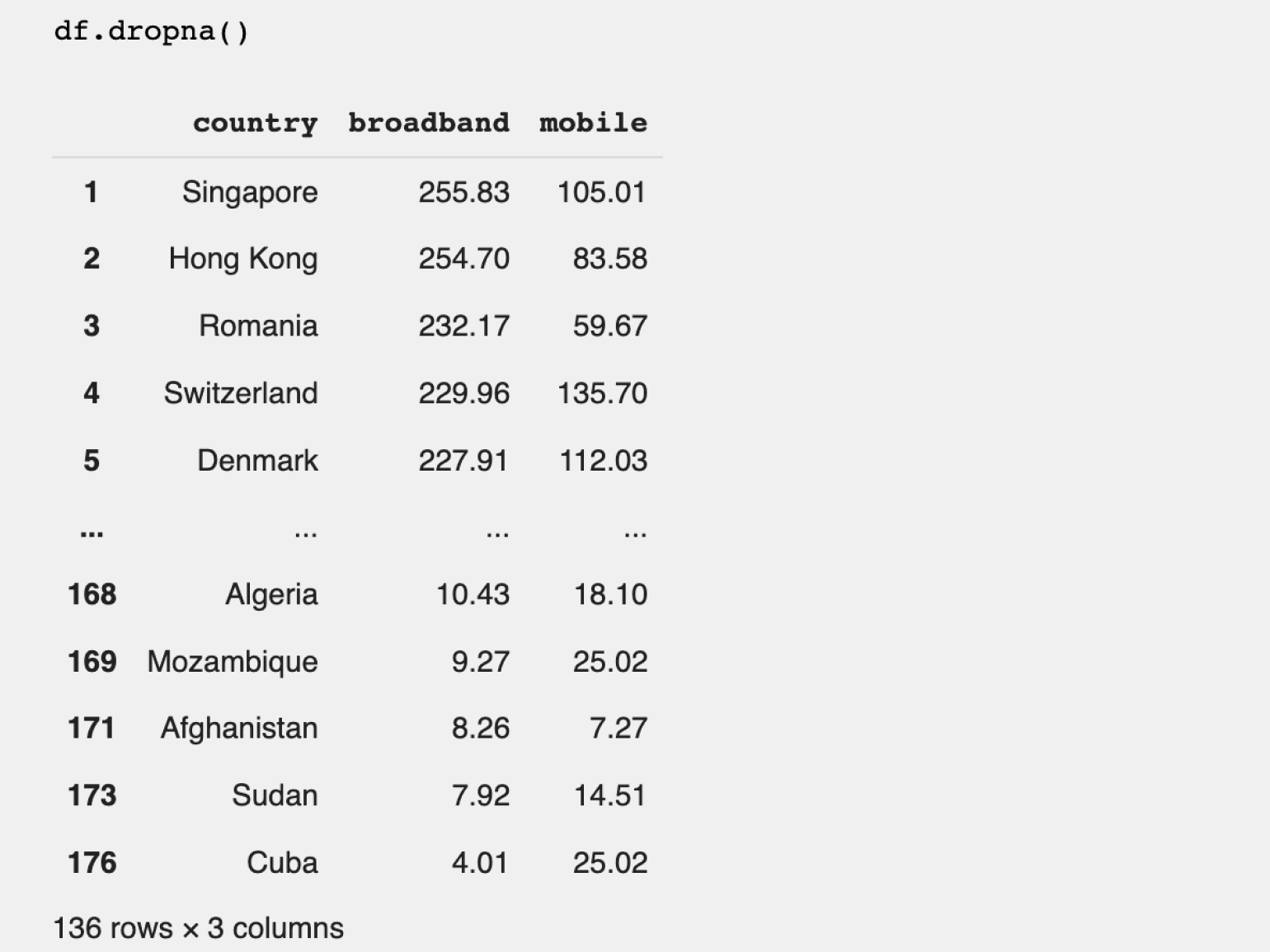
Количество строк в датафрейме при удалении пустых данных уменьшилось до 136. Если вернуться ко второму шагу, то можно увидеть, что это соответствует количеству заполненных строк в столбце mobile в начальном датафрейме.
Сохраним результат в новый датафрейм и назовём его df_without_nan. Изначальный DataFrame стараемся не менять, так как он ещё может нам понадобиться.
df_without_nan = df.dropna()
Теперь отсортируем полученные результаты по столбцу mobile от меньшего к большему и посмотрим на страну с самым медленным мобильным интернетом:
df_without_nan.sort_values('mobile', ascending=True)
Результат:
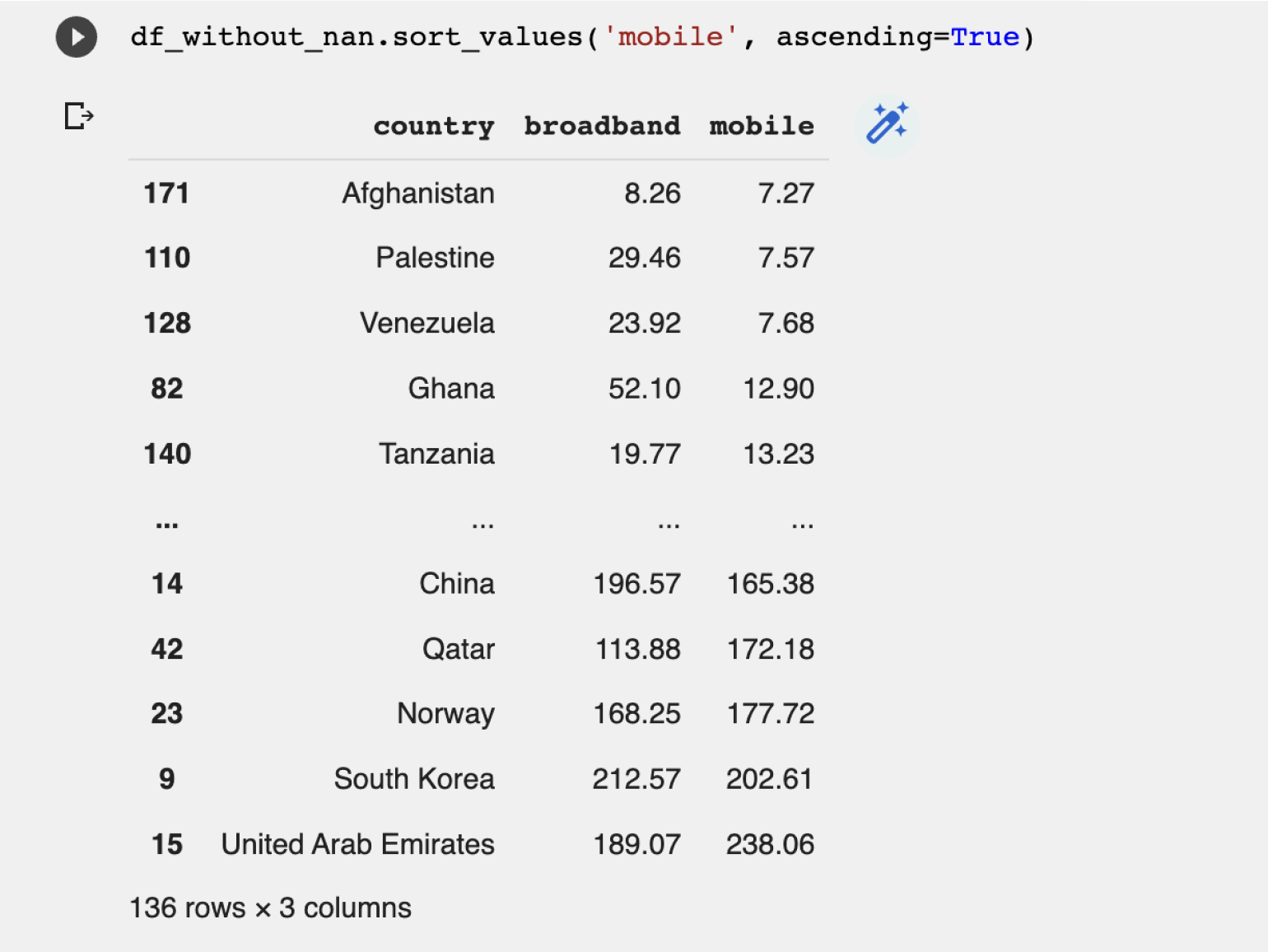
Худший мобильный интернет в Афганистане с небольшим отставанием от Палестины и Венесуэлы.
Pandas в Python — мощная библиотека для анализа данных. В этой статье мы прошли по базовым операциям. Подробнее про работу библиотеки можно узнать в документации. Углубиться в работу с библиотекой можно благодаря специализированным книгам:
- «Изучаем pandas. Высокопроизводительная обработка и анализ данных в Python» Майкла Хейдта и Артёма Груздева;
- «Thinking in Pandas: How to Use the Python Data Analysis Library the Right Way», Hannah Stepanek;
- «Hands-On Data Analysis with Pandas: Efficiently perform data collection, wrangling, analysis, and visualization using Python», Stefanie Molin.

Научитесь: Профессия Python-разработчик
Узнать больше
Python Pandas – Введение
Pandas – это библиотека Python с открытым исходным кодом, предоставляющая высокопроизводительный инструмент для обработки и анализа данных с использованием его мощных структур данных. Название Pandas происходит от слова Panel Data – эконометрика из многомерных данных.
В 2008 году разработчик Уэс МакКинни начал разработку панд, когда им нужен высокопроизводительный, гибкий инструмент для анализа данных.
До Pandas Python в основном использовался для сбора и подготовки данных. Это имело очень небольшой вклад в анализ данных. Панды решили эту проблему. Используя Pandas, мы можем выполнить пять типичных шагов по обработке и анализу данных, независимо от происхождения данных – загрузить, подготовить, манипулировать, моделировать и анализировать.
Python с Pandas используется в широком спектре областей, включая академические и коммерческие области, включая финансы, экономику, статистику, аналитику и т. Д.
Ключевые особенности панд
- Быстрый и эффективный объект DataFrame с индивидуальной индексацией по умолчанию.
- Инструменты для загрузки данных в объекты данных в памяти из разных форматов файлов.
- Выравнивание данных и интегрированная обработка отсутствующих данных.
- Изменение формы и поворот наборов дат.
- Метка нарезки, индексация и подмножество больших наборов данных.
- Столбцы из структуры данных могут быть удалены или вставлены.
- Группировка по данным для агрегации и преобразований.
- Высокая производительность слияния и объединения данных.
- Функциональность временных рядов.
Python Pandas – настройка среды
Стандартный дистрибутив Python не поставляется в комплекте с модулем Pandas. Облегченной альтернативой является установка NumPy с помощью популярного установщика пакетов Python, pip.
pip install pandas
Если вы устанавливаете пакет Anaconda Python, Pandas будет установлен по умолчанию со следующим:
Windows
-
Anaconda (из https://www.continuum.io ) – это бесплатный дистрибутив Python для стека SciPy. Он также доступен для Linux и Mac.
-
Canopy ( https://www.enthought.com/products/canopy/ ) доступен как для бесплатного, так и для коммерческого распространения с полным стеком SciPy для Windows, Linux и Mac.
-
Python (x, y) – это бесплатный дистрибутив Python со стеком SciPy и IDE Spyder для ОС Windows. (Загружается с http://python-xy.github.io/ )
Anaconda (из https://www.continuum.io ) – это бесплатный дистрибутив Python для стека SciPy. Он также доступен для Linux и Mac.
Canopy ( https://www.enthought.com/products/canopy/ ) доступен как для бесплатного, так и для коммерческого распространения с полным стеком SciPy для Windows, Linux и Mac.
Python (x, y) – это бесплатный дистрибутив Python со стеком SciPy и IDE Spyder для ОС Windows. (Загружается с http://python-xy.github.io/ )
Linux
Менеджеры пакетов соответствующих дистрибутивов Linux используются для установки одного или нескольких пакетов в стек SciPy.
Для пользователей Ubuntu
sudo apt-get install python-numpy python-scipy python-matplotlibipythonipythonnotebook python-pandas python-sympy python-nose
Для пользователей Fedora
sudo yum install numpyscipy python-matplotlibipython python-pandas sympy python-nose atlas-devel
Введение в структуры данных
Панды имеют дело со следующими тремя структурами данных –
- Серии
- DataFrame
- панель
Эти структуры данных построены поверх массива Numpy, что означает, что они быстрые.
Размер и описание
Лучший способ думать об этих структурах данных состоит в том, что многомерная структура данных является контейнером ее низкоразмерной структуры данных. Например, DataFrame – это контейнер Series, Panel – это контейнер DataFrame.
| Структура данных | Размеры | Описание |
|---|---|---|
| Серии | 1 | 1D помечен однородный массив, размер не изменяемый. |
| Фреймы данных | 2 | Общая двумерная помеченная таблично-изменяемая структура с потенциально разнородными столбцами. |
| панель | 3 | Общий 3D помеченный, изменяемый по размеру массив. |
Построение и обработка двух или более многомерных массивов – это утомительная задача, на которую ложится нагрузка на пользователя, чтобы учитывать ориентацию набора данных при написании функций. Но при использовании структур данных Pandas умственные усилия пользователя снижаются.
Например, для табличных данных (DataFrame) более семантически полезно думать об индексе (строках) и столбцах, а не оси 0 и оси 1.
переменчивость
Все структуры данных Pandas являются изменяемыми по значению (могут быть изменены) и, кроме Series, все могут изменяться по размеру. Серия неизменна по размеру.
Примечание. DataFrame широко используется и является одной из наиболее важных структур данных. Панель используется гораздо меньше.
Серии
Серия представляет собой одномерную массивоподобную структуру с однородными данными. Например, следующий ряд представляет собой набор целых чисел 10, 23, 56,…
| 10 | 23 | 56 | 17 | 52 | 61 | 73 | 90 | 26 | 72 |
Ключевые моменты
- Однородные данные
- Размер неизменный
- Значения изменяемых данных
DataFrame
DataFrame – это двумерный массив с разнородными данными. Например,
| название | Возраст | Пол | Рейтинг |
|---|---|---|---|
| Стив | 32 | мужчина | 3,45 |
| Lia | 28 | женский | 4,6 |
| Vin | 45 | мужчина | 3,9 |
| Кэти | 38 | женский | 2,78 |
В таблице представлены данные отдела продаж организации с их общей оценкой эффективности. Данные представлены в строках и столбцах. Каждый столбец представляет атрибут, а каждая строка представляет человека.
Тип данных столбцов
Типы данных четырех столбцов следующие:
| колонка | Тип |
|---|---|
| название | строка |
| Возраст | целое число |
| Пол | строка |
| Рейтинг | терка |
Ключевые моменты
- Гетерогенные данные
- Размер изменчивый
- Изменяемые данные
панель
Панель представляет собой трехмерную структуру данных с разнородными данными. Трудно представить панель в графическом представлении. Но панель может быть проиллюстрирована как контейнер DataFrame.
Ключевые моменты
- Гетерогенные данные
- Размер изменчивый
- Изменяемые данные
Питон Панды – Серия
Ряды – это одномерный помеченный массив, способный содержать данные любого типа (целочисленные, строковые, с плавающей точкой, объекты Python и т. Д.). Метки осей в совокупности называются индексами.
pandas.Series
Серия панд может быть создана с помощью следующего конструктора –
pandas.Series( data, index, dtype, copy)
Параметры конструктора следующие:
| Sr.No | Параметр и описание |
|---|---|
| 1 |
данные данные принимают различные формы, такие как ndarray, list, constants |
| 2 |
индекс Значения индекса должны быть уникальными и иметь хешируемую длину, равную длине данных. Значение по умолчанию np.arrange (n), если индекс не передан. |
| 3 |
DTYPE dtype для типа данных. Если None, тип данных будет выведен |
| 4 |
копия Скопируйте данные. По умолчанию False |
данные
данные принимают различные формы, такие как ndarray, list, constants
индекс
Значения индекса должны быть уникальными и иметь хешируемую длину, равную длине данных. Значение по умолчанию np.arrange (n), если индекс не передан.
DTYPE
dtype для типа данных. Если None, тип данных будет выведен
копия
Скопируйте данные. По умолчанию False
Серия может быть создана с использованием различных входных данных, таких как –
- массив
- Dict
- Скалярное значение или константа
Создать пустую серию
Базовая серия, которую можно создать, – это Пустая серия.
пример
Live Demo
#import the pandas library and aliasing as pd import pandas as pd s = pd.Series() print s
Его вывод выглядит следующим образом –
Series([], dtype: float64)
Создать серию из ndarray
Если данные являются ndarray, то передаваемый индекс должен иметь одинаковую длину. Если индекс не передается, то по умолчанию индексом будет диапазон (n), где n – длина массива, то есть [0,1,2,3…. Диапазон (LEN (массив)) – 1].
Пример 1
Live Demo
#import the pandas library and aliasing as pd import pandas as pd import numpy as np data = np.array(['a','b','c','d']) s = pd.Series(data) print s
Его вывод выглядит следующим образом –
0 a 1 b 2 c 3 d dtype: object
Мы не передали никакого индекса, поэтому по умолчанию он назначил индексы в диапазоне от 0 до len (data) -1 , то есть от 0 до 3.
Пример 2
Live Demo
#import the pandas library and aliasing as pd import pandas as pd import numpy as np data = np.array(['a','b','c','d']) s = pd.Series(data,index=[100,101,102,103]) print s
Его вывод выглядит следующим образом –
100 a 101 b 102 c 103 d dtype: object
Мы передали значения индекса здесь. Теперь мы можем видеть настроенные индексированные значения в выводе.
Создать серию из dict
В качестве входных данных можно передать dict, и если индекс не указан, то ключи словаря берутся в отсортированном порядке для построения индекса. Если индекс передан, значения в данных, соответствующие меткам в индексе, будут извлечены.
Пример 1
Live Demo
#import the pandas library and aliasing as pd import pandas as pd import numpy as np data = {'a' : 0., 'b' : 1., 'c' : 2.} s = pd.Series(data) print s
Его вывод выглядит следующим образом –
a 0.0 b 1.0 c 2.0 dtype: float64
Наблюдать – словарные ключи используются для построения индекса.
Пример 2
Live Demo
#import the pandas library and aliasing as pd import pandas as pd import numpy as np data = {'a' : 0., 'b' : 1., 'c' : 2.} s = pd.Series(data,index=['b','c','d','a']) print s
Его вывод выглядит следующим образом –
b 1.0 c 2.0 d NaN a 0.0 dtype: float64
Наблюдать – порядок индексов сохраняется, а недостающий элемент заполняется NaN (не числом).
Создать серию из Скалара
Если данные являются скалярным значением, необходимо указать индекс. Значение будет повторяться, чтобы соответствовать длине индекса
Live Demo
#import the pandas library and aliasing as pd import pandas as pd import numpy as np s = pd.Series(5, index=[0, 1, 2, 3]) print s
Его вывод выглядит следующим образом –
0 5 1 5 2 5 3 5 dtype: int64
Доступ к данным из серии с позицией
Доступ к данным в серии можно получить аналогично данным в ndarray.
Пример 1
Получить первый элемент. Как мы уже знаем, отсчет для массива начинается с нуля, что означает, что первый элемент хранится в нулевой позиции и так далее.
Live Demo
import pandas as pd s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e']) #retrieve the first element print s[0]
Его вывод выглядит следующим образом –
1
Пример 2
Получить первые три элемента в серии. Если перед ним вставлен знак:, будут извлечены все элементы этого индекса. Если используются два параметра (с: между ними), элементы между двумя индексами (не включая индекс остановки)
Live Demo
import pandas as pd s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e']) #retrieve the first three element print s[:3]
Его вывод выглядит следующим образом –
a 1 b 2 c 3 dtype: int64
Пример 3
Получить последние три элемента.
Live Demo
import pandas as pd s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e']) #retrieve the last three element print s[-3:]
Его вывод выглядит следующим образом –
c 3 d 4 e 5 dtype: int64
Получить данные, используя метку (индекс)
Серия похожа на диктат фиксированного размера, в котором вы можете получать и устанавливать значения по метке индекса.
Пример 1
Получить один элемент, используя значение метки индекса.
Live Demo
import pandas as pd s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e']) #retrieve a single element print s['a']
Его вывод выглядит следующим образом –
1
Пример 2
Получить несколько элементов, используя список значений меток индекса.
Live Demo
import pandas as pd s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e']) #retrieve multiple elements print s[['a','c','d']]
Его вывод выглядит следующим образом –
a 1 c 3 d 4 dtype: int64
Пример 3
Если метка не содержится, возникает исключение.
import pandas as pd s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e']) #retrieve multiple elements print s['f']
Его вывод выглядит следующим образом –
… KeyError: 'f'
Python Pandas – DataFrame
Фрейм данных – это двумерная структура данных, т. Е. Данные выстраиваются в виде таблиц по строкам и столбцам.
Особенности DataFrame
- Потенциально столбцы бывают разных типов
- Размер – изменчивый
- Помеченные оси (строки и столбцы)
- Может выполнять арифметические операции над строками и столбцами
Состав
Давайте предположим, что мы создаем фрейм данных с данными ученика.
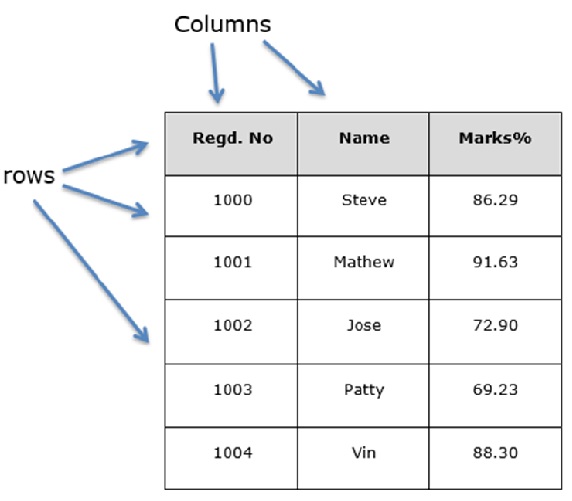
Вы можете думать об этом как о таблице SQL или представлении данных электронной таблицы.
pandas.DataFrame
DataFrame pandas может быть создан с помощью следующего конструктора –
pandas.DataFrame( data, index, columns, dtype, copy)
Параметры конструктора следующие:
| Sr.No | Параметр и описание |
|---|---|
| 1 |
данные Данные могут принимать различные формы, такие как ndarray, series, map, lists, dict, constants, а также другой DataFrame. |
| 2 |
индекс Для меток строк индекс, который будет использоваться для результирующего кадра, является необязательным значением по умолчанию np.arrange (n), если индекс не передан. |
| 3 |
столбцы Для меток столбцов необязательный синтаксис по умолчанию – np.arrange (n). Это верно только в том случае, если индекс не передан. |
| 4 |
DTYPE Тип данных каждого столбца. |
| 5 |
копия Эта команда (или что-то еще) используется для копирования данных, если по умолчанию установлено значение False. |
данные
Данные могут принимать различные формы, такие как ndarray, series, map, lists, dict, constants, а также другой DataFrame.
индекс
Для меток строк индекс, который будет использоваться для результирующего кадра, является необязательным значением по умолчанию np.arrange (n), если индекс не передан.
столбцы
Для меток столбцов необязательный синтаксис по умолчанию – np.arrange (n). Это верно только в том случае, если индекс не передан.
DTYPE
Тип данных каждого столбца.
копия
Эта команда (или что-то еще) используется для копирования данных, если по умолчанию установлено значение False.
Создать DataFrame
DataFrame Pandas может быть создан с использованием различных входных данных, таких как –
- Списки
- ДИКТ
- Серии
- Numpy ndarrays
- Другой DataFrame
В последующих разделах этой главы мы увидим, как создать DataFrame, используя эти входные данные.
Создать пустой фрейм данных
Основной DataFrame, который может быть создан, является Пустым DataFrame.
пример
Live Demo
#import the pandas library and aliasing as pd import pandas as pd df = pd.DataFrame() print df
Его вывод выглядит следующим образом –
Empty DataFrame Columns: [] Index: []
Создать DataFrame из списков
DataFrame может быть создан с использованием одного списка или списка списков.
Пример 1
Live Demo
import pandas as pd data = [1,2,3,4,5] df = pd.DataFrame(data) print df
Его вывод выглядит следующим образом –
0 0 1 1 2 2 3 3 4 4 5
Пример 2
Live Demo
import pandas as pd data = [['Alex',10],['Bob',12],['Clarke',13]] df = pd.DataFrame(data,columns=['Name','Age']) print df
Его вывод выглядит следующим образом –
Name Age 0 Alex 10 1 Bob 12 2 Clarke 13
Пример 3
Live Demo
import pandas as pd data = [['Alex',10],['Bob',12],['Clarke',13]] df = pd.DataFrame(data,columns=['Name','Age'],dtype=float) print df
Его вывод выглядит следующим образом –
Name Age 0 Alex 10.0 1 Bob 12.0 2 Clarke 13.0
Примечание. Обратите внимание, что параметр dtype изменяет тип столбца Age на число с плавающей запятой.
Создать DataFrame из Dict of ndarrays / Lists
Все ndarrays должны быть одинаковой длины. Если индекс передан, то длина индекса должна быть равна длине массивов.
Если индекс не передается, то по умолчанию индексом будет range (n), где n – длина массива.
Пример 1
Live Demo
import pandas as pd data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]} df = pd.DataFrame(data) print df
Его вывод выглядит следующим образом –
Age Name 0 28 Tom 1 34 Jack 2 29 Steve 3 42 Ricky
Примечание – Соблюдайте значения 0,1,2,3. Они являются индексом по умолчанию, назначаемым каждому с использованием диапазона функций (n).
Пример 2
Теперь давайте создадим индексированный DataFrame с использованием массивов.
Live Demo
import pandas as pd data = {'Name':['Tom', 'Jack', 'Steve', 'Ricky'],'Age':[28,34,29,42]} df = pd.DataFrame(data, index=['rank1','rank2','rank3','rank4']) print df
Его вывод выглядит следующим образом –
Age Name rank1 28 Tom rank2 34 Jack rank3 29 Steve rank4 42 Ricky
Примечание. Обратите внимание, что параметр index присваивает индекс каждой строке.
Создать DataFrame из списка Dicts
Список словарей может быть передан в качестве входных данных для создания DataFrame. Ключи словаря по умолчанию принимаются в качестве имен столбцов.
Пример 1
В следующем примере показано, как создать DataFrame, передав список словарей.
Live Demo
import pandas as pd data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}] df = pd.DataFrame(data) print df
Его вывод выглядит следующим образом –
a b c 0 1 2 NaN 1 5 10 20.0
Примечание. Обратите внимание, что NaN (не число) добавляется в пропущенные области.
Пример 2
В следующем примере показано, как создать DataFrame, передав список словарей и индексы строк.
Live Demo
import pandas as pd data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}] df = pd.DataFrame(data, index=['first', 'second']) print df
Его вывод выглядит следующим образом –
a b c first 1 2 NaN second 5 10 20.0
Пример 3
В следующем примере показано, как создать DataFrame со списком словарей, индексов строк и столбцов.
Live Demo
import pandas as pd data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}] #With two column indices, values same as dictionary keys df1 = pd.DataFrame(data, index=['first', 'second'], columns=['a', 'b']) #With two column indices with one index with other name df2 = pd.DataFrame(data, index=['first', 'second'], columns=['a', 'b1']) print df1 print df2
Его вывод выглядит следующим образом –
#df1 output
a b
first 1 2
second 5 10
#df2 output
a b1
first 1 NaN
second 5 NaN
Примечание. Обратите внимание, что df2 DataFrame создается с индексом столбца, отличным от ключа словаря; таким образом, добавил NaN на месте. Принимая во внимание, что df1 создается с индексами столбцов, такими же, как ключи словаря, поэтому добавляется NaN.
Создать DataFrame из Dict of Series
Словарь серии может быть передан для формирования DataFrame. Результирующий индекс – это объединение всех переданных индексов серии.
пример
Live Demo
import pandas as pd d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']), 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])} df = pd.DataFrame(d) print df
Его вывод выглядит следующим образом –
one two a 1.0 1 b 2.0 2 c 3.0 3 d NaN 4
Примечание. Обратите внимание, что для первой серии нет пропущенной метки d , но в результате к метке d добавляется NaN с NaN.
Теперь давайте разберемся в выборе, добавлении и удалении столбцов с помощью примеров.
Выбор столбца
Мы поймем это, выбрав столбец в DataFrame.
пример
Live Demo
import pandas as pd d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']), 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])} df = pd.DataFrame(d) print df ['one']
Его вывод выглядит следующим образом –
a 1.0 b 2.0 c 3.0 d NaN Name: one, dtype: float64
Добавление столбца
Мы поймем это, добавив новый столбец в существующий фрейм данных.
пример
Live Demo
import pandas as pd d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']), 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])} df = pd.DataFrame(d) # Adding a new column to an existing DataFrame object with column label by passing new series print ("Adding a new column by passing as Series:") df['three']=pd.Series([10,20,30],index=['a','b','c']) print df print ("Adding a new column using the existing columns in DataFrame:") df['four']=df['one']+df['three'] print df
Его вывод выглядит следующим образом –
Adding a new column by passing as Series:
one two three
a 1.0 1 10.0
b 2.0 2 20.0
c 3.0 3 30.0
d NaN 4 NaN
Adding a new column using the existing columns in DataFrame:
one two three four
a 1.0 1 10.0 11.0
b 2.0 2 20.0 22.0
c 3.0 3 30.0 33.0
d NaN 4 NaN NaN
Удаление столбца
Столбцы могут быть удалены или вытолкнуты; давайте возьмем пример, чтобы понять, как.
пример
Live Demo
# Using the previous DataFrame, we will delete a column # using del function import pandas as pd d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']), 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']), 'three' : pd.Series([10,20,30], index=['a','b','c'])} df = pd.DataFrame(d) print ("Our dataframe is:") print df # using del function print ("Deleting the first column using DEL function:") del df['one'] print df # using pop function print ("Deleting another column using POP function:") df.pop('two') print df
Его вывод выглядит следующим образом –
Our dataframe is:
one three two
a 1.0 10.0 1
b 2.0 20.0 2
c 3.0 30.0 3
d NaN NaN 4
Deleting the first column using DEL function:
three two
a 10.0 1
b 20.0 2
c 30.0 3
d NaN 4
Deleting another column using POP function:
three
a 10.0
b 20.0
c 30.0
d NaN
Выбор, добавление и удаление строк
Теперь мы поймем выбор, добавление и удаление строк на примерах. Давайте начнем с концепции отбора.
Выбор по метке
Строки могут быть выбраны путем передачи метки строки в функцию loc .
Live Demo
import pandas as pd d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']), 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])} df = pd.DataFrame(d) print df.loc['b']
Его вывод выглядит следующим образом –
one 2.0 two 2.0 Name: b, dtype: float64
Результатом является серия с метками в качестве имен столбцов DataFrame. И, имя серии – это метка, с которой она извлекается.
Выбор по целому расположению
Строки можно выбирать, передавая целочисленное местоположение в функцию iloc .
Live Demo
import pandas as pd d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']), 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])} df = pd.DataFrame(d) print df.iloc[2]
Его вывод выглядит следующим образом –
one 3.0 two 3.0 Name: c, dtype: float64
Ломтик строк
Несколько строк могут быть выбраны с помощью оператора «:».
Live Demo
import pandas as pd d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']), 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])} df = pd.DataFrame(d) print df[2:4]
Его вывод выглядит следующим образом –
one two c 3.0 3 d NaN 4
Добавление строк
Добавьте новые строки в DataFrame, используя функцию добавления . Эта функция будет добавлять строки в конце.
Live Demo
import pandas as pd df = pd.DataFrame([[1, 2], [3, 4]], columns = ['a','b']) df2 = pd.DataFrame([[5, 6], [7, 8]], columns = ['a','b']) df = df.append(df2) print df
Его вывод выглядит следующим образом –
a b 0 1 2 1 3 4 0 5 6 1 7 8
Удаление строк
Используйте индексную метку для удаления или удаления строк из DataFrame. Если метка дублируется, то несколько строк будут отброшены.
Если вы наблюдаете, в приведенном выше примере метки дублируются. Давайте сбросим метку и увидим, сколько строк будет отброшено.
Live Demo
import pandas as pd df = pd.DataFrame([[1, 2], [3, 4]], columns = ['a','b']) df2 = pd.DataFrame([[5, 6], [7, 8]], columns = ['a','b']) df = df.append(df2) # Drop rows with label 0 df = df.drop(0) print df
Его вывод выглядит следующим образом –
a b 1 3 4 1 7 8
В приведенном выше примере две строки были отброшены, поскольку эти две строки содержат одинаковую метку 0.
Python Pandas – Панель
Панель – это трехмерный контейнер данных. Термин « данные панели» является производным от эконометрики и частично отвечает за название панды – пан (эл) -да (та) -с.
Имена для 3-х осей предназначены для придания некоторого семантического значения описанию операций с данными панели. Они –
-
items – ось 0, каждый элемент соответствует DataFrame, содержащемуся внутри.
-
major_axis – ось 1, это индекс (строки) каждого из фреймов данных.
-
minor_axis – ось 2, это столбцы каждого из DataFrames.
items – ось 0, каждый элемент соответствует DataFrame, содержащемуся внутри.
major_axis – ось 1, это индекс (строки) каждого из фреймов данных.
minor_axis – ось 2, это столбцы каждого из DataFrames.
pandas.Panel ()
Панель может быть создана с помощью следующего конструктора –
pandas.Panel(data, items, major_axis, minor_axis, dtype, copy)
Параметры конструктора следующие:
| параметр | Описание |
|---|---|
| данные | Данные могут принимать различные формы, такие как ndarray, series, map, lists, dict, constants, а также другой DataFrame. |
| Предметы | Ось = 0 |
| major_axis | Ось = 1 |
| minor_axis | Ось = 2 |
| DTYPE | Тип данных каждого столбца |
| копия | Скопируйте данные. По умолчанию, false |
Создать панель
Панель может быть создана несколькими способами, такими как –
- От ndarrays
- Из диктата фреймов данных
Из 3D ndarray
Live Demo
# creating an empty panel import pandas as pd import numpy as np data = np.random.rand(2,4,5) p = pd.Panel(data) print p
Его вывод выглядит следующим образом –
<class 'pandas.core.panel.Panel'> Dimensions: 2 (items) x 4 (major_axis) x 5 (minor_axis) Items axis: 0 to 1 Major_axis axis: 0 to 3 Minor_axis axis: 0 to 4
Примечание. Обратите внимание на размеры пустой панели и приведенной выше панели, все объекты разные.
С точки зрения объектов DataFrame
Live Demo
#creating an empty panel import pandas as pd import numpy as np data = {'Item1' : pd.DataFrame(np.random.randn(4, 3)), 'Item2' : pd.DataFrame(np.random.randn(4, 2))} p = pd.Panel(data) print p
Его вывод выглядит следующим образом –
Dimensions: 2 (items) x 4 (major_axis) x 3 (minor_axis) Items axis: Item1 to Item2 Major_axis axis: 0 to 3 Minor_axis axis: 0 to 2
Создать пустую панель
Пустую панель можно создать с помощью конструктора Panel следующим образом:
Live Demo
#creating an empty panel import pandas as pd p = pd.Panel() print p
Его вывод выглядит следующим образом –
<class 'pandas.core.panel.Panel'> Dimensions: 0 (items) x 0 (major_axis) x 0 (minor_axis) Items axis: None Major_axis axis: None Minor_axis axis: None
Выбор данных из панели
Выберите данные на панели, используя –
- Предметы
- Major_axis
- Minor_axis
Использование предметов
Live Demo
# creating an empty panel import pandas as pd import numpy as np data = {'Item1' : pd.DataFrame(np.random.randn(4, 3)), 'Item2' : pd.DataFrame(np.random.randn(4, 2))} p = pd.Panel(data) print p['Item1']
Его вывод выглядит следующим образом –
0 1 2 0 0.488224 -0.128637 0.930817 1 0.417497 0.896681 0.576657 2 -2.775266 0.571668 0.290082 3 -0.400538 -0.144234 1.110535
У нас есть два предмета, и мы получили item1. В результате получается DataFrame с 4 строками и 3 столбцами, которые являются измерениями Major_axis и Minor_axis .
Использование major_axis
Доступ к данным можно получить с помощью метода panel.major_axis (index) .
Live Demo
# creating an empty panel import pandas as pd import numpy as np data = {'Item1' : pd.DataFrame(np.random.randn(4, 3)), 'Item2' : pd.DataFrame(np.random.randn(4, 2))} p = pd.Panel(data) print p.major_xs(1)
Его вывод выглядит следующим образом –
Item1 Item2 0 0.417497 0.748412 1 0.896681 -0.557322 2 0.576657 NaN
Использование minor_axis
Доступ к данным можно получить с помощью метода panel.minor_axis (index).
Live Demo
# creating an empty panel import pandas as pd import numpy as np data = {'Item1' : pd.DataFrame(np.random.randn(4, 3)), 'Item2' : pd.DataFrame(np.random.randn(4, 2))} p = pd.Panel(data) print p.minor_xs(1)
Его вывод выглядит следующим образом –
Item1 Item2 0 -0.128637 -1.047032 1 0.896681 -0.557322 2 0.571668 0.431953 3 -0.144234 1.302466
Примечание. Обратите внимание на изменения в размерах.
Python Pandas – основная функциональность
К настоящему времени мы узнали о трех структурах данных Pandas и о том, как их создавать. Мы сосредоточимся в основном на объектах DataFrame из-за его важности в обработке данных в реальном времени, а также обсудим несколько других DataStructures.
Основные функции серии
| Sr.No. | Атрибут или метод и описание |
|---|---|
| 1 |
оси Возвращает список меток оси строк |
| 2 |
DTYPE Возвращает dtype объекта. |
| 3 |
пустой Возвращает True, если серия пуста. |
| 4 |
ndim Возвращает количество измерений базовых данных по определению 1. |
| 5 |
размер Возвращает количество элементов в базовых данных. |
| 6 |
ценности Возвращает Серию как ndarray. |
| 7 |
голова() Возвращает первые n строк. |
| 8 |
хвост() Возвращает последние n строк. |
оси
Возвращает список меток оси строк
DTYPE
Возвращает dtype объекта.
пустой
Возвращает True, если серия пуста.
ndim
Возвращает количество измерений базовых данных по определению 1.
размер
Возвращает количество элементов в базовых данных.
ценности
Возвращает Серию как ndarray.
голова()
Возвращает первые n строк.
хвост()
Возвращает последние n строк.
Давайте теперь создадим Серию и посмотрим на все вышеупомянутые операции с табличными атрибутами.
пример
Live Demo
import pandas as pd import numpy as np #Create a series with 100 random numbers s = pd.Series(np.random.randn(4)) print s
Его вывод выглядит следующим образом –
0 0.967853 1 -0.148368 2 -1.395906 3 -1.758394 dtype: float64
оси
Возвращает список меток серии.
Live Demo
import pandas as pd import numpy as np #Create a series with 100 random numbers s = pd.Series(np.random.randn(4)) print ("The axes are:") print s.axes
Его вывод выглядит следующим образом –
The axes are: [RangeIndex(start=0, stop=4, step=1)]
Приведенный выше результат представляет собой компактный формат списка значений от 0 до 5, т. Е. [0,1,2,3,4].
пустой
Возвращает логическое значение, указывающее, является ли объект пустым или нет. Истина означает, что объект пуст.
Live Demo
import pandas as pd import numpy as np #Create a series with 100 random numbers s = pd.Series(np.random.randn(4)) print ("Is the Object empty?") print s.empty
Его вывод выглядит следующим образом –
Is the Object empty? False
ndim
Возвращает количество измерений объекта. По определению, Series – это 1D структура данных, поэтому она возвращает
Live Demo
import pandas as pd import numpy as np #Create a series with 4 random numbers s = pd.Series(np.random.randn(4)) print s print ("The dimensions of the object:") print s.ndim
Его вывод выглядит следующим образом –
0 0.175898 1 0.166197 2 -0.609712 3 -1.377000 dtype: float64 The dimensions of the object: 1
размер
Возвращает размер (длину) серии.
Live Demo
import pandas as pd import numpy as np #Create a series with 4 random numbers s = pd.Series(np.random.randn(2)) print s print ("The size of the object:") print s.size
Его вывод выглядит следующим образом –
0 3.078058 1 -1.207803 dtype: float64 The size of the object: 2
ценности
Возвращает фактические данные в серии в виде массива.
Live Demo
import pandas as pd import numpy as np #Create a series with 4 random numbers s = pd.Series(np.random.randn(4)) print s print ("The actual data series is:") print s.values
Его вывод выглядит следующим образом –
0 1.787373 1 -0.605159 2 0.180477 3 -0.140922 dtype: float64 The actual data series is: [ 1.78737302 -0.60515881 0.18047664 -0.1409218 ]
Голова и хвост
Чтобы просмотреть небольшой образец объекта Series или объекта DataFrame, используйте методы head () и tail ().
head () возвращает первые n строк (соблюдайте значения индекса). Количество отображаемых элементов по умолчанию – пять, но вы можете передать пользовательский номер.
Live Demo
import pandas as pd import numpy as np #Create a series with 4 random numbers s = pd.Series(np.random.randn(4)) print ("The original series is:") print s print ("The first two rows of the data series:") print s.head(2)
Его вывод выглядит следующим образом –
The original series is: 0 0.720876 1 -0.765898 2 0.479221 3 -0.139547 dtype: float64 The first two rows of the data series: 0 0.720876 1 -0.765898 dtype: float64
tail () возвращает последние n строк (соблюдайте значения индекса). Количество отображаемых элементов по умолчанию – пять, но вы можете передать пользовательский номер.
Live Demo
import pandas as pd import numpy as np #Create a series with 4 random numbers s = pd.Series(np.random.randn(4)) print ("The original series is:") print s print ("The last two rows of the data series:") print s.tail(2)
Его вывод выглядит следующим образом –
The original series is: 0 -0.655091 1 -0.881407 2 -0.608592 3 -2.341413 dtype: float64 The last two rows of the data series: 2 -0.608592 3 -2.341413 dtype: float64
Базовая функциональность DataFrame
Давайте теперь поймем, что такое основная функциональность DataFrame. В следующих таблицах перечислены важные атрибуты или методы, которые помогают в базовой функциональности DataFrame.
| Sr.No. | Атрибут или метод и описание |
|---|---|
| 1 |
T Транспонирует строки и столбцы. |
| 2 |
оси Возвращает список с метками осей строк и меток осей столбцов в качестве единственных элементов. |
| 3 |
dtypes Возвращает dtypes в этом объекте. |
| 4 |
пустой True, если NDFrame полностью пуст [нет элементов]; если какая-либо из осей имеет длину 0. |
| 5 |
ndim Количество осей / размеры массива. |
| 6 |
форма Возвращает кортеж, представляющий размерность DataFrame. |
| 7 |
размер Количество элементов в NDFrame. |
| 8 |
ценности Numpy представление NDFrame. |
| 9 |
голова() Возвращает первые n строк. |
| 10 |
хвост() Возвращает последние n строк. |
T
Транспонирует строки и столбцы.
оси
Возвращает список с метками осей строк и меток осей столбцов в качестве единственных элементов.
dtypes
Возвращает dtypes в этом объекте.
пустой
True, если NDFrame полностью пуст [нет элементов]; если какая-либо из осей имеет длину 0.
ndim
Количество осей / размеры массива.
форма
Возвращает кортеж, представляющий размерность DataFrame.
размер
Количество элементов в NDFrame.
ценности
Numpy представление NDFrame.
голова()
Возвращает первые n строк.
хвост()
Возвращает последние n строк.
Давайте теперь создадим DataFrame и посмотрим, как работают вышеупомянутые атрибуты.
пример
Live Demo
import pandas as pd import numpy as np #Create a Dictionary of series d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack']), 'Age':pd.Series([25,26,25,23,30,29,23]), 'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8])} #Create a DataFrame df = pd.DataFrame(d) print ("Our data series is:") print df
Его вывод выглядит следующим образом –
Our data series is:
Age Name Rating
0 25 Tom 4.23
1 26 James 3.24
2 25 Ricky 3.98
3 23 Vin 2.56
4 30 Steve 3.20
5 29 Smith 4.60
6 23 Jack 3.80
T (Транспонировать)
Возвращает транспонирование DataFrame. Строки и столбцы будут чередоваться.
Live Demo
import pandas as pd import numpy as np # Create a Dictionary of series d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack']), 'Age':pd.Series([25,26,25,23,30,29,23]), 'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8])} # Create a DataFrame df = pd.DataFrame(d) print ("The transpose of the data series is:") print df.T
Его вывод выглядит следующим образом –
The transpose of the data series is:
0 1 2 3 4 5 6
Age 25 26 25 23 30 29 23
Name Tom James Ricky Vin Steve Smith Jack
Rating 4.23 3.24 3.98 2.56 3.2 4.6 3.8
оси
Возвращает список меток осей строк и меток осей столбцов.
Live Demo
import pandas as pd import numpy as np #Create a Dictionary of series d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack']), 'Age':pd.Series([25,26,25,23,30,29,23]), 'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8])} #Create a DataFrame df = pd.DataFrame(d) print ("Row axis labels and column axis labels are:") print df.axes
Его вывод выглядит следующим образом –
Row axis labels and column axis labels are: [RangeIndex(start=0, stop=7, step=1), Index([u'Age', u'Name', u'Rating'], dtype='object')]
dtypes
Возвращает тип данных каждого столбца.
Live Demo
import pandas as pd import numpy as np #Create a Dictionary of series d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack']), 'Age':pd.Series([25,26,25,23,30,29,23]), 'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8])} #Create a DataFrame df = pd.DataFrame(d) print ("The data types of each column are:") print df.dtypes
Его вывод выглядит следующим образом –
The data types of each column are: Age int64 Name object Rating float64 dtype: object
пустой
Возвращает логическое значение, указывающее, является ли объект пустым или нет; Истина означает, что объект пуст.
Live Demo
import pandas as pd import numpy as np #Create a Dictionary of series d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack']), 'Age':pd.Series([25,26,25,23,30,29,23]), 'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8])} #Create a DataFrame df = pd.DataFrame(d) print ("Is the object empty?") print df.empty
Его вывод выглядит следующим образом –
Is the object empty? False
ndim
Возвращает количество измерений объекта. По определению DataFrame является 2D-объектом.
Live Demo
import pandas as pd import numpy as np #Create a Dictionary of series d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack']), 'Age':pd.Series([25,26,25,23,30,29,23]), 'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8])} #Create a DataFrame df = pd.DataFrame(d) print ("Our object is:") print df print ("The dimension of the object is:") print df.ndim
Его вывод выглядит следующим образом –
Our object is:
Age Name Rating
0 25 Tom 4.23
1 26 James 3.24
2 25 Ricky 3.98
3 23 Vin 2.56
4 30 Steve 3.20
5 29 Smith 4.60
6 23 Jack 3.80
The dimension of the object is:
2
форма
Возвращает кортеж, представляющий размерность DataFrame. Кортеж (a, b), где a представляет количество строк, а b представляет количество столбцов.
Live Demo
import pandas as pd import numpy as np #Create a Dictionary of series d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack']), 'Age':pd.Series([25,26,25,23,30,29,23]), 'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8])} #Create a DataFrame df = pd.DataFrame(d) print ("Our object is:") print df print ("The shape of the object is:") print df.shape
Его вывод выглядит следующим образом –
Our object is: Age Name Rating 0 25 Tom 4.23 1 26 James 3.24 2 25 Ricky 3.98 3 23 Vin 2.56 4 30 Steve 3.20 5 29 Smith 4.60 6 23 Jack 3.80 The shape of the object is: (7, 3)
размер
Возвращает количество элементов в DataFrame.
Live Demo
import pandas as pd import numpy as np #Create a Dictionary of series d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack']), 'Age':pd.Series([25,26,25,23,30,29,23]), 'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8])} #Create a DataFrame df = pd.DataFrame(d) print ("Our object is:") print df print ("The total number of elements in our object is:") print df.size
Его вывод выглядит следующим образом –
Our object is:
Age Name Rating
0 25 Tom 4.23
1 26 James 3.24
2 25 Ricky 3.98
3 23 Vin 2.56
4 30 Steve 3.20
5 29 Smith 4.60
6 23 Jack 3.80
The total number of elements in our object is:
21
ценности
Возвращает фактические данные в DataFrame как NDarray.
Live Demo
import pandas as pd import numpy as np #Create a Dictionary of series d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack']), 'Age':pd.Series([25,26,25,23,30,29,23]), 'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8])} #Create a DataFrame df = pd.DataFrame(d) print ("Our object is:") print df print ("The actual data in our data frame is:") print df.values
Его вывод выглядит следующим образом –
Our object is:
Age Name Rating
0 25 Tom 4.23
1 26 James 3.24
2 25 Ricky 3.98
3 23 Vin 2.56
4 30 Steve 3.20
5 29 Smith 4.60
6 23 Jack 3.80
The actual data in our data frame is:
[[25 'Tom' 4.23]
[26 'James' 3.24]
[25 'Ricky' 3.98]
[23 'Vin' 2.56]
[30 'Steve' 3.2]
[29 'Smith' 4.6]
[23 'Jack' 3.8]]
Голова и хвост
Чтобы просмотреть небольшой образец объекта DataFrame, используйте методы head () и tail (). head () возвращает первые n строк (соблюдайте значения индекса). Количество отображаемых элементов по умолчанию – пять, но вы можете передать пользовательский номер.
Live Demo
import pandas as pd import numpy as np #Create a Dictionary of series d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack']), 'Age':pd.Series([25,26,25,23,30,29,23]), 'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8])} #Create a DataFrame df = pd.DataFrame(d) print ("Our data frame is:") print df print ("The first two rows of the data frame is:") print df.head(2)
Его вывод выглядит следующим образом –
Our data frame is:
Age Name Rating
0 25 Tom 4.23
1 26 James 3.24
2 25 Ricky 3.98
3 23 Vin 2.56
4 30 Steve 3.20
5 29 Smith 4.60
6 23 Jack 3.80
The first two rows of the data frame is:
Age Name Rating
0 25 Tom 4.23
1 26 James 3.24
tail () возвращает последние n строк (соблюдайте значения индекса). Количество отображаемых элементов по умолчанию – пять, но вы можете передать пользовательский номер.
Live Demo
import pandas as pd import numpy as np #Create a Dictionary of series d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack']), 'Age':pd.Series([25,26,25,23,30,29,23]), 'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8])} #Create a DataFrame df = pd.DataFrame(d) print ("Our data frame is:") print df print ("The last two rows of the data frame is:") print df.tail(2)
Его вывод выглядит следующим образом –
Our data frame is:
Age Name Rating
0 25 Tom 4.23
1 26 James 3.24
2 25 Ricky 3.98
3 23 Vin 2.56
4 30 Steve 3.20
5 29 Smith 4.60
6 23 Jack 3.80
The last two rows of the data frame is:
Age Name Rating
5 29 Smith 4.6
6 23 Jack 3.8
Python Pandas – описательная статистика
Большое количество методов совместно вычисляет описательную статистику и другие связанные операции над DataFrame. Большинство из них являются агрегатами, такими как sum (), mean (), но некоторые из них, например sumsum () , создают объект одинакового размера. Вообще говоря, эти методы принимают аргумент оси , как и ndarray. {Sum, std, …}, но ось может быть указана по имени или целому числу
-
DataFrame – «индекс» (ось = 0, по умолчанию), «столбцы» (ось = 1)
DataFrame – «индекс» (ось = 0, по умолчанию), «столбцы» (ось = 1)
Давайте создадим DataFrame и будем использовать этот объект в этой главе для всех операций.
пример
Live Demo
import pandas as pd import numpy as np #Create a Dictionary of series d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack', 'Lee','David','Gasper','Betina','Andres']), 'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]), 'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65]) } #Create a DataFrame df = pd.DataFrame(d) print df
Его вывод выглядит следующим образом –
Age Name Rating 0 25 Tom 4.23 1 26 James 3.24 2 25 Ricky 3.98 3 23 Vin 2.56 4 30 Steve 3.20 5 29 Smith 4.60 6 23 Jack 3.80 7 34 Lee 3.78 8 40 David 2.98 9 30 Gasper 4.80 10 51 Betina 4.10 11 46 Andres 3.65
сумма ()
Возвращает сумму значений для запрошенной оси. По умолчанию ось является индексом (ось = 0).
Live Demo
import pandas as pd import numpy as np #Create a Dictionary of series d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack', 'Lee','David','Gasper','Betina','Andres']), 'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]), 'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65]) } #Create a DataFrame df = pd.DataFrame(d) print df.sum()
Его вывод выглядит следующим образом –
Age 382 Name TomJamesRickyVinSteveSmithJackLeeDavidGasperBe... Rating 44.92 dtype: object
Каждый отдельный столбец добавляется индивидуально (строки добавляются).
Ось = 1
Этот синтаксис выдаст вывод, как показано ниже.
Live Demo
import pandas as pd import numpy as np #Create a Dictionary of series d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack', 'Lee','David','Gasper','Betina','Andres']), 'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]), 'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65]) } #Create a DataFrame df = pd.DataFrame(d) print df.sum(1)
Его вывод выглядит следующим образом –
0 29.23 1 29.24 2 28.98 3 25.56 4 33.20 5 33.60 6 26.80 7 37.78 8 42.98 9 34.80 10 55.10 11 49.65 dtype: float64
имею в виду()
Возвращает среднее значение
Live Demo
import pandas as pd import numpy as np #Create a Dictionary of series d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack', 'Lee','David','Gasper','Betina','Andres']), 'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]), 'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65]) } #Create a DataFrame df = pd.DataFrame(d) print df.mean()
Его вывод выглядит следующим образом –
Age 31.833333 Rating 3.743333 dtype: float64
станд ()
Возвращает стандартное отклонение Бресселя для числовых столбцов.
Live Demo
import pandas as pd import numpy as np #Create a Dictionary of series d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack', 'Lee','David','Gasper','Betina','Andres']), 'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]), 'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65]) } #Create a DataFrame df = pd.DataFrame(d) print df.std()
Его вывод выглядит следующим образом –
Age 9.232682 Rating 0.661628 dtype: float64
Функции и описание
Давайте теперь разберемся с функциями описательной статистики в Python Pandas. В следующей таблице перечислены важные функции –
| Sr.No. | функция | Описание |
|---|---|---|
| 1 | кол-() | Количество ненулевых наблюдений |
| 2 | сумма () | Сумма значений |
| 3 | имею в виду() | Среднее значение |
| 4 | медиана () | Медиана ценностей |
| 5 | Режим() | Режим ценностей |
| 6 | станд () | Стандартное отклонение значений |
| 7 | мин () | Минимальное значение |
| 8 | Максимум() | Максимальное значение |
| 9 | абс () | Абсолютная величина |
| 10 | прод () | Продукт ценностей |
| 11 | cumsum () | Накопительная сумма |
| 12 | cumprod () | Накопительный продукт |
Примечание. Поскольку DataFrame является гетерогенной структурой данных. Общие операции не работают со всеми функциями.
-
Такие функции, как sum (), cumsum (), работают как с числовыми, так и с символьными (или) строковыми элементами данных без каких-либо ошибок. Хотя на практике агрегации символов обычно не используются, эти функции не выдают никаких исключений.
-
Такие функции, как abs (), cumprod () выдают исключение, когда DataFrame содержит символьные или строковые данные, поскольку такие операции не могут быть выполнены.
Такие функции, как sum (), cumsum (), работают как с числовыми, так и с символьными (или) строковыми элементами данных без каких-либо ошибок. Хотя на практике агрегации символов обычно не используются, эти функции не выдают никаких исключений.
Такие функции, как abs (), cumprod () выдают исключение, когда DataFrame содержит символьные или строковые данные, поскольку такие операции не могут быть выполнены.
Обобщающие данные
Функция description () вычисляет сводную статистику, относящуюся к столбцам DataFrame.
Live Demo
import pandas as pd import numpy as np #Create a Dictionary of series d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack', 'Lee','David','Gasper','Betina','Andres']), 'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]), 'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65]) } #Create a DataFrame df = pd.DataFrame(d) print df.describe()
Его вывод выглядит следующим образом –
Age Rating count 12.000000 12.000000 mean 31.833333 3.743333 std 9.232682 0.661628 min 23.000000 2.560000 25% 25.000000 3.230000 50% 29.500000 3.790000 75% 35.500000 4.132500 max 51.000000 4.800000
Эта функция дает среднее, стандартное и IQR значения. И, функция исключает символьные столбцы и данные о числовых столбцах. «include» – это аргумент, который используется для передачи необходимой информации о том, какие столбцы необходимо учитывать для обобщения. Принимает список значений; по умолчанию «число».
- объект – суммирует строковые столбцы
- число – суммирует числовые столбцы
- all – суммирует все столбцы вместе (не следует передавать его как значение списка)
Теперь используйте следующую инструкцию в программе и проверьте вывод:
Live Demo
import pandas as pd import numpy as np #Create a Dictionary of series d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack', 'Lee','David','Gasper','Betina','Andres']), 'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]), 'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65]) } #Create a DataFrame df = pd.DataFrame(d) print df.describe(include=['object'])
Его вывод выглядит следующим образом –
Name count 12 unique 12 top Ricky freq 1
Теперь используйте следующую инструкцию и проверьте вывод –
Live Demo
import pandas as pd import numpy as np #Create a Dictionary of series d = {'Name':pd.Series(['Tom','James','Ricky','Vin','Steve','Smith','Jack', 'Lee','David','Gasper','Betina','Andres']), 'Age':pd.Series([25,26,25,23,30,29,23,34,40,30,51,46]), 'Rating':pd.Series([4.23,3.24,3.98,2.56,3.20,4.6,3.8,3.78,2.98,4.80,4.10,3.65]) } #Create a DataFrame df = pd.DataFrame(d) print df. describe(include='all')
Его вывод выглядит следующим образом –
Age Name Rating count 12.000000 12 12.000000 unique NaN 12 NaN top NaN Ricky NaN freq NaN 1 NaN mean 31.833333 NaN 3.743333 std 9.232682 NaN 0.661628 min 23.000000 NaN 2.560000 25% 25.000000 NaN 3.230000 50% 29.500000 NaN 3.790000 75% 35.500000 NaN 4.132500 max 51.000000 NaN 4.800000
Python Pandas – функциональное приложение
Чтобы применить свои собственные функции или функции другой библиотеки к объектам Pandas, вы должны знать о трех важных методах. Методы были обсуждены ниже. Подходящий метод, который нужно использовать, зависит от того, ожидает ли ваша функция работы со всем DataFrame, по строкам или столбцам, или по элементам.
- Таблица мудрая Функция Применение: труба ()
- Функция строки или столбца мудрая Применение: apply ()
- Элемент мудрой функции Применение: applymap ()
Табличное применение функций
Пользовательские операции можно выполнить, передав функцию и соответствующее количество параметров в качестве аргументов канала. Таким образом, операция выполняется на весь DataFrame.
Например, добавьте значение 2 ко всем элементам в DataFrame. Затем,
функция сумматора
Функция сумматора добавляет два числовых значения в качестве параметров и возвращает сумму.
def adder(ele1,ele2): return ele1+ele2
Теперь мы будем использовать пользовательскую функцию для выполнения операций с DataFrame.
df = pd.DataFrame(np.random.randn(5,3),columns=['col1','col2','col3']) df.pipe(adder,2)
Давайте посмотрим полную программу –
Live Demo
import pandas as pd import numpy as np def adder(ele1,ele2): return ele1+ele2 df = pd.DataFrame(np.random.randn(5,3),columns=['col1','col2','col3']) df.pipe(adder,2) print df.apply(np.mean)
Его вывод выглядит следующим образом –
col1 col2 col3 0 2.176704 2.219691 1.509360 1 2.222378 2.422167 3.953921 2 2.241096 1.135424 2.696432 3 2.355763 0.376672 1.182570 4 2.308743 2.714767 2.130288
Функция выбора строки или столбца
Произвольные функции могут быть применены вдоль осей DataFrame или Panel с помощью метода apply () , который, как и методы описательной статистики, принимает необязательный аргумент оси. По умолчанию операция выполняется по столбцам, принимая каждый столбец как массив.
Пример 1
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5,3),columns=['col1','col2','col3']) df.apply(np.mean) print df.apply(np.mean)
Его вывод выглядит следующим образом –
col1 -0.288022 col2 1.044839 col3 -0.187009 dtype: float64
Передав параметр оси , операции могут выполняться по строкам.
Пример 2
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5,3),columns=['col1','col2','col3']) df.apply(np.mean,axis=1) print df.apply(np.mean)
Его вывод выглядит следующим образом –
col1 0.034093 col2 -0.152672 col3 -0.229728 dtype: float64
Пример 3
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5,3),columns=['col1','col2','col3']) df.apply(lambda x: x.max() - x.min()) print df.apply(np.mean)
Его вывод выглядит следующим образом –
col1 -0.167413 col2 -0.370495 col3 -0.707631 dtype: float64
Элемент Wise Функция Применение
Не все функции могут быть векторизованы (ни массивы NumPy, которые возвращают другой массив, ни какое-либо значение), методы applymap () в DataFrame и аналогично map () в Series принимают любую функцию Python, принимающую одно значение и возвращающую одно значение.
Пример 1
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5,3),columns=['col1','col2','col3']) # My custom function df['col1'].map(lambda x:x*100) print df.apply(np.mean)
Его вывод выглядит следующим образом –
col1 0.480742 col2 0.454185 col3 0.266563 dtype: float64
Пример 2
Live Demo
import pandas as pd import numpy as np # My custom function df = pd.DataFrame(np.random.randn(5,3),columns=['col1','col2','col3']) df.applymap(lambda x:x*100) print df.apply(np.mean)
Его вывод выглядит следующим образом –
col1 0.395263 col2 0.204418 col3 -0.795188 dtype: float64
Python Pandas – переиндексация
Переиндексация изменяет метки строк и меток столбцов DataFrame. Переиндексация означает соответствие данных для соответствия заданному набору меток вдоль определенной оси.
Многократные операции могут быть выполнены посредством индексации как –
-
Изменить порядок существующих данных, чтобы они соответствовали новому набору меток.
-
Вставьте маркеры отсутствующего значения (NA) в те места, где не было данных для метки.
Изменить порядок существующих данных, чтобы они соответствовали новому набору меток.
Вставьте маркеры отсутствующего значения (NA) в те места, где не было данных для метки.
пример
Live Demo
import pandas as pd import numpy as np N=20 df = pd.DataFrame({ 'A': pd.date_range(start='2016-01-01',periods=N,freq='D'), 'x': np.linspace(0,stop=N-1,num=N), 'y': np.random.rand(N), 'C': np.random.choice(['Low','Medium','High'],N).tolist(), 'D': np.random.normal(100, 10, size=(N)).tolist() }) #reindex the DataFrame df_reindexed = df.reindex(index=[0,2,5], columns=['A', 'C', 'B']) print df_reindexed
Его вывод выглядит следующим образом –
A C B 0 2016-01-01 Low NaN 2 2016-01-03 High NaN 5 2016-01-06 Low NaN
Переиндексировать для выравнивания с другими объектами
Вы можете взять объект и переиндексировать его оси так, чтобы он был помечен как другой объект. Рассмотрим следующий пример, чтобы понять то же самое.
пример
Live Demo
import pandas as pd import numpy as np df1 = pd.DataFrame(np.random.randn(10,3),columns=['col1','col2','col3']) df2 = pd.DataFrame(np.random.randn(7,3),columns=['col1','col2','col3']) df1 = df1.reindex_like(df2) print df1
Его вывод выглядит следующим образом –
col1 col2 col3 0 -2.467652 -1.211687 -0.391761 1 -0.287396 0.522350 0.562512 2 -0.255409 -0.483250 1.866258 3 -1.150467 -0.646493 -0.222462 4 0.152768 -2.056643 1.877233 5 -1.155997 1.528719 -1.343719 6 -1.015606 -1.245936 -0.295275
Примечание. Здесь фрейм данных df1 изменяется и переиндексируется, как и df2 . Имена столбцов должны совпадать, иначе NAN будет добавлен для всей метки столбца.
Заполнение при переиндексации
Метод reindex () принимает метод необязательного параметра, который представляет собой метод заполнения со следующими значениями:
-
pad / ffill – заполнить значения вперед
-
bfill / backfill – заполнить значения задом наперед
-
ближайший – заполнить из ближайших значений индекса
pad / ffill – заполнить значения вперед
bfill / backfill – заполнить значения задом наперед
ближайший – заполнить из ближайших значений индекса
пример
Live Demo
import pandas as pd import numpy as np df1 = pd.DataFrame(np.random.randn(6,3),columns=['col1','col2','col3']) df2 = pd.DataFrame(np.random.randn(2,3),columns=['col1','col2','col3']) # Padding NAN's print df2.reindex_like(df1) # Now Fill the NAN's with preceding Values print ("Data Frame with Forward Fill:") print df2.reindex_like(df1,method='ffill')
Его вывод выглядит следующим образом –
col1 col2 col3
0 1.311620 -0.707176 0.599863
1 -0.423455 -0.700265 1.133371
2 NaN NaN NaN
3 NaN NaN NaN
4 NaN NaN NaN
5 NaN NaN NaN
Data Frame with Forward Fill:
col1 col2 col3
0 1.311620 -0.707176 0.599863
1 -0.423455 -0.700265 1.133371
2 -0.423455 -0.700265 1.133371
3 -0.423455 -0.700265 1.133371
4 -0.423455 -0.700265 1.133371
5 -0.423455 -0.700265 1.133371
Примечание . Последние четыре строки дополняются.
Ограничения на наполнение при переиндексации
Аргумент limit обеспечивает дополнительный контроль над заполнением при переиндексации. Лимит определяет максимальное количество последовательных совпадений. Давайте рассмотрим следующий пример, чтобы понять то же самое –
пример
Live Demo
import pandas as pd import numpy as np df1 = pd.DataFrame(np.random.randn(6,3),columns=['col1','col2','col3']) df2 = pd.DataFrame(np.random.randn(2,3),columns=['col1','col2','col3']) # Padding NAN's print df2.reindex_like(df1) # Now Fill the NAN's with preceding Values print ("Data Frame with Forward Fill limiting to 1:") print df2.reindex_like(df1,method='ffill',limit=1)
Его вывод выглядит следующим образом –
col1 col2 col3
0 0.247784 2.128727 0.702576
1 -0.055713 -0.021732 -0.174577
2 NaN NaN NaN
3 NaN NaN NaN
4 NaN NaN NaN
5 NaN NaN NaN
Data Frame with Forward Fill limiting to 1:
col1 col2 col3
0 0.247784 2.128727 0.702576
1 -0.055713 -0.021732 -0.174577
2 -0.055713 -0.021732 -0.174577
3 NaN NaN NaN
4 NaN NaN NaN
5 NaN NaN NaN
Примечание. Обратите внимание, что предыдущая 6-я строка заполнена только седьмой строкой. Затем строки остаются как есть.
Переименование
Метод rename () позволяет перемаркировать ось на основе некоторого сопоставления (dict или Series) или произвольной функции.
Давайте рассмотрим следующий пример, чтобы понять это –
Live Demo
import pandas as pd import numpy as np df1 = pd.DataFrame(np.random.randn(6,3),columns=['col1','col2','col3']) print df1 print ("After renaming the rows and columns:") print df1.rename(columns={'col1' : 'c1', 'col2' : 'c2'}, index = {0 : 'apple', 1 : 'banana', 2 : 'durian'})
Его вывод выглядит следующим образом –
col1 col2 col3
0 0.486791 0.105759 1.540122
1 -0.990237 1.007885 -0.217896
2 -0.483855 -1.645027 -1.194113
3 -0.122316 0.566277 -0.366028
4 -0.231524 -0.721172 -0.112007
5 0.438810 0.000225 0.435479
After renaming the rows and columns:
c1 c2 col3
apple 0.486791 0.105759 1.540122
banana -0.990237 1.007885 -0.217896
durian -0.483855 -1.645027 -1.194113
3 -0.122316 0.566277 -0.366028
4 -0.231524 -0.721172 -0.112007
5 0.438810 0.000225 0.435479
Метод rename () предоставляет параметр с именем inplace , который по умолчанию имеет значение False и копирует базовые данные. Pass inplace = True, чтобы переименовать данные на месте.
Python Pandas – Итерация
Поведение базовой итерации над объектами Pandas зависит от типа. При итерации по Серии она рассматривается как массив, и базовая итерация выдает значения. Другие структуры данных, такие как DataFrame и Panel, следуют соглашению о переборах ключей объектов.
Короче говоря, базовая итерация (для i в объекте) производит –
-
Серия – ценности
-
DataFrame – метки столбцов
-
Панель – ярлыки элементов
Серия – ценности
DataFrame – метки столбцов
Панель – ярлыки элементов
Итерация DataFrame
Итерация DataFrame дает имена столбцов. Давайте рассмотрим следующий пример, чтобы понять то же самое.
Live Demo
import pandas as pd import numpy as np N=20 df = pd.DataFrame({ 'A': pd.date_range(start='2016-01-01',periods=N,freq='D'), 'x': np.linspace(0,stop=N-1,num=N), 'y': np.random.rand(N), 'C': np.random.choice(['Low','Medium','High'],N).tolist(), 'D': np.random.normal(100, 10, size=(N)).tolist() }) for col in df: print col
Его вывод выглядит следующим образом –
A C D x y
Чтобы перебрать строки DataFrame, мы можем использовать следующие функции:
-
iteritems () – для перебора пар (ключ, значение)
-
iterrows () – перебирает строки как пары (index, series)
-
itertuples () – перебирает строки как именованные
iteritems () – для перебора пар (ключ, значение)
iterrows () – перебирает строки как пары (index, series)
itertuples () – перебирает строки как именованные
iteritems ()
Перебирает каждый столбец в качестве ключа, пару значений с меткой в качестве ключа и значение столбца в качестве объекта Series.
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(4,3),columns=['col1','col2','col3']) for key,value in df.iteritems(): print key,value
Его вывод выглядит следующим образом –
col1 0 0.802390 1 0.324060 2 0.256811 3 0.839186 Name: col1, dtype: float64 col2 0 1.624313 1 -1.033582 2 1.796663 3 1.856277 Name: col2, dtype: float64 col3 0 -0.022142 1 -0.230820 2 1.160691 3 -0.830279 Name: col3, dtype: float64
Обратите внимание, что каждый столбец повторяется отдельно в виде пары ключ-значение в серии.
iterrows ()
iterrows () возвращает итератор, дающий каждое значение индекса вместе с серией, содержащей данные в каждой строке.
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(4,3),columns = ['col1','col2','col3']) for row_index,row in df.iterrows(): print row_index,row
Его вывод выглядит следующим образом –
0 col1 1.529759 col2 0.762811 col3 -0.634691 Name: 0, dtype: float64 1 col1 -0.944087 col2 1.420919 col3 -0.507895 Name: 1, dtype: float64 2 col1 -0.077287 col2 -0.858556 col3 -0.663385 Name: 2, dtype: float64 3 col1 -1.638578 col2 0.059866 col3 0.493482 Name: 3, dtype: float64
Примечание. Поскольку iterrows () выполняет итерацию по строкам, он не сохраняет тип данных по всей строке. 0,1,2 – индексы строк, а col1, col2, col3 – индексы столбцов.
itertuples ()
Метод itertuples () возвращает итератор, выдающий именованный кортеж для каждой строки в DataFrame. Первым элементом кортежа будет соответствующее значение индекса строки, в то время как остальные значения являются значениями строки.
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(4,3),columns = ['col1','col2','col3']) for row in df.itertuples(): print row
Его вывод выглядит следующим образом –
Pandas(Index=0, col1=1.5297586201375899, col2=0.76281127433814944, col3=- 0.6346908238310438) Pandas(Index=1, col1=-0.94408735763808649, col2=1.4209186418359423, col3=- 0.50789517967096232) Pandas(Index=2, col1=-0.07728664756791935, col2=-0.85855574139699076, col3=- 0.6633852507207626) Pandas(Index=3, col1=0.65734942534106289, col2=-0.95057710432604969, col3=0.80344487462316527)
Примечание. Не пытайтесь изменить какой-либо объект во время итерации. Итерация предназначена для чтения, и итератор возвращает копию исходного объекта (представление), поэтому изменения не отразятся на исходном объекте.
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(4,3),columns = ['col1','col2','col3']) for index, row in df.iterrows(): row['a'] = 10 print df
Его вывод выглядит следующим образом –
col1 col2 col3 0 -1.739815 0.735595 -0.295589 1 0.635485 0.106803 1.527922 2 -0.939064 0.547095 0.038585 3 -1.016509 -0.116580 -0.523158
Наблюдайте, никаких изменений не отражено.
Питон Панды – Сортировка
В Пандах есть два вида сортировки. Они –
- По ярлыку
- По фактической стоимости
Давайте рассмотрим пример с выводом.
import pandas as pd import numpy as np unsorted_df=pd.DataFrame(np.random.randn(10,2),index=[1,4,6,2,3,5,9,8,0,7],colu mns=['col2','col1']) print unsorted_df
Его вывод выглядит следующим образом –
col2 col1 1 -2.063177 0.537527 4 0.142932 -0.684884 6 0.012667 -0.389340 2 -0.548797 1.848743 3 -1.044160 0.837381 5 0.385605 1.300185 9 1.031425 -1.002967 8 -0.407374 -0.435142 0 2.237453 -1.067139 7 -1.445831 -1.701035
В unsorted_df метки и значения не отсортированы. Давайте посмотрим, как они могут быть отсортированы.
По метке
Используя метод sort_index () , передав аргументы оси и порядок сортировки, DataFrame может быть отсортирован. По умолчанию сортировка выполняется по меткам строк в порядке возрастания.
import pandas as pd import numpy as np unsorted_df = pd.DataFrame(np.random.randn(10,2),index=[1,4,6,2,3,5,9,8,0,7],colu mns = ['col2','col1']) sorted_df=unsorted_df.sort_index() print sorted_df
Его вывод выглядит следующим образом –
col2 col1 0 0.208464 0.627037 1 0.641004 0.331352 2 -0.038067 -0.464730 3 -0.638456 -0.021466 4 0.014646 -0.737438 5 -0.290761 -1.669827 6 -0.797303 -0.018737 7 0.525753 1.628921 8 -0.567031 0.775951 9 0.060724 -0.322425
Порядок сортировки
Передав логическое значение восходящему параметру, порядок сортировки можно контролировать. Давайте рассмотрим следующий пример, чтобы понять то же самое.
import pandas as pd import numpy as np unsorted_df = pd.DataFrame(np.random.randn(10,2),index=[1,4,6,2,3,5,9,8,0,7],colu mns = ['col2','col1']) sorted_df = unsorted_df.sort_index(ascending=False) print sorted_df
Его вывод выглядит следующим образом –
col2 col1 9 0.825697 0.374463 8 -1.699509 0.510373 7 -0.581378 0.622958 6 -0.202951 0.954300 5 -1.289321 -1.551250 4 1.302561 0.851385 3 -0.157915 -0.388659 2 -1.222295 0.166609 1 0.584890 -0.291048 0 0.668444 -0.061294
Сортировать столбцы
Передав аргумент оси со значением 0 или 1, можно выполнить сортировку по меткам столбца. По умолчанию ось = 0, сортировка по строке. Давайте рассмотрим следующий пример, чтобы понять то же самое.
import pandas as pd import numpy as np unsorted_df = pd.DataFrame(np.random.randn(10,2),index=[1,4,6,2,3,5,9,8,0,7],colu mns = ['col2','col1']) sorted_df=unsorted_df.sort_index(axis=1) print sorted_df
Его вывод выглядит следующим образом –
col1 col2 1 -0.291048 0.584890 4 0.851385 1.302561 6 0.954300 -0.202951 2 0.166609 -1.222295 3 -0.388659 -0.157915 5 -1.551250 -1.289321 9 0.374463 0.825697 8 0.510373 -1.699509 0 -0.061294 0.668444 7 0.622958 -0.581378
По значению
Как и сортировка индекса, sort_values () – это метод сортировки по значениям. Он принимает аргумент «by», который будет использовать имя столбца DataFrame, с которым должны быть отсортированы значения.
import pandas as pd import numpy as np unsorted_df = pd.DataFrame({'col1':[2,1,1,1],'col2':[1,3,2,4]}) sorted_df = unsorted_df.sort_values(by='col1') print sorted_df
Его вывод выглядит следующим образом –
col1 col2 1 1 3 2 1 2 3 1 4 0 2 1
Заметьте, значения col1 отсортированы, и соответствующие значение col2 и индекс строки изменятся вместе с col1. Таким образом, они выглядят несортированными.
аргумент ‘by’ принимает список значений столбца.
import pandas as pd import numpy as np unsorted_df = pd.DataFrame({'col1':[2,1,1,1],'col2':[1,3,2,4]}) sorted_df = unsorted_df.sort_values(by=['col1','col2']) print sorted_df
Его вывод выглядит следующим образом –
col1 col2 2 1 2 1 1 3 3 1 4 0 2 1
Алгоритм сортировки
sort_values () предоставляет возможность выбора алгоритма из mergesort, heapsort и quicksort. Mergesort – единственный стабильный алгоритм.
Live Demo
import pandas as pd import numpy as np unsorted_df = pd.DataFrame({'col1':[2,1,1,1],'col2':[1,3,2,4]}) sorted_df = unsorted_df.sort_values(by='col1' ,kind='mergesort') print sorted_df
Его вывод выглядит следующим образом –
col1 col2 1 1 3 2 1 2 3 1 4 0 2 1
Python Pandas – Работа с текстовыми данными
В этой главе мы обсудим строковые операции с нашей базовой серией / индексом. В последующих главах мы узнаем, как применять эти строковые функции к DataFrame.
Pandas предоставляет набор строковых функций, которые облегчают работу со строковыми данными. Наиболее важно, что эти функции игнорируют (или исключают) отсутствующие значения / NaN.
Почти все эти методы работают со строковыми функциями Python (см .: https://docs.python.org/3/library/stdtypes.html#string-methods ). Итак, преобразуйте объект Series в объект String и затем выполните операцию.
Давайте теперь посмотрим, как выполняется каждая операция.
| Sr.No | Описание функции |
|---|---|
| 1 |
ниже () Преобразует строки в Series / Index в нижний регистр. |
| 2 |
Верхняя () Преобразует строки в Series / Index в верхний регистр. |
| 3 |
LEN () Вычисляет длину строки (). |
| 4 |
полоса () Помогает удалить пробелы (включая перевод строки) из каждой строки в Серии / индексе с обеих сторон. |
| 5 |
Трещина(‘ ‘) Разбивает каждую строку по заданному шаблону. |
| 6 |
кошка (sep = ”) Объединяет элементы серии / индекса с указанным разделителем. |
| 7 |
get_dummies () Возвращает DataFrame с закодированными значениями One-Hot. |
| 8 |
содержит (шаблон) Возвращает логическое значение True для каждого элемента, если подстрока содержится в элементе, иначе False. |
| 9 |
заменить (а, б) Заменяет значение a значением b . |
| 10 |
повтор (значение) Повторяет каждый элемент с указанным числом раз. |
| 11 |
кол – (шаблон) Возвращает количество появлений шаблона в каждом элементе. |
| 12 |
StartsWith (шаблон) Возвращает true, если элемент в Series / Index начинается с шаблона. |
| 13 |
EndsWith (шаблон) Возвращает true, если элемент в Series / Index заканчивается шаблоном. |
| 14 |
найти (шаблон) Возвращает первую позицию первого вхождения шаблона. |
| 15 |
FindAll (шаблон) Возвращает список всех вхождений шаблона. |
| 16 |
swapcase Меняет местами корпус нижний / верхний. |
| 17 |
ISLOWER () Проверяет, все ли символы в каждой строке в Серии / Индексе в нижнем регистре или нет. Возвращает логическое значение |
| 18 |
ISUPPER () Проверяет, все ли символы в каждой строке в Серии / Индексе в верхнем регистре или нет. Возвращает логическое значение. |
| 19 |
IsNumeric () Проверяет, являются ли все символы в каждой строке в Серии / Индексе числовыми. Возвращает логическое значение. |
ниже ()
Преобразует строки в Series / Index в нижний регистр.
Верхняя ()
Преобразует строки в Series / Index в верхний регистр.
LEN ()
Вычисляет длину строки ().
полоса ()
Помогает удалить пробелы (включая перевод строки) из каждой строки в Серии / индексе с обеих сторон.
Трещина(‘ ‘)
Разбивает каждую строку по заданному шаблону.
кошка (sep = ”)
Объединяет элементы серии / индекса с указанным разделителем.
get_dummies ()
Возвращает DataFrame с закодированными значениями One-Hot.
содержит (шаблон)
Возвращает логическое значение True для каждого элемента, если подстрока содержится в элементе, иначе False.
заменить (а, б)
Заменяет значение a значением b .
повтор (значение)
Повторяет каждый элемент с указанным числом раз.
кол – (шаблон)
Возвращает количество появлений шаблона в каждом элементе.
StartsWith (шаблон)
Возвращает true, если элемент в Series / Index начинается с шаблона.
EndsWith (шаблон)
Возвращает true, если элемент в Series / Index заканчивается шаблоном.
найти (шаблон)
Возвращает первую позицию первого вхождения шаблона.
FindAll (шаблон)
Возвращает список всех вхождений шаблона.
swapcase
Меняет местами корпус нижний / верхний.
ISLOWER ()
Проверяет, все ли символы в каждой строке в Серии / Индексе в нижнем регистре или нет. Возвращает логическое значение
ISUPPER ()
Проверяет, все ли символы в каждой строке в Серии / Индексе в верхнем регистре или нет. Возвращает логическое значение.
IsNumeric ()
Проверяет, являются ли все символы в каждой строке в Серии / Индексе числовыми. Возвращает логическое значение.
Давайте теперь создадим серию и посмотрим, как работают все вышеперечисленные функции.
Live Demo
import pandas as pd import numpy as np s = pd.Series(['Tom', 'William Rick', 'John', 'Alber@t', np.nan, '1234','SteveSmith']) print s
Его вывод выглядит следующим образом –
0 Tom 1 William Rick 2 John 3 Alber@t 4 NaN 5 1234 6 Steve Smith dtype: object
ниже ()
Live Demo
import pandas as pd import numpy as np s = pd.Series(['Tom', 'William Rick', 'John', 'Alber@t', np.nan, '1234','SteveSmith']) print s.str.lower()
Его вывод выглядит следующим образом –
0 tom 1 william rick 2 john 3 alber@t 4 NaN 5 1234 6 steve smith dtype: object
Верхняя ()
Live Demo
import pandas as pd import numpy as np s = pd.Series(['Tom', 'William Rick', 'John', 'Alber@t', np.nan, '1234','SteveSmith']) print s.str.upper()
Его вывод выглядит следующим образом –
0 TOM 1 WILLIAM RICK 2 JOHN 3 ALBER@T 4 NaN 5 1234 6 STEVE SMITH dtype: object
LEN ()
Live Demo
import pandas as pd import numpy as np s = pd.Series(['Tom', 'William Rick', 'John', 'Alber@t', np.nan, '1234','SteveSmith']) print s.str.len()
Его вывод выглядит следующим образом –
0 3.0 1 12.0 2 4.0 3 7.0 4 NaN 5 4.0 6 10.0 dtype: float64
полоса ()
Live Demo
import pandas as pd import numpy as np s = pd.Series(['Tom ', ' William Rick', 'John', 'Alber@t']) print s print ("After Stripping:") print s.str.strip()
Его вывод выглядит следующим образом –
0 Tom 1 William Rick 2 John 3 Alber@t dtype: object After Stripping: 0 Tom 1 William Rick 2 John 3 Alber@t dtype: object
сплит (шаблон)
Live Demo
import pandas as pd import numpy as np s = pd.Series(['Tom ', ' William Rick', 'John', 'Alber@t']) print s print ("Split Pattern:") print s.str.split(' ')
Его вывод выглядит следующим образом –
0 Tom 1 William Rick 2 John 3 Alber@t dtype: object Split Pattern: 0 [Tom, , , , , , , , , , ] 1 [, , , , , William, Rick] 2 [John] 3 [Alber@t] dtype: object
кошка (сентябрь = шаблон)
Live Demo
import pandas as pd import numpy as np s = pd.Series(['Tom ', ' William Rick', 'John', 'Alber@t']) print s.str.cat(sep='_')
Его вывод выглядит следующим образом –
Tom _ William Rick_John_Alber@t
get_dummies ()
Live Demo
import pandas as pd import numpy as np s = pd.Series(['Tom ', ' William Rick', 'John', 'Alber@t']) print s.str.get_dummies()
Его вывод выглядит следующим образом –
William Rick Alber@t John Tom 0 0 0 0 1 1 1 0 0 0 2 0 0 1 0 3 0 1 0 0
содержит ()
Live Demo
import pandas as pd s = pd.Series(['Tom ', ' William Rick', 'John', 'Alber@t']) print s.str.contains(' ')
Его вывод выглядит следующим образом –
0 True 1 True 2 False 3 False dtype: bool
заменить (а, б)
Live Demo
import pandas as pd s = pd.Series(['Tom ', ' William Rick', 'John', 'Alber@t']) print s print ("After replacing @ with $:") print s.str.replace('@','$')
Его вывод выглядит следующим образом –
0 Tom 1 William Rick 2 John 3 Alber@t dtype: object After replacing @ with $: 0 Tom 1 William Rick 2 John 3 Alber$t dtype: object
повтор (значение)
Live Demo
import pandas as pd s = pd.Series(['Tom ', ' William Rick', 'John', 'Alber@t']) print s.str.repeat(2)
Его вывод выглядит следующим образом –
0 Tom Tom 1 William Rick William Rick 2 JohnJohn 3 Alber@tAlber@t dtype: object
кол-(шаблон)
Live Demo
import pandas as pd s = pd.Series(['Tom ', ' William Rick', 'John', 'Alber@t']) print ("The number of 'm's in each string:") print s.str.count('m')
Его вывод выглядит следующим образом –
The number of 'm's in each string: 0 1 1 1 2 0 3 0
StartsWith (шаблон)
Live Demo
import pandas as pd s = pd.Series(['Tom ', ' William Rick', 'John', 'Alber@t']) print ("Strings that start with 'T':") print s.str. startswith ('T')
Его вывод выглядит следующим образом –
0 True 1 False 2 False 3 False dtype: bool
EndsWith (шаблон)
Live Demo
import pandas as pd s = pd.Series(['Tom ', ' William Rick', 'John', 'Alber@t']) print ("Strings that end with 't':") print s.str.endswith('t')
Его вывод выглядит следующим образом –
Strings that end with 't': 0 False 1 False 2 False 3 True dtype: bool
найти (шаблон)
Live Demo
import pandas as pd s = pd.Series(['Tom ', ' William Rick', 'John', 'Alber@t']) print s.str.find('e')
Его вывод выглядит следующим образом –
0 -1 1 -1 2 -1 3 3 dtype: int64
«-1» означает, что в элементе нет такого шаблона.
FindAll (шаблон)
Live Demo
import pandas as pd s = pd.Series(['Tom ', ' William Rick', 'John', 'Alber@t']) print s.str.findall('e')
Его вывод выглядит следующим образом –
0 [] 1 [] 2 [] 3 [e] dtype: object
Пустой список ([]) указывает, что в элементе нет такого шаблона.
swapcase ()
Live Demo
import pandas as pd s = pd.Series(['Tom', 'William Rick', 'John', 'Alber@t']) print s.str.swapcase()
Его вывод выглядит следующим образом –
0 tOM 1 wILLIAM rICK 2 jOHN 3 aLBER@T dtype: object
ISLOWER ()
Live Demo
import pandas as pd s = pd.Series(['Tom', 'William Rick', 'John', 'Alber@t']) print s.str.islower()
Его вывод выглядит следующим образом –
0 False 1 False 2 False 3 False dtype: bool
ISUPPER ()
Live Demo
import pandas as pd s = pd.Series(['Tom', 'William Rick', 'John', 'Alber@t']) print s.str.isupper()
Его вывод выглядит следующим образом –
0 False 1 False 2 False 3 False dtype: bool
IsNumeric ()
Live Demo
import pandas as pd s = pd.Series(['Tom', 'William Rick', 'John', 'Alber@t']) print s.str.isnumeric()
Его вывод выглядит следующим образом –
0 False 1 False 2 False 3 False dtype: bool
Python Pandas – Опции и настройка
Панды предоставляют API для настройки некоторых аспектов своего поведения, в основном используется отображение.
API состоит из пяти соответствующих функций. Они –
- get_option ()
- set_option ()
- reset_option ()
- describe_option ()
- option_context ()
Давайте теперь поймем, как работают функции.
get_option (пары)
get_option принимает один параметр и возвращает значение, как указано в выходных данных ниже –
display.max_rows
Отображает номер значения по умолчанию. Интерпретатор считывает это значение и отображает строки с этим значением в качестве верхнего предела для отображения.
Live Demo
import pandas as pd print pd.get_option("display.max_rows")
Его вывод выглядит следующим образом –
60
display.max_columns
Отображает номер значения по умолчанию. Интерпретатор считывает это значение и отображает строки с этим значением в качестве верхнего предела для отображения.
Live Demo
import pandas as pd print pd.get_option("display.max_columns")
Его вывод выглядит следующим образом –
20
Здесь 60 и 20 являются значениями параметров конфигурации по умолчанию.
set_option (пары, значение)
set_option принимает два аргумента и устанавливает значение параметра, как показано ниже –
display.max_rows
Используя set_option () , мы можем изменить количество отображаемых строк по умолчанию.
Live Demo
import pandas as pd pd.set_option("display.max_rows",80) print pd.get_option("display.max_rows")
Его вывод выглядит следующим образом –
80
display.max_columns
Используя set_option () , мы можем изменить количество отображаемых строк по умолчанию.
Live Demo
import pandas as pd pd.set_option("display.max_columns",30) print pd.get_option("display.max_columns")
Его вывод выглядит следующим образом –
30
reset_option (пары)
reset_option принимает аргумент и устанавливает значение обратно в значение по умолчанию.
display.max_rows
Используя reset_option (), мы можем изменить значение обратно на количество строк по умолчанию для отображения.
Live Demo
import pandas as pd pd.reset_option("display.max_rows") print pd.get_option("display.max_rows")
Его вывод выглядит следующим образом –
60
describe_option (пары)
description_option печатает описание аргумента.
display.max_rows
Используя reset_option (), мы можем изменить значение обратно на количество строк по умолчанию для отображения.
Live Demo
import pandas as pd pd.describe_option("display.max_rows")
Его вывод выглядит следующим образом –
display.max_rows : int If max_rows is exceeded, switch to truncate view. Depending on 'large_repr', objects are either centrally truncated or printed as a summary view. 'None' value means unlimited. In case python/IPython is running in a terminal and `large_repr` equals 'truncate' this can be set to 0 and pandas will auto-detect the height of the terminal and print a truncated object which fits the screen height. The IPython notebook, IPython qtconsole, or IDLE do not run in a terminal and hence it is not possible to do correct auto-detection. [default: 60] [currently: 60]
option_context ()
Диспетчер контекста option_context используется для временного задания опции в операторе with . Значения параметров восстанавливаются автоматически при выходе из блока –
display.max_rows
Используя option_context (), мы можем временно установить значение.
Live Demo
import pandas as pd with pd.option_context("display.max_rows",10): print(pd.get_option("display.max_rows")) print(pd.get_option("display.max_rows"))
Его вывод выглядит следующим образом –
10 10
Видите, разница между первым и вторым оператором печати. Первый оператор печатает значение, установленное option_context (), которое является временным внутри самого контекста . После контекста with второй оператор print печатает настроенное значение.
Часто используемые параметры
| Sr.No | Параметр и описание |
|---|---|
| 1 |
display.max_rows Отображает максимальное количество строк для отображения |
| 2 |
2 display.max_columns Отображает максимальное количество столбцов для отображения |
| 3 |
display.expand_frame_repr Отображает кадры данных для растягивания страниц |
| 4 |
display.max_colwidth Отображает максимальную ширину столбца |
| 5 |
display.precision Отображает точность для десятичных чисел |
display.max_rows
Отображает максимальное количество строк для отображения
2 display.max_columns
Отображает максимальное количество столбцов для отображения
display.expand_frame_repr
Отображает кадры данных для растягивания страниц
display.max_colwidth
Отображает максимальную ширину столбца
display.precision
Отображает точность для десятичных чисел
Python Pandas – индексирование и выбор данных
В этой главе мы обсудим, как нарезать дату и нарезать кубиками, и, как правило, получаем подмножество объекта pandas.
Операторы индексации Python и NumPy “[]” и оператор атрибута “.” обеспечить быстрый и простой доступ к структурам данных Pandas в широком диапазоне вариантов использования. Тем не менее, поскольку тип данных, к которым осуществляется доступ, заранее неизвестен, непосредственное использование стандартных операторов имеет некоторые ограничения для оптимизации. Для производственного кода мы рекомендуем вам воспользоваться оптимизированными методами доступа к данным Pandas, описанными в этой главе.
Pandas теперь поддерживает три типа многоосевого индексирования; три типа упомянуты в следующей таблице:
| Sr.No | Индексирование и описание |
|---|---|
| 1 |
.loc () На основе метки |
| 2 |
.iloc () Целочисленный |
| 3 |
.ix () На основе меток и целых чисел |
.loc ()
На основе метки
.iloc ()
Целочисленный
.ix ()
На основе меток и целых чисел
.loc ()
Панды предоставляют различные методы для индексирования, основанного исключительно на метках . При нарезке начальная граница также включена. Целые числа являются допустимыми метками, но они относятся к метке, а не к позиции.
.loc () имеет несколько методов доступа, таких как –
- Одна скалярная метка
- Список ярлыков
- Ломтик объекта
- Логический массив
loc принимает два одиночных / list / range оператора, разделенных ‘,’. Первый указывает на строку, а второй указывает на столбцы.
Пример 1
Live Demo
#import the pandas library and aliasing as pd import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), index = ['a','b','c','d','e','f','g','h'], columns = ['A', 'B', 'C', 'D']) #select all rows for a specific column print df.loc[:,'A']
Его вывод выглядит следующим образом –
a 0.391548 b -0.070649 c -0.317212 d -2.162406 e 2.202797 f 0.613709 g 1.050559 h 1.122680 Name: A, dtype: float64
Пример 2
Live Demo
# import the pandas library and aliasing as pd import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), index = ['a','b','c','d','e','f','g','h'], columns = ['A', 'B', 'C', 'D']) # Select all rows for multiple columns, say list[] print df.loc[:,['A','C']]
Его вывод выглядит следующим образом –
A C a 0.391548 0.745623 b -0.070649 1.620406 c -0.317212 1.448365 d -2.162406 -0.873557 e 2.202797 0.528067 f 0.613709 0.286414 g 1.050559 0.216526 h 1.122680 -1.621420
Пример 3
Live Demo
# import the pandas library and aliasing as pd import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), index = ['a','b','c','d','e','f','g','h'], columns = ['A', 'B', 'C', 'D']) # Select few rows for multiple columns, say list[] print df.loc[['a','b','f','h'],['A','C']]
Его вывод выглядит следующим образом –
A C a 0.391548 0.745623 b -0.070649 1.620406 f 0.613709 0.286414 h 1.122680 -1.621420
Пример 4
Live Demo
# import the pandas library and aliasing as pd import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), index = ['a','b','c','d','e','f','g','h'], columns = ['A', 'B', 'C', 'D']) # Select range of rows for all columns print df.loc['a':'h']
Его вывод выглядит следующим образом –
A B C D a 0.391548 -0.224297 0.745623 0.054301 b -0.070649 -0.880130 1.620406 1.419743 c -0.317212 -1.929698 1.448365 0.616899 d -2.162406 0.614256 -0.873557 1.093958 e 2.202797 -2.315915 0.528067 0.612482 f 0.613709 -0.157674 0.286414 -0.500517 g 1.050559 -2.272099 0.216526 0.928449 h 1.122680 0.324368 -1.621420 -0.741470
Пример 5
Live Demo
# import the pandas library and aliasing as pd import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), index = ['a','b','c','d','e','f','g','h'], columns = ['A', 'B', 'C', 'D']) # for getting values with a boolean array print df.loc['a']>0
Его вывод выглядит следующим образом –
A False B True C False D False Name: a, dtype: bool
.iloc ()
Панды предоставляют различные методы для получения чисто целочисленной индексации. Как и python и numpy, это индексация на основе 0 .
Различные способы доступа следующие:
- Целое число
- Список целых чисел
- Диапазон значений
Пример 1
Live Demo
# import the pandas library and aliasing as pd import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), columns = ['A', 'B', 'C', 'D']) # select all rows for a specific column print df.iloc[:4]
Его вывод выглядит следующим образом –
A B C D 0 0.699435 0.256239 -1.270702 -0.645195 1 -0.685354 0.890791 -0.813012 0.631615 2 -0.783192 -0.531378 0.025070 0.230806 3 0.539042 -1.284314 0.826977 -0.026251
Пример 2
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), columns = ['A', 'B', 'C', 'D']) # Integer slicing print df.iloc[:4] print df.iloc[1:5, 2:4]
Его вывод выглядит следующим образом –
A B C D
0 0.699435 0.256239 -1.270702 -0.645195
1 -0.685354 0.890791 -0.813012 0.631615
2 -0.783192 -0.531378 0.025070 0.230806
3 0.539042 -1.284314 0.826977 -0.026251
C D
1 -0.813012 0.631615
2 0.025070 0.230806
3 0.826977 -0.026251
4 1.423332 1.130568
Пример 3
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), columns = ['A', 'B', 'C', 'D']) # Slicing through list of values print df.iloc[[1, 3, 5], [1, 3]] print df.iloc[1:3, :] print df.iloc[:,1:3]
Его вывод выглядит следующим образом –
B D
1 0.890791 0.631615
3 -1.284314 -0.026251
5 -0.512888 -0.518930
A B C D
1 -0.685354 0.890791 -0.813012 0.631615
2 -0.783192 -0.531378 0.025070 0.230806
B C
0 0.256239 -1.270702
1 0.890791 -0.813012
2 -0.531378 0.025070
3 -1.284314 0.826977
4 -0.460729 1.423332
5 -0.512888 0.581409
6 -1.204853 0.098060
7 -0.947857 0.641358
.ix ()
Помимо чисто меток и целых чисел, Pandas предоставляет гибридный метод для выбора и поднабора объекта с помощью оператора .ix ().
Пример 1
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), columns = ['A', 'B', 'C', 'D']) # Integer slicing print df.ix[:4]
Его вывод выглядит следующим образом –
A B C D 0 0.699435 0.256239 -1.270702 -0.645195 1 -0.685354 0.890791 -0.813012 0.631615 2 -0.783192 -0.531378 0.025070 0.230806 3 0.539042 -1.284314 0.826977 -0.026251
Пример 2
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), columns = ['A', 'B', 'C', 'D']) # Index slicing print df.ix[:,'A']
Его вывод выглядит следующим образом –
0 0.699435 1 -0.685354 2 -0.783192 3 0.539042 4 -1.044209 5 -1.415411 6 1.062095 7 0.994204 Name: A, dtype: float64
Использование обозначений
Получение значений из объекта Pandas с многоосевым индексированием использует следующую запись:
| объект | индексаторы | Тип возврата |
|---|---|---|
| Серии | s.loc [индексатор] | Скалярное значение |
| DataFrame | df.loc [row_index, col_index] | Серийный объект |
| панель | p.loc [item_index, major_index, minor_index] | p.loc [item_index, major_index, minor_index] |
Примечание. .Iloc () & .ix () применяет те же параметры индексации и Возвращаемое значение.
Давайте теперь посмотрим, как каждая операция может быть выполнена с объектом DataFrame. Мы будем использовать основной оператор индексации ‘[]’ –
Пример 1
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), columns = ['A', 'B', 'C', 'D']) print df['A']
Его вывод выглядит следующим образом –
0 -0.478893 1 0.391931 2 0.336825 3 -1.055102 4 -0.165218 5 -0.328641 6 0.567721 7 -0.759399 Name: A, dtype: float64
Примечание. Мы можем передать список значений [], чтобы выбрать эти столбцы.
Пример 2
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), columns = ['A', 'B', 'C', 'D']) print df[['A','B']]
Его вывод выглядит следующим образом –
A B 0 -0.478893 -0.606311 1 0.391931 -0.949025 2 0.336825 0.093717 3 -1.055102 -0.012944 4 -0.165218 1.550310 5 -0.328641 -0.226363 6 0.567721 -0.312585 7 -0.759399 -0.372696
Пример 3
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), columns = ['A', 'B', 'C', 'D']) print df[2:2]
Его вывод выглядит следующим образом –
Columns: [A, B, C, D] Index: []
Доступ к атрибутам
Столбцы можно выбрать с помощью оператора атрибута ‘.’.
пример
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(8, 4), columns = ['A', 'B', 'C', 'D']) print df.A
Его вывод выглядит следующим образом –
0 -0.478893 1 0.391931 2 0.336825 3 -1.055102 4 -0.165218 5 -0.328641 6 0.567721 7 -0.759399 Name: A, dtype: float64
Python Pandas – Статистические Функции
Статистические методы помогают в понимании и анализе поведения данных. Теперь мы изучим несколько статистических функций, которые мы можем применить к объектам Pandas.
Percent_change
Series, DatFrames и Panel, все имеют функцию pct_change () . Эта функция сравнивает каждый элемент с его предыдущим элементом и вычисляет процент изменений.
Live Demo
import pandas as pd import numpy as np s = pd.Series([1,2,3,4,5,4]) print s.pct_change() df = pd.DataFrame(np.random.randn(5, 2)) print df.pct_change()
Его вывод выглядит следующим образом –
0 NaN
1 1.000000
2 0.500000
3 0.333333
4 0.250000
5 -0.200000
dtype: float64
0 1
0 NaN NaN
1 -15.151902 0.174730
2 -0.746374 -1.449088
3 -3.582229 -3.165836
4 15.601150 -1.860434
По умолчанию pct_change () работает со столбцами; если вы хотите применить ту же строку, используйте аргумент axis = 1 () .
ковариации
Ковариация применяется к данным ряда. Объект Series имеет метод cov для вычисления ковариации между объектами серии. NA будет исключен автоматически.
Cov Series
Live Demo
import pandas as pd import numpy as np s1 = pd.Series(np.random.randn(10)) s2 = pd.Series(np.random.randn(10)) print s1.cov(s2)
Его вывод выглядит следующим образом –
-0.12978405324
Метод ковариации при применении к DataFrame вычисляет значение cov для всех столбцов.
Live Demo
import pandas as pd import numpy as np frame = pd.DataFrame(np.random.randn(10, 5), columns=['a', 'b', 'c', 'd', 'e']) print frame['a'].cov(frame['b']) print frame.cov()
Его вывод выглядит следующим образом –
-0.58312921152741437
a b c d e
a 1.780628 -0.583129 -0.185575 0.003679 -0.136558
b -0.583129 1.297011 0.136530 -0.523719 0.251064
c -0.185575 0.136530 0.915227 -0.053881 -0.058926
d 0.003679 -0.523719 -0.053881 1.521426 -0.487694
e -0.136558 0.251064 -0.058926 -0.487694 0.960761
Примечание. Обратите внимание на значение cov между столбцами a и b в первом операторе, и это же значение, возвращаемое параметром cov в DataFrame.
корреляция
Корреляция показывает линейные отношения между любыми двумя массивами значений (рядами). Есть несколько методов для вычисления корреляции, таких как Pearson (по умолчанию), Spearman и Kendall.
Live Demo
import pandas as pd import numpy as np frame = pd.DataFrame(np.random.randn(10, 5), columns=['a', 'b', 'c', 'd', 'e']) print frame['a'].corr(frame['b']) print frame.corr()
Его вывод выглядит следующим образом –
-0.383712785514
a b c d e
a 1.000000 -0.383713 -0.145368 0.002235 -0.104405
b -0.383713 1.000000 0.125311 -0.372821 0.224908
c -0.145368 0.125311 1.000000 -0.045661 -0.062840
d 0.002235 -0.372821 -0.045661 1.000000 -0.403380
e -0.104405 0.224908 -0.062840 -0.403380 1.000000
Если в DataFrame присутствует какой-либо нечисловой столбец, он автоматически исключается.
Рейтинг данных
Ранжирование данных производит ранжирование для каждого элемента в массиве элементов. В случае связей присваивает средний ранг.
Live Demo
import pandas as pd import numpy as np s = pd.Series(np.random.np.random.randn(5), index=list('abcde')) s['d'] = s['b'] # so there's a tie print s.rank()
Его вывод выглядит следующим образом –
a 1.0 b 3.5 c 2.0 d 3.5 e 5.0 dtype: float64
Ранг необязательно принимает параметр по возрастанию, который по умолчанию имеет значение true; когда ложь, данные ранжируются в обратном порядке, с большими значениями присваивается меньший ранг.
Ранг поддерживает различные методы разрыва связей, указанные параметром метода –
-
средний – средний ранг связанной группы
-
min – самый низкий ранг в группе
-
max – высший ранг в группе
-
first – ранги присваиваются в порядке их появления в массиве
средний – средний ранг связанной группы
min – самый низкий ранг в группе
max – высший ранг в группе
first – ранги присваиваются в порядке их появления в массиве
Python Pandas – оконные функции
Для работы с числовыми данными Pandas предлагает несколько вариантов, таких как скользящее, расширяющееся и экспоненциально перемещающееся веса для статистики окна. Среди них сумма, среднее, медиана, дисперсия, ковариация, корреляция и т. Д.
Теперь мы узнаем, как каждый из них может быть применен к объектам DataFrame.
Функция .rolling ()
Эта функция может быть применена к серии данных. Укажите аргумент window = n и примените к нему соответствующую статистическую функцию.
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(10, 4), index = pd.date_range('1/1/2000', periods=10), columns = ['A', 'B', 'C', 'D']) print df.rolling(window=3).mean()
Его вывод выглядит следующим образом –
A B C D 2000-01-01 NaN NaN NaN NaN 2000-01-02 NaN NaN NaN NaN 2000-01-03 0.434553 -0.667940 -1.051718 -0.826452 2000-01-04 0.628267 -0.047040 -0.287467 -0.161110 2000-01-05 0.398233 0.003517 0.099126 -0.405565 2000-01-06 0.641798 0.656184 -0.322728 0.428015 2000-01-07 0.188403 0.010913 -0.708645 0.160932 2000-01-08 0.188043 -0.253039 -0.818125 -0.108485 2000-01-09 0.682819 -0.606846 -0.178411 -0.404127 2000-01-10 0.688583 0.127786 0.513832 -1.067156
Примечание. Поскольку размер окна равен 3, для первых двух элементов используются значения NULL, а для третьего значение будет средним значением элементов n , n-1 и n-2 . Таким образом, мы также можем применять различные функции, как указано выше.
Функция .expanding ()
Эта функция может быть применена к серии данных. Укажите аргумент min_periods = n и примените к нему соответствующую статистическую функцию.
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(10, 4), index = pd.date_range('1/1/2000', periods=10), columns = ['A', 'B', 'C', 'D']) print df.expanding(min_periods=3).mean()
Его вывод выглядит следующим образом –
A B C D 2000-01-01 NaN NaN NaN NaN 2000-01-02 NaN NaN NaN NaN 2000-01-03 0.434553 -0.667940 -1.051718 -0.826452 2000-01-04 0.743328 -0.198015 -0.852462 -0.262547 2000-01-05 0.614776 -0.205649 -0.583641 -0.303254 2000-01-06 0.538175 -0.005878 -0.687223 -0.199219 2000-01-07 0.505503 -0.108475 -0.790826 -0.081056 2000-01-08 0.454751 -0.223420 -0.671572 -0.230215 2000-01-09 0.586390 -0.206201 -0.517619 -0.267521 2000-01-10 0.560427 -0.037597 -0.399429 -0.376886
Функция .ewm ()
EWM применяется к серии данных. Укажите любой аргумент com, span, halflife и примените к нему соответствующую статистическую функцию. Он присваивает веса экспоненциально.
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(10, 4), index = pd.date_range('1/1/2000', periods=10), columns = ['A', 'B', 'C', 'D']) print df.ewm(com=0.5).mean()
Его вывод выглядит следующим образом –
A B C D 2000-01-01 1.088512 -0.650942 -2.547450 -0.566858 2000-01-02 0.865131 -0.453626 -1.137961 0.058747 2000-01-03 -0.132245 -0.807671 -0.308308 -1.491002 2000-01-04 1.084036 0.555444 -0.272119 0.480111 2000-01-05 0.425682 0.025511 0.239162 -0.153290 2000-01-06 0.245094 0.671373 -0.725025 0.163310 2000-01-07 0.288030 -0.259337 -1.183515 0.473191 2000-01-08 0.162317 -0.771884 -0.285564 -0.692001 2000-01-09 1.147156 -0.302900 0.380851 -0.607976 2000-01-10 0.600216 0.885614 0.569808 -1.110113
Оконные функции в основном используются для нахождения трендов в данных графически путем сглаживания кривой. Если в каждодневных данных имеется много вариаций и доступно много точек данных, то выборка и построение графиков – это один метод, а применение оконных вычислений и построение графика для результатов – еще один метод. Этими методами мы можем сгладить кривую или тренд.
Питон Панды – Агрегации
После создания объектов прокрутки, развертывания и ewm доступны несколько методов для агрегирования данных.
Применение агрегаций в DataFrame
Давайте создадим DataFrame и применим к нему агрегаты.
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(10, 4), index = pd.date_range('1/1/2000', periods=10), columns = ['A', 'B', 'C', 'D']) print df r = df.rolling(window=3,min_periods=1) print r
Его вывод выглядит следующим образом –
A B C D 2000-01-01 1.088512 -0.650942 -2.547450 -0.566858 2000-01-02 0.790670 -0.387854 -0.668132 0.267283 2000-01-03 -0.575523 -0.965025 0.060427 -2.179780 2000-01-04 1.669653 1.211759 -0.254695 1.429166 2000-01-05 0.100568 -0.236184 0.491646 -0.466081 2000-01-06 0.155172 0.992975 -1.205134 0.320958 2000-01-07 0.309468 -0.724053 -1.412446 0.627919 2000-01-08 0.099489 -1.028040 0.163206 -1.274331 2000-01-09 1.639500 -0.068443 0.714008 -0.565969 2000-01-10 0.326761 1.479841 0.664282 -1.361169 Rolling [window=3,min_periods=1,center=False,axis=0]
Мы можем агрегировать, передавая функцию всему DataFrame или выбирая столбец с помощью стандартного метода get item .
Применить агрегацию на весь фрейм данных
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(10, 4), index = pd.date_range('1/1/2000', periods=10), columns = ['A', 'B', 'C', 'D']) print df r = df.rolling(window=3,min_periods=1) print r.aggregate(np.sum)
Его вывод выглядит следующим образом –
A B C D
2000-01-01 1.088512 -0.650942 -2.547450 -0.566858
2000-01-02 1.879182 -1.038796 -3.215581 -0.299575
2000-01-03 1.303660 -2.003821 -3.155154 -2.479355
2000-01-04 1.884801 -0.141119 -0.862400 -0.483331
2000-01-05 1.194699 0.010551 0.297378 -1.216695
2000-01-06 1.925393 1.968551 -0.968183 1.284044
2000-01-07 0.565208 0.032738 -2.125934 0.482797
2000-01-08 0.564129 -0.759118 -2.454374 -0.325454
2000-01-09 2.048458 -1.820537 -0.535232 -1.212381
2000-01-10 2.065750 0.383357 1.541496 -3.201469
A B C D
2000-01-01 1.088512 -0.650942 -2.547450 -0.566858
2000-01-02 1.879182 -1.038796 -3.215581 -0.299575
2000-01-03 1.303660 -2.003821 -3.155154 -2.479355
2000-01-04 1.884801 -0.141119 -0.862400 -0.483331
2000-01-05 1.194699 0.010551 0.297378 -1.216695
2000-01-06 1.925393 1.968551 -0.968183 1.284044
2000-01-07 0.565208 0.032738 -2.125934 0.482797
2000-01-08 0.564129 -0.759118 -2.454374 -0.325454
2000-01-09 2.048458 -1.820537 -0.535232 -1.212381
2000-01-10 2.065750 0.383357 1.541496 -3.201469
Применить агрегацию к одному столбцу информационного кадра
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(10, 4), index = pd.date_range('1/1/2000', periods=10), columns = ['A', 'B', 'C', 'D']) print df r = df.rolling(window=3,min_periods=1) print r['A'].aggregate(np.sum)
Его вывод выглядит следующим образом –
A B C D 2000-01-01 1.088512 -0.650942 -2.547450 -0.566858 2000-01-02 1.879182 -1.038796 -3.215581 -0.299575 2000-01-03 1.303660 -2.003821 -3.155154 -2.479355 2000-01-04 1.884801 -0.141119 -0.862400 -0.483331 2000-01-05 1.194699 0.010551 0.297378 -1.216695 2000-01-06 1.925393 1.968551 -0.968183 1.284044 2000-01-07 0.565208 0.032738 -2.125934 0.482797 2000-01-08 0.564129 -0.759118 -2.454374 -0.325454 2000-01-09 2.048458 -1.820537 -0.535232 -1.212381 2000-01-10 2.065750 0.383357 1.541496 -3.201469 2000-01-01 1.088512 2000-01-02 1.879182 2000-01-03 1.303660 2000-01-04 1.884801 2000-01-05 1.194699 2000-01-06 1.925393 2000-01-07 0.565208 2000-01-08 0.564129 2000-01-09 2.048458 2000-01-10 2.065750 Freq: D, Name: A, dtype: float64
Применить агрегацию к нескольким столбцам в DataFrame
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(10, 4), index = pd.date_range('1/1/2000', periods=10), columns = ['A', 'B', 'C', 'D']) print df r = df.rolling(window=3,min_periods=1) print r[['A','B']].aggregate(np.sum)
Его вывод выглядит следующим образом –
A B C D
2000-01-01 1.088512 -0.650942 -2.547450 -0.566858
2000-01-02 1.879182 -1.038796 -3.215581 -0.299575
2000-01-03 1.303660 -2.003821 -3.155154 -2.479355
2000-01-04 1.884801 -0.141119 -0.862400 -0.483331
2000-01-05 1.194699 0.010551 0.297378 -1.216695
2000-01-06 1.925393 1.968551 -0.968183 1.284044
2000-01-07 0.565208 0.032738 -2.125934 0.482797
2000-01-08 0.564129 -0.759118 -2.454374 -0.325454
2000-01-09 2.048458 -1.820537 -0.535232 -1.212381
2000-01-10 2.065750 0.383357 1.541496 -3.201469
A B
2000-01-01 1.088512 -0.650942
2000-01-02 1.879182 -1.038796
2000-01-03 1.303660 -2.003821
2000-01-04 1.884801 -0.141119
2000-01-05 1.194699 0.010551
2000-01-06 1.925393 1.968551
2000-01-07 0.565208 0.032738
2000-01-08 0.564129 -0.759118
2000-01-09 2.048458 -1.820537
2000-01-10 2.065750 0.383357
Применить несколько функций к одному столбцу DataFrame
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(10, 4), index = pd.date_range('1/1/2000', periods=10), columns = ['A', 'B', 'C', 'D']) print df r = df.rolling(window=3,min_periods=1) print r['A'].aggregate([np.sum,np.mean])
Его вывод выглядит следующим образом –
A B C D
2000-01-01 1.088512 -0.650942 -2.547450 -0.566858
2000-01-02 1.879182 -1.038796 -3.215581 -0.299575
2000-01-03 1.303660 -2.003821 -3.155154 -2.479355
2000-01-04 1.884801 -0.141119 -0.862400 -0.483331
2000-01-05 1.194699 0.010551 0.297378 -1.216695
2000-01-06 1.925393 1.968551 -0.968183 1.284044
2000-01-07 0.565208 0.032738 -2.125934 0.482797
2000-01-08 0.564129 -0.759118 -2.454374 -0.325454
2000-01-09 2.048458 -1.820537 -0.535232 -1.212381
2000-01-10 2.065750 0.383357 1.541496 -3.201469
sum mean
2000-01-01 1.088512 1.088512
2000-01-02 1.879182 0.939591
2000-01-03 1.303660 0.434553
2000-01-04 1.884801 0.628267
2000-01-05 1.194699 0.398233
2000-01-06 1.925393 0.641798
2000-01-07 0.565208 0.188403
2000-01-08 0.564129 0.188043
2000-01-09 2.048458 0.682819
2000-01-10 2.065750 0.688583
Применение нескольких функций к нескольким столбцам в DataFrame
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(10, 4), index = pd.date_range('1/1/2000', periods=10), columns = ['A', 'B', 'C', 'D']) print df r = df.rolling(window=3,min_periods=1) print r[['A','B']].aggregate([np.sum,np.mean])
Его вывод выглядит следующим образом –
A B C D
2000-01-01 1.088512 -0.650942 -2.547450 -0.566858
2000-01-02 1.879182 -1.038796 -3.215581 -0.299575
2000-01-03 1.303660 -2.003821 -3.155154 -2.479355
2000-01-04 1.884801 -0.141119 -0.862400 -0.483331
2000-01-05 1.194699 0.010551 0.297378 -1.216695
2000-01-06 1.925393 1.968551 -0.968183 1.284044
2000-01-07 0.565208 0.032738 -2.125934 0.482797
2000-01-08 0.564129 -0.759118 -2.454374 -0.325454
2000-01-09 2.048458 -1.820537 -0.535232 -1.212381
2000-01-10 2.065750 0.383357 1.541496 -3.201469
A B
sum mean sum mean
2000-01-01 1.088512 1.088512 -0.650942 -0.650942
2000-01-02 1.879182 0.939591 -1.038796 -0.519398
2000-01-03 1.303660 0.434553 -2.003821 -0.667940
2000-01-04 1.884801 0.628267 -0.141119 -0.047040
2000-01-05 1.194699 0.398233 0.010551 0.003517
2000-01-06 1.925393 0.641798 1.968551 0.656184
2000-01-07 0.565208 0.188403 0.032738 0.010913
2000-01-08 0.564129 0.188043 -0.759118 -0.253039
2000-01-09 2.048458 0.682819 -1.820537 -0.606846
2000-01-10 2.065750 0.688583 0.383357 0.127786
Применение различных функций к различным столбцам информационного кадра
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(3, 4), index = pd.date_range('1/1/2000', periods=3), columns = ['A', 'B', 'C', 'D']) print df r = df.rolling(window=3,min_periods=1) print r.aggregate({'A' : np.sum,'B' : np.mean})
Его вывод выглядит следующим образом –
A B C D
2000-01-01 -1.575749 -1.018105 0.317797 0.545081
2000-01-02 -0.164917 -1.361068 0.258240 1.113091
2000-01-03 1.258111 1.037941 -0.047487 0.867371
A B
2000-01-01 -1.575749 -1.018105
2000-01-02 -1.740666 -1.189587
2000-01-03 -0.482555 -0.447078
Python Pandas – недостающие данные
Отсутствие данных всегда является проблемой в реальных сценариях. Такие области, как машинное обучение и интеллектуальный анализ данных, сталкиваются с серьезными проблемами в точности их прогнозирования модели из-за низкого качества данных, вызванного отсутствием значений. В этих областях обработка недостающего значения является основной целью, чтобы сделать их модели более точными и достоверными.
Когда и почему пропускаются данные?
Давайте рассмотрим онлайн-опрос для продукта. Часто люди не делятся всей информацией, связанной с ними. Немногие люди делятся своим опытом, но не знают, как долго они используют продукт; немногие люди рассказывают, как долго они используют продукт, их опыт, но не их контактную информацию. Таким образом, так или иначе часть данных всегда отсутствует, и это очень часто встречается в реальном времени.
Давайте теперь посмотрим, как мы можем обрабатывать пропущенные значения (скажем, NA или NaN), используя Pandas.
Live Demo
# import the pandas library import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5, 3), index=['a', 'c', 'e', 'f', 'h'],columns=['one', 'two', 'three']) df = df.reindex(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']) print df
Его вывод выглядит следующим образом –
one two three a 0.077988 0.476149 0.965836 b NaN NaN NaN c -0.390208 -0.551605 -2.301950 d NaN NaN NaN e -2.000303 -0.788201 1.510072 f -0.930230 -0.670473 1.146615 g NaN NaN NaN h 0.085100 0.532791 0.887415
Используя переиндексацию, мы создали DataFrame с пропущенными значениями. На выходе NaN означает не число.
Проверить пропущенные значения
Чтобы упростить обнаружение пропущенных значений (и в разных типах массива), Pandas предоставляет функции isnull () и notnull () , которые также являются методами для объектов Series и DataFrame –
Пример 1
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5, 3), index=['a', 'c', 'e', 'f', 'h'],columns=['one', 'two', 'three']) df = df.reindex(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']) print df['one'].isnull()
Его вывод выглядит следующим образом –
a False b True c False d True e False f False g True h False Name: one, dtype: bool
Пример 2
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5, 3), index=['a', 'c', 'e', 'f', 'h'],columns=['one', 'two', 'three']) df = df.reindex(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']) print df['one'].notnull()
Его вывод выглядит следующим образом –
a True b False c True d False e True f True g False h True Name: one, dtype: bool
Расчеты с отсутствующими данными
- При суммировании данных NA будет рассматриваться как ноль
- Если все данные NA, то результатом будет NA
Пример 1
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5, 3), index=['a', 'c', 'e', 'f', 'h'],columns=['one', 'two', 'three']) df = df.reindex(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']) print df['one'].sum()
Его вывод выглядит следующим образом –
2.02357685917
Пример 2
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(index=[0,1,2,3,4,5],columns=['one','two']) print df['one'].sum()
Его вывод выглядит следующим образом –
nan
Очистка / заполнение недостающих данных
Панды предоставляет различные методы для очистки пропущенных значений. Функция fillna может «заполнять» значения NA ненулевыми данными несколькими способами, которые мы иллюстрировали в следующих разделах.
Заменить NaN скалярным значением
Следующая программа показывает, как вы можете заменить «NaN» на «0».
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(3, 3), index=['a', 'c', 'e'],columns=['one', 'two', 'three']) df = df.reindex(['a', 'b', 'c']) print df print ("NaN replaced with '0':") print df.fillna(0)
Его вывод выглядит следующим образом –
one two three
a -0.576991 -0.741695 0.553172
b NaN NaN NaN
c 0.744328 -1.735166 1.749580
NaN replaced with '0':
one two three
a -0.576991 -0.741695 0.553172
b 0.000000 0.000000 0.000000
c 0.744328 -1.735166 1.749580
Здесь мы заполняем значение ноль; вместо этого мы можем также заполнить любым другим значением.
Заполнить NA Вперед и Назад
Используя концепции заполнения, обсуждаемые в главе переиндексации, мы заполним пропущенные значения.
| Sr.No | Метод и действие |
|---|---|
| 1 |
колодки / заполнения Методы заполнения Вперед |
| 2 |
bfill / засыпки Заполнить методы назад |
колодки / заполнения
Методы заполнения Вперед
bfill / засыпки
Заполнить методы назад
Пример 1
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5, 3), index=['a', 'c', 'e', 'f', 'h'],columns=['one', 'two', 'three']) df = df.reindex(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']) print df.fillna(method='pad')
Его вывод выглядит следующим образом –
one two three a 0.077988 0.476149 0.965836 b 0.077988 0.476149 0.965836 c -0.390208 -0.551605 -2.301950 d -0.390208 -0.551605 -2.301950 e -2.000303 -0.788201 1.510072 f -0.930230 -0.670473 1.146615 g -0.930230 -0.670473 1.146615 h 0.085100 0.532791 0.887415
Пример 2
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5, 3), index=['a', 'c', 'e', 'f', 'h'],columns=['one', 'two', 'three']) df = df.reindex(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']) print df.fillna(method='backfill')
Его вывод выглядит следующим образом –
one two three a 0.077988 0.476149 0.965836 b -0.390208 -0.551605 -2.301950 c -0.390208 -0.551605 -2.301950 d -2.000303 -0.788201 1.510072 e -2.000303 -0.788201 1.510072 f -0.930230 -0.670473 1.146615 g 0.085100 0.532791 0.887415 h 0.085100 0.532791 0.887415
Отбросьте недостающие значения
Если вы хотите просто исключить отсутствующие значения, используйте функцию dropna вместе с аргументом оси . По умолчанию ось = 0, то есть вдоль строки, что означает, что если любое значение в строке равно NA, тогда вся строка исключается.
Пример 1
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5, 3), index=['a', 'c', 'e', 'f', 'h'],columns=['one', 'two', 'three']) df = df.reindex(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']) print df.dropna()
Его вывод выглядит следующим образом –
one two three a 0.077988 0.476149 0.965836 c -0.390208 -0.551605 -2.301950 e -2.000303 -0.788201 1.510072 f -0.930230 -0.670473 1.146615 h 0.085100 0.532791 0.887415
Пример 2
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(5, 3), index=['a', 'c', 'e', 'f', 'h'],columns=['one', 'two', 'three']) df = df.reindex(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']) print df.dropna(axis=1)
Его вывод выглядит следующим образом –
Empty DataFrame Columns: [ ] Index: [a, b, c, d, e, f, g, h]
Заменить отсутствующие (или) общие значения
Много раз, мы должны заменить общее значение некоторым определенным значением. Мы можем добиться этого, применив метод замены.
Замена NA скалярным значением является эквивалентным поведением функции fillna () .
Пример 1
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame({'one':[10,20,30,40,50,2000], 'two':[1000,0,30,40,50,60]}) print df.replace({1000:10,2000:60})
Его вывод выглядит следующим образом –
one two 0 10 10 1 20 0 2 30 30 3 40 40 4 50 50 5 60 60
Пример 2
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame({'one':[10,20,30,40,50,2000], 'two':[1000,0,30,40,50,60]}) print df.replace({1000:10,2000:60})
Его вывод выглядит следующим образом –
one two 0 10 10 1 20 0 2 30 30 3 40 40 4 50 50 5 60 60
Python Pandas – GroupBy
Любая групповая операция включает в себя одну из следующих операций с исходным объектом. Они –
-
Разделение объекта
-
Применение функции
-
Объединение результатов
Разделение объекта
Применение функции
Объединение результатов
Во многих ситуациях мы разделяем данные на наборы и применяем некоторые функциональные возможности к каждому подмножеству. В функциональности применения мы можем выполнить следующие операции:
-
Агрегация – вычисление сводной статистики
-
Преобразование – выполнить некоторую групповую операцию
-
Фильтрация – отбрасывание данных с некоторым условием
Агрегация – вычисление сводной статистики
Преобразование – выполнить некоторую групповую операцию
Фильтрация – отбрасывание данных с некоторым условием
Теперь давайте создадим объект DataFrame и выполним все операции над ним:
Live Demo
#import the pandas library import pandas as pd ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings', 'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'], 'Rank': [1, 2, 2, 3, 3,4 ,1 ,1,2 , 4,1,2], 'Year': [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017], 'Points':[876,789,863,673,741,812,756,788,694,701,804,690]} df = pd.DataFrame(ipl_data) print df
Его вывод выглядит следующим образом –
Points Rank Team Year 0 876 1 Riders 2014 1 789 2 Riders 2015 2 863 2 Devils 2014 3 673 3 Devils 2015 4 741 3 Kings 2014 5 812 4 kings 2015 6 756 1 Kings 2016 7 788 1 Kings 2017 8 694 2 Riders 2016 9 701 4 Royals 2014 10 804 1 Royals 2015 11 690 2 Riders 2017
Разделить данные на группы
Объект Панды можно разбить на любой из своих объектов. Есть несколько способов разбить объект, как –
- obj.groupby ( ‘ключ’)
- obj.groupby ([ ‘ключ1’, ‘ключ2’])
- obj.groupby (ключ, ось = 1)
Давайте теперь посмотрим, как объекты группировки могут применяться к объекту DataFrame.
пример
Live Demo
# import the pandas library import pandas as pd ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings', 'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'], 'Rank': [1, 2, 2, 3, 3,4 ,1 ,1,2 , 4,1,2], 'Year': [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017], 'Points':[876,789,863,673,741,812,756,788,694,701,804,690]} df = pd.DataFrame(ipl_data) print df.groupby('Team')
Его вывод выглядит следующим образом –
<pandas.core.groupby.DataFrameGroupBy object at 0x7fa46a977e50>
Просмотр групп
Live Demo
# import the pandas library import pandas as pd ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings', 'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'], 'Rank': [1, 2, 2, 3, 3,4 ,1 ,1,2 , 4,1,2], 'Year': [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017], 'Points':[876,789,863,673,741,812,756,788,694,701,804,690]} df = pd.DataFrame(ipl_data) print df.groupby('Team').groups
Его вывод выглядит следующим образом –
{'Kings': Int64Index([4, 6, 7], dtype='int64'),
'Devils': Int64Index([2, 3], dtype='int64'),
'Riders': Int64Index([0, 1, 8, 11], dtype='int64'),
'Royals': Int64Index([9, 10], dtype='int64'),
'kings' : Int64Index([5], dtype='int64')}
пример
Группировать по нескольким столбцам –
Live Demo
# import the pandas library import pandas as pd ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings', 'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'], 'Rank': [1, 2, 2, 3, 3,4 ,1 ,1,2 , 4,1,2], 'Year': [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017], 'Points':[876,789,863,673,741,812,756,788,694,701,804,690]} df = pd.DataFrame(ipl_data) print df.groupby(['Team','Year']).groups
Его вывод выглядит следующим образом –
{('Kings', 2014): Int64Index([4], dtype='int64'),
('Royals', 2014): Int64Index([9], dtype='int64'),
('Riders', 2014): Int64Index([0], dtype='int64'),
('Riders', 2015): Int64Index([1], dtype='int64'),
('Kings', 2016): Int64Index([6], dtype='int64'),
('Riders', 2016): Int64Index([8], dtype='int64'),
('Riders', 2017): Int64Index([11], dtype='int64'),
('Devils', 2014): Int64Index([2], dtype='int64'),
('Devils', 2015): Int64Index([3], dtype='int64'),
('kings', 2015): Int64Index([5], dtype='int64'),
('Royals', 2015): Int64Index([10], dtype='int64'),
('Kings', 2017): Int64Index([7], dtype='int64')}
Итерация по группам
Имея объект groupby , мы можем выполнить итерацию по объекту, похожему на itertools.obj.
Live Demo
# import the pandas library import pandas as pd ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings', 'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'], 'Rank': [1, 2, 2, 3, 3,4 ,1 ,1,2 , 4,1,2], 'Year': [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017], 'Points':[876,789,863,673,741,812,756,788,694,701,804,690]} df = pd.DataFrame(ipl_data) grouped = df.groupby('Year') for name,group in grouped: print name print group
Его вывод выглядит следующим образом –
2014 Points Rank Team Year 0 876 1 Riders 2014 2 863 2 Devils 2014 4 741 3 Kings 2014 9 701 4 Royals 2014 2015 Points Rank Team Year 1 789 2 Riders 2015 3 673 3 Devils 2015 5 812 4 kings 2015 10 804 1 Royals 2015 2016 Points Rank Team Year 6 756 1 Kings 2016 8 694 2 Riders 2016 2017 Points Rank Team Year 7 788 1 Kings 2017 11 690 2 Riders 2017
По умолчанию объект groupby имеет то же имя метки, что и имя группы.
Выберите группу
Используя метод get_group () , мы можем выбрать одну группу.
Live Demo
# import the pandas library import pandas as pd ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings', 'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'], 'Rank': [1, 2, 2, 3, 3,4 ,1 ,1,2 , 4,1,2], 'Year': [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017], 'Points':[876,789,863,673,741,812,756,788,694,701,804,690]} df = pd.DataFrame(ipl_data) grouped = df.groupby('Year') print grouped.get_group(2014)
Его вывод выглядит следующим образом –
Points Rank Team Year 0 876 1 Riders 2014 2 863 2 Devils 2014 4 741 3 Kings 2014 9 701 4 Royals 2014
Скопления
Агрегированная функция возвращает одно агрегированное значение для каждой группы. После создания группы по объекту можно выполнить несколько операций агрегирования сгруппированных данных.
Очевидным является агрегация с помощью агрегатного или эквивалентного метода агг.
Live Demo
# import the pandas library import pandas as pd import numpy as np ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings', 'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'], 'Rank': [1, 2, 2, 3, 3,4 ,1 ,1,2 , 4,1,2], 'Year': [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017], 'Points':[876,789,863,673,741,812,756,788,694,701,804,690]} df = pd.DataFrame(ipl_data) grouped = df.groupby('Year') print grouped['Points'].agg(np.mean)
Его вывод выглядит следующим образом –
Year 2014 795.25 2015 769.50 2016 725.00 2017 739.00 Name: Points, dtype: float64
Еще один способ увидеть размер каждой группы – применить функцию size () –
Live Demo
import pandas as pd import numpy as np ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings', 'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'], 'Rank': [1, 2, 2, 3, 3,4 ,1 ,1,2 , 4,1,2], 'Year': [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017], 'Points':[876,789,863,673,741,812,756,788,694,701,804,690]} df = pd.DataFrame(ipl_data) Attribute Access in Python Pandas grouped = df.groupby('Team') print grouped.agg(np.size)
Его вывод выглядит следующим образом –
Points Rank Year Team Devils 2 2 2 Kings 3 3 3 Riders 4 4 4 Royals 2 2 2 kings 1 1 1
Применение нескольких функций агрегации одновременно
В сгруппированных сериях вы также можете передать список или набор функций для агрегирования и сгенерировать DataFrame в качестве вывода –
Live Demo
# import the pandas library import pandas as pd import numpy as np ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings', 'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'], 'Rank': [1, 2, 2, 3, 3,4 ,1 ,1,2 , 4,1,2], 'Year': [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017], 'Points':[876,789,863,673,741,812,756,788,694,701,804,690]} df = pd.DataFrame(ipl_data) grouped = df.groupby('Team') print grouped['Points'].agg([np.sum, np.mean, np.std])
Его вывод выглядит следующим образом –
Team sum mean std Devils 1536 768.000000 134.350288 Kings 2285 761.666667 24.006943 Riders 3049 762.250000 88.567771 Royals 1505 752.500000 72.831998 kings 812 812.000000 NaN
Трансформации
Преобразование для группы или столбца возвращает объект, индексированный по тому же размеру, что и сгруппированный. Таким образом, преобразование должно возвращать результат того же размера, что и для группового фрагмента.
Live Demo
# import the pandas library import pandas as pd import numpy as np ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings', 'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'], 'Rank': [1, 2, 2, 3, 3,4 ,1 ,1,2 , 4,1,2], 'Year': [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017], 'Points':[876,789,863,673,741,812,756,788,694,701,804,690]} df = pd.DataFrame(ipl_data) grouped = df.groupby('Team') score = lambda x: (x - x.mean()) / x.std()*10 print grouped.transform(score)
Его вывод выглядит следующим образом –
Points Rank Year 0 12.843272 -15.000000 -11.618950 1 3.020286 5.000000 -3.872983 2 7.071068 -7.071068 -7.071068 3 -7.071068 7.071068 7.071068 4 -8.608621 11.547005 -10.910895 5 NaN NaN NaN 6 -2.360428 -5.773503 2.182179 7 10.969049 -5.773503 8.728716 8 -7.705963 5.000000 3.872983 9 -7.071068 7.071068 -7.071068 10 7.071068 -7.071068 7.071068 11 -8.157595 5.000000 11.618950
фильтрование
Фильтрация фильтрует данные по определенным критериям и возвращает подмножество данных. Функция filter () используется для фильтрации данных.
Live Demo
import pandas as pd import numpy as np ipl_data = {'Team': ['Riders', 'Riders', 'Devils', 'Devils', 'Kings', 'kings', 'Kings', 'Kings', 'Riders', 'Royals', 'Royals', 'Riders'], 'Rank': [1, 2, 2, 3, 3,4 ,1 ,1,2 , 4,1,2], 'Year': [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017], 'Points':[876,789,863,673,741,812,756,788,694,701,804,690]} df = pd.DataFrame(ipl_data) print df.groupby('Team').filter(lambda x: len(x) >= 3)
Его вывод выглядит следующим образом –
Points Rank Team Year 0 876 1 Riders 2014 1 789 2 Riders 2015 4 741 3 Kings 2014 6 756 1 Kings 2016 7 788 1 Kings 2017 8 694 2 Riders 2016 11 690 2 Riders 2017
В вышеупомянутом условии фильтра мы просим вернуть команды, которые участвовали три или более раз в IPL.
Python Pandas – Слияние / Присоединение
Pandas имеет полнофункциональные, высокопроизводительные операции соединения в памяти, идиоматически очень похожие на реляционные базы данных, такие как SQL.
Pandas предоставляет единственную функцию merge в качестве точки входа для всех стандартных операций соединения базы данных между объектами DataFrame –
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True)
Здесь мы использовали следующие параметры –
-
слева – объект DataFrame.
-
справа – еще один объект DataFrame.
-
on – столбцы (имена) для присоединения. Должен быть найден как в левом, так и в правом объектах DataFrame.
-
left_on – столбцы из левого DataFrame для использования в качестве ключей. Это могут быть имена столбцов или массивы, длина которых равна длине DataFrame.
-
right_on – столбцы справа DataFrame для использования в качестве ключей. Это могут быть имена столбцов или массивы, длина которых равна длине DataFrame.
-
left_index – если True, используйте индекс (метки строк) из левого DataFrame в качестве его ключей присоединения. В случае DataFrame с MultiIndex (иерархическим) количество уровней должно соответствовать количеству ключей объединения из правого DataFrame.
-
right_index – такое же использование, как left_index для правого фрейма данных.
-
как – один из «левый», «правый», «внешний», «внутренний». По умолчанию внутренний. Каждый метод был описан ниже.
-
sort – сортирует результирующий DataFrame по ключам соединения в лексикографическом порядке. По умолчанию установлено значение True, во многих случаях значительно улучшена производительность.
слева – объект DataFrame.
справа – еще один объект DataFrame.
on – столбцы (имена) для присоединения. Должен быть найден как в левом, так и в правом объектах DataFrame.
left_on – столбцы из левого DataFrame для использования в качестве ключей. Это могут быть имена столбцов или массивы, длина которых равна длине DataFrame.
right_on – столбцы справа DataFrame для использования в качестве ключей. Это могут быть имена столбцов или массивы, длина которых равна длине DataFrame.
left_index – если True, используйте индекс (метки строк) из левого DataFrame в качестве его ключей присоединения. В случае DataFrame с MultiIndex (иерархическим) количество уровней должно соответствовать количеству ключей объединения из правого DataFrame.
right_index – такое же использование, как left_index для правого фрейма данных.
как – один из «левый», «правый», «внешний», «внутренний». По умолчанию внутренний. Каждый метод был описан ниже.
sort – сортирует результирующий DataFrame по ключам соединения в лексикографическом порядке. По умолчанию установлено значение True, во многих случаях значительно улучшена производительность.
Давайте теперь создадим два разных DataFrames и выполним операции слияния с ним.
Live Demo
# import the pandas library import pandas as pd left = pd.DataFrame({ 'id':[1,2,3,4,5], 'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'], 'subject_id':['sub1','sub2','sub4','sub6','sub5']}) right = pd.DataFrame( {'id':[1,2,3,4,5], 'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'], 'subject_id':['sub2','sub4','sub3','sub6','sub5']}) print left print right
Его вывод выглядит следующим образом –
Name id subject_id
0 Alex 1 sub1
1 Amy 2 sub2
2 Allen 3 sub4
3 Alice 4 sub6
4 Ayoung 5 sub5
Name id subject_id
0 Billy 1 sub2
1 Brian 2 sub4
2 Bran 3 sub3
3 Bryce 4 sub6
4 Betty 5 sub5
Объединить два фрейма данных на ключе
Live Demo
import pandas as pd left = pd.DataFrame({ 'id':[1,2,3,4,5], 'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'], 'subject_id':['sub1','sub2','sub4','sub6','sub5']}) right = pd.DataFrame({ 'id':[1,2,3,4,5], 'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'], 'subject_id':['sub2','sub4','sub3','sub6','sub5']}) print pd.merge(left,right,on='id')
Его вывод выглядит следующим образом –
Name_x id subject_id_x Name_y subject_id_y 0 Alex 1 sub1 Billy sub2 1 Amy 2 sub2 Brian sub4 2 Allen 3 sub4 Bran sub3 3 Alice 4 sub6 Bryce sub6 4 Ayoung 5 sub5 Betty sub5
Объединение двух фреймов данных на нескольких ключах
Live Demo
import pandas as pd left = pd.DataFrame({ 'id':[1,2,3,4,5], 'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'], 'subject_id':['sub1','sub2','sub4','sub6','sub5']}) right = pd.DataFrame({ 'id':[1,2,3,4,5], 'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'], 'subject_id':['sub2','sub4','sub3','sub6','sub5']}) print pd.merge(left,right,on=['id','subject_id'])
Его вывод выглядит следующим образом –
Name_x id subject_id Name_y 0 Alice 4 sub6 Bryce 1 Ayoung 5 sub5 Betty
Слияние с помощью аргумента «как»
Аргумент how для слияния определяет, как определить, какие ключи должны быть включены в итоговую таблицу. Если комбинация клавиш не отображается ни в левой, ни в правой таблицах, значения в объединенной таблице будут равны NA.
Вот краткое изложение того, как параметры и их эквивалентные имена SQL –
| Метод слияния | SQL-эквивалент | Описание |
|---|---|---|
| оставил | ЛЕВОЕ НАРУЖНОЕ СОЕДИНЕНИЕ | Используйте ключи от левого объекта |
| право | ПРАВО НАРУЖНОЕ СОЕДИНЕНИЕ | Используйте ключи от правильного объекта |
| внешний | ПОЛНОЕ НАРУЖНОЕ СОЕДИНЕНИЕ | Используйте объединение ключей |
| внутренний | ВНУТРЕННЕЕ СОЕДИНЕНИЕ | Используйте пересечение ключей |
Оставить Присоединиться
Live Demo
import pandas as pd left = pd.DataFrame({ 'id':[1,2,3,4,5], 'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'], 'subject_id':['sub1','sub2','sub4','sub6','sub5']}) right = pd.DataFrame({ 'id':[1,2,3,4,5], 'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'], 'subject_id':['sub2','sub4','sub3','sub6','sub5']}) print pd.merge(left, right, on='subject_id', how='left')
Его вывод выглядит следующим образом –
Name_x id_x subject_id Name_y id_y 0 Alex 1 sub1 NaN NaN 1 Amy 2 sub2 Billy 1.0 2 Allen 3 sub4 Brian 2.0 3 Alice 4 sub6 Bryce 4.0 4 Ayoung 5 sub5 Betty 5.0
Право Присоединиться
Live Demo
import pandas as pd left = pd.DataFrame({ 'id':[1,2,3,4,5], 'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'], 'subject_id':['sub1','sub2','sub4','sub6','sub5']}) right = pd.DataFrame({ 'id':[1,2,3,4,5], 'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'], 'subject_id':['sub2','sub4','sub3','sub6','sub5']}) print pd.merge(left, right, on='subject_id', how='right')
Его вывод выглядит следующим образом –
Name_x id_x subject_id Name_y id_y 0 Amy 2.0 sub2 Billy 1 1 Allen 3.0 sub4 Brian 2 2 Alice 4.0 sub6 Bryce 4 3 Ayoung 5.0 sub5 Betty 5 4 NaN NaN sub3 Bran 3
Внешнее соединение
Live Demo
import pandas as pd left = pd.DataFrame({ 'id':[1,2,3,4,5], 'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'], 'subject_id':['sub1','sub2','sub4','sub6','sub5']}) right = pd.DataFrame({ 'id':[1,2,3,4,5], 'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'], 'subject_id':['sub2','sub4','sub3','sub6','sub5']}) print pd.merge(left, right, how='outer', on='subject_id')
Его вывод выглядит следующим образом –
Name_x id_x subject_id Name_y id_y 0 Alex 1.0 sub1 NaN NaN 1 Amy 2.0 sub2 Billy 1.0 2 Allen 3.0 sub4 Brian 2.0 3 Alice 4.0 sub6 Bryce 4.0 4 Ayoung 5.0 sub5 Betty 5.0 5 NaN NaN sub3 Bran 3.0
Внутреннее соединение
Присоединение будет осуществляться по указателю. Операция Join учитывает объект, для которого она вызывается. Таким образом, a.join (b) не равен b.join (a) .
Live Demo
import pandas as pd left = pd.DataFrame({ 'id':[1,2,3,4,5], 'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'], 'subject_id':['sub1','sub2','sub4','sub6','sub5']}) right = pd.DataFrame({ 'id':[1,2,3,4,5], 'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'], 'subject_id':['sub2','sub4','sub3','sub6','sub5']}) print pd.merge(left, right, on='subject_id', how='inner')
Его вывод выглядит следующим образом –
Name_x id_x subject_id Name_y id_y 0 Amy 2 sub2 Billy 1 1 Allen 3 sub4 Brian 2 2 Alice 4 sub6 Bryce 4 3 Ayoung 5 sub5 Betty 5
Python Pandas – Конкатенация
Pandas предоставляет различные средства для простого объединения объектов Series, DataFrame и Panel .
pd.concat(objs,axis=0,join='outer',join_axes=None, ignore_index=False)
-
objs – это последовательность или отображение объектов Series, DataFrame или Panel.
-
ось – {0, 1, …}, по умолчанию 0. Это ось для объединения.
-
join – {‘inner’, ‘external’}, по умолчанию ‘external’. Как обрабатывать индексы на других осях. Наружный для объединения и внутренний для пересечения.
-
ignore_index – логическое значение, по умолчанию False. Если True, не используйте значения индекса на оси конкатенации. Результирующая ось будет помечена 0, …, n – 1.
-
join_axes – это список объектов Index. Специальные индексы для использования для других (n-1) осей вместо выполнения внутренней / внешней логики набора.
objs – это последовательность или отображение объектов Series, DataFrame или Panel.
ось – {0, 1, …}, по умолчанию 0. Это ось для объединения.
join – {‘inner’, ‘external’}, по умолчанию ‘external’. Как обрабатывать индексы на других осях. Наружный для объединения и внутренний для пересечения.
ignore_index – логическое значение, по умолчанию False. Если True, не используйте значения индекса на оси конкатенации. Результирующая ось будет помечена 0, …, n – 1.
join_axes – это список объектов Index. Специальные индексы для использования для других (n-1) осей вместо выполнения внутренней / внешней логики набора.
Объединение объектов
Функция concat выполняет всю тяжелую работу по выполнению операций конкатенации вдоль оси. Давайте создавать разные объекты и делать конкатенацию.
Live Demo
import pandas as pd one = pd.DataFrame({ 'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'], 'subject_id':['sub1','sub2','sub4','sub6','sub5'], 'Marks_scored':[98,90,87,69,78]}, index=[1,2,3,4,5]) two = pd.DataFrame({ 'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'], 'subject_id':['sub2','sub4','sub3','sub6','sub5'], 'Marks_scored':[89,80,79,97,88]}, index=[1,2,3,4,5]) print pd.concat([one,two])
Его вывод выглядит следующим образом –
Marks_scored Name subject_id 1 98 Alex sub1 2 90 Amy sub2 3 87 Allen sub4 4 69 Alice sub6 5 78 Ayoung sub5 1 89 Billy sub2 2 80 Brian sub4 3 79 Bran sub3 4 97 Bryce sub6 5 88 Betty sub5
Предположим, что мы хотим связать определенные ключи с каждым из фрагментов разделенного DataFrame. Мы можем сделать это, используя аргумент keys –
Live Demo
import pandas as pd one = pd.DataFrame({ 'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'], 'subject_id':['sub1','sub2','sub4','sub6','sub5'], 'Marks_scored':[98,90,87,69,78]}, index=[1,2,3,4,5]) two = pd.DataFrame({ 'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'], 'subject_id':['sub2','sub4','sub3','sub6','sub5'], 'Marks_scored':[89,80,79,97,88]}, index=[1,2,3,4,5]) print pd.concat([one,two],keys=['x','y'])
Его вывод выглядит следующим образом –
x 1 98 Alex sub1 2 90 Amy sub2 3 87 Allen sub4 4 69 Alice sub6 5 78 Ayoung sub5 y 1 89 Billy sub2 2 80 Brian sub4 3 79 Bran sub3 4 97 Bryce sub6 5 88 Betty sub5
Индекс результирующего дублируется; каждый индекс повторяется.
Если результирующий объект должен следовать своей собственной индексации, установите для ignore_index значение True .
Live Demo
import pandas as pd one = pd.DataFrame({ 'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'], 'subject_id':['sub1','sub2','sub4','sub6','sub5'], 'Marks_scored':[98,90,87,69,78]}, index=[1,2,3,4,5]) two = pd.DataFrame({ 'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'], 'subject_id':['sub2','sub4','sub3','sub6','sub5'], 'Marks_scored':[89,80,79,97,88]}, index=[1,2,3,4,5]) print pd.concat([one,two],keys=['x','y'],ignore_index=True)
Его вывод выглядит следующим образом –
Marks_scored Name subject_id 0 98 Alex sub1 1 90 Amy sub2 2 87 Allen sub4 3 69 Alice sub6 4 78 Ayoung sub5 5 89 Billy sub2 6 80 Brian sub4 7 79 Bran sub3 8 97 Bryce sub6 9 88 Betty sub5
Обратите внимание, что индекс изменяется полностью, а ключи также переопределяются.
Если вдоль оси = 1 необходимо добавить два объекта, то будут добавлены новые столбцы.
Live Demo
import pandas as pd one = pd.DataFrame({ 'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'], 'subject_id':['sub1','sub2','sub4','sub6','sub5'], 'Marks_scored':[98,90,87,69,78]}, index=[1,2,3,4,5]) two = pd.DataFrame({ 'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'], 'subject_id':['sub2','sub4','sub3','sub6','sub5'], 'Marks_scored':[89,80,79,97,88]}, index=[1,2,3,4,5]) print pd.concat([one,two],axis=1)
Его вывод выглядит следующим образом –
Marks_scored Name subject_id Marks_scored Name subject_id 1 98 Alex sub1 89 Billy sub2 2 90 Amy sub2 80 Brian sub4 3 87 Allen sub4 79 Bran sub3 4 69 Alice sub6 97 Bryce sub6 5 78 Ayoung sub5 88 Betty sub5
Конкатенация с использованием append
Полезный ярлык для конкатата – это методы добавления экземпляров в Series и DataFrame. Эти методы на самом деле предшествовали concat. Они соединяются по оси = 0 , а именно по индексу –
Live Demo
import pandas as pd one = pd.DataFrame({ 'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'], 'subject_id':['sub1','sub2','sub4','sub6','sub5'], 'Marks_scored':[98,90,87,69,78]}, index=[1,2,3,4,5]) two = pd.DataFrame({ 'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'], 'subject_id':['sub2','sub4','sub3','sub6','sub5'], 'Marks_scored':[89,80,79,97,88]}, index=[1,2,3,4,5]) print one.append(two)
Его вывод выглядит следующим образом –
Marks_scored Name subject_id 1 98 Alex sub1 2 90 Amy sub2 3 87 Allen sub4 4 69 Alice sub6 5 78 Ayoung sub5 1 89 Billy sub2 2 80 Brian sub4 3 79 Bran sub3 4 97 Bryce sub6 5 88 Betty sub5
Функция добавления также может принимать несколько объектов:
Live Demo
import pandas as pd one = pd.DataFrame({ 'Name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'], 'subject_id':['sub1','sub2','sub4','sub6','sub5'], 'Marks_scored':[98,90,87,69,78]}, index=[1,2,3,4,5]) two = pd.DataFrame({ 'Name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'], 'subject_id':['sub2','sub4','sub3','sub6','sub5'], 'Marks_scored':[89,80,79,97,88]}, index=[1,2,3,4,5]) print one.append([two,one,two])
Его вывод выглядит следующим образом –
Marks_scored Name subject_id 1 98 Alex sub1 2 90 Amy sub2 3 87 Allen sub4 4 69 Alice sub6 5 78 Ayoung sub5 1 89 Billy sub2 2 80 Brian sub4 3 79 Bran sub3 4 97 Bryce sub6 5 88 Betty sub5 1 98 Alex sub1 2 90 Amy sub2 3 87 Allen sub4 4 69 Alice sub6 5 78 Ayoung sub5 1 89 Billy sub2 2 80 Brian sub4 3 79 Bran sub3 4 97 Bryce sub6 5 88 Betty sub5
Временные ряды
Панды предоставляют надежный инструмент для работы с данными временных рядов, особенно в финансовом секторе. Работая с данными временных рядов, мы часто сталкиваемся со следующим:
- Генерация последовательности времени
- Преобразовать временные ряды на разные частоты
Pandas предоставляет относительно компактный и автономный набор инструментов для выполнения вышеуказанных задач.
Получить текущее время
datetime.now () показывает текущую дату и время.
Live Demo
import pandas as pd print pd.datetime.now()
Его вывод выглядит следующим образом –
2017-05-11 06:10:13.393147
Создать метку времени
Данные с метками времени – это самый базовый тип данных временных рядов, который связывает значения с точками во времени. Для объектов панд это означает использование точек во времени. Давайте возьмем пример –
Live Demo
import pandas as pd print pd.Timestamp('2017-03-01')
Его вывод выглядит следующим образом –
2017-03-01 00:00:00
Также возможно преобразовать целое или плавающее время эпохи. Единицей по умолчанию для них является наносекунда (поскольку именно так хранятся метки времени). Однако часто эпохи хранятся в другом блоке, который можно указать. Давайте возьмем другой пример
Live Demo
import pandas as pd print pd.Timestamp(1587687255,unit='s')
Его вывод выглядит следующим образом –
2020-04-24 00:14:15
Создать диапазон времени
Live Demo
import pandas as pd print pd.date_range("11:00", "13:30", freq="30min").time
Его вывод выглядит следующим образом –
[datetime.time(11, 0) datetime.time(11, 30) datetime.time(12, 0) datetime.time(12, 30) datetime.time(13, 0) datetime.time(13, 30)]
Изменить частоту времени
Live Demo
import pandas as pd print pd.date_range("11:00", "13:30", freq="H").time
Его вывод выглядит следующим образом –
[datetime.time(11, 0) datetime.time(12, 0) datetime.time(13, 0)]
Преобразование в метки времени
Чтобы преобразовать объект Series или подобный списку объект типа даты, например строки, эпохи или смесь, вы можете использовать функцию to_datetime . При прохождении это возвращает Series (с тем же индексом), в то время как подобный списку конвертируется в DatetimeIndex . Взгляните на следующий пример –
Live Demo
import pandas as pd print pd.to_datetime(pd.Series(['Jul 31, 2009','2010-01-10', None]))
Его вывод выглядит следующим образом –
0 2009-07-31 1 2010-01-10 2 NaT dtype: datetime64[ns]
NaT означает не время (эквивалентно NaN)
Давайте возьмем другой пример.
Live Demo
import pandas as pd print pd.to_datetime(['2005/11/23', '2010.12.31', None])
Его вывод выглядит следующим образом –
DatetimeIndex(['2005-11-23', '2010-12-31', 'NaT'], dtype='datetime64[ns]', freq=None)
Python Pandas – Функциональность даты
Расширяя временной ряд, функции даты играют важную роль в анализе финансовых данных. При работе с данными Date мы часто сталкиваемся со следующим:
- Генерация последовательности дат
- Конвертировать серию дат на разные частоты
Создать диапазон дат
Используя функцию date.range () , указав периоды и частоту, мы можем создать серию дат. По умолчанию частота диапазона составляет дни.
Live Demo
import pandas as pd print pd.date_range('1/1/2011', periods=5)
Его вывод выглядит следующим образом –
DatetimeIndex(['2011-01-01', '2011-01-02', '2011-01-03', '2011-01-04', '2011-01-05'], dtype='datetime64[ns]', freq='D')
Изменить частоту даты
Live Demo
import pandas as pd print pd.date_range('1/1/2011', periods=5,freq='M')
Его вывод выглядит следующим образом –
DatetimeIndex(['2011-01-31', '2011-02-28', '2011-03-31', '2011-04-30', '2011-05-31'], dtype='datetime64[ns]', freq='M')
bdate_range
bdate_range () обозначает диапазоны бизнес-дат. В отличие от date_range (), он исключает субботу и воскресенье.
Live Demo
import pandas as pd print pd.date_range('1/1/2011', periods=5)
Его вывод выглядит следующим образом –
DatetimeIndex(['2011-01-01', '2011-01-02', '2011-01-03', '2011-01-04', '2011-01-05'], dtype='datetime64[ns]', freq='D')
Обратите внимание, что после 3 марта дата переходит на 6 марта, исключая 4 и 5 марта. Просто проверьте свой календарь на дни.
Удобные функции, такие как date_range и bdate_range, используют различные псевдонимы частот. Частота по умолчанию для date_range – это календарный день, а по умолчанию для bdate_range – рабочий день.
Live Demo
import pandas as pd start = pd.datetime(2011, 1, 1) end = pd.datetime(2011, 1, 5) print pd.date_range(start, end)
Его вывод выглядит следующим образом –
DatetimeIndex(['2011-01-01', '2011-01-02', '2011-01-03', '2011-01-04', '2011-01-05'], dtype='datetime64[ns]', freq='D')
Смещение псевдонимов
Ряд псевдонимов строк приведены для полезных общих частот временного ряда. Мы будем называть эти псевдонимы псевдонимами смещения.
| кличка | Описание | кличка | Описание |
|---|---|---|---|
| В | частота рабочих дней | BQS | Частота начала рабочего квартала |
| D | частота календарного дня | годовая (годовая) конечная частота | |
| W | еженедельная частота | BA | частота окончания финансового года |
| M | частота окончания месяца | БАС | частота начала финансового года |
| SM | частота окончания полугодия | BH | частота рабочих часов |
| BM | частота окончания рабочего месяца | ЧАС | почасовая частота |
| МИЗ | частота начала месяца | Т, мин | мельчайшая частота |
| смс | Частота начала полугодового SMS | S | вторая частота |
| BMS | частота начала рабочего месяца | L, мс | миллисекунды |
| Q | частота четверти конца | Вы нас | микросекунд |
| BQ | частота окончания рабочего квартала | N | наносекунд |
| QS | частота начала квартала |
Python Pandas – Timedelta
Timedeltas – это разница во времени, выраженная в единицах разницы, например, дни, часы, минуты, секунды. Они могут быть как положительными, так и отрицательными.
Мы можем создавать объекты Timedelta, используя различные аргументы, как показано ниже –
строка
Передав строковый литерал, мы можем создать объект timedelta.
Live Demo
import pandas as pd print pd.Timedelta('2 days 2 hours 15 minutes 30 seconds')
Его вывод выглядит следующим образом –
2 days 02:15:30
целое число
Передавая целочисленное значение вместе с единицей, аргумент создает объект Timedelta.
Live Demo
import pandas as pd print pd.Timedelta(6,unit='h')
Его вывод выглядит следующим образом –
0 days 06:00:00
Смещения данных
Смещения данных, такие как – недели, дни, часы, минуты, секунды, миллисекунды, микросекунды, наносекунды, также могут быть использованы в строительстве.
Live Demo
import pandas as pd print pd.Timedelta(days=2)
Его вывод выглядит следующим образом –
2 days 00:00:00
to_timedelta ()
Используя pd.to_timedelta верхнего уровня, вы можете преобразовать скаляр, массив, список или серию из распознанного формата / значения timedelta в тип Timedelta. Он будет создавать Series, если вход является Series, скаляр, если вход подобен скаляру, в противном случае будет выводиться TimedeltaIndex .
Live Demo
import pandas as pd print pd.Timedelta(days=2)
Его вывод выглядит следующим образом –
2 days 00:00:00
операции
Вы можете работать с Series / DataFrames и строить timedelta64 [ns] Series с помощью операций вычитания на datetime64 [ns] Series или Timestamps.
Давайте теперь создадим DataFrame с объектами Timedelta и datetime и выполним некоторые арифметические операции над ним –
Live Demo
import pandas as pd s = pd.Series(pd.date_range('2012-1-1', periods=3, freq='D')) td = pd.Series([ pd.Timedelta(days=i) for i in range(3) ]) df = pd.DataFrame(dict(A = s, B = td)) print df
Его вывод выглядит следующим образом –
A B 0 2012-01-01 0 days 1 2012-01-02 1 days 2 2012-01-03 2 days
Операции добавления
Live Demo
import pandas as pd s = pd.Series(pd.date_range('2012-1-1', periods=3, freq='D')) td = pd.Series([ pd.Timedelta(days=i) for i in range(3) ]) df = pd.DataFrame(dict(A = s, B = td)) df['C']=df['A']+df['B'] print df
Его вывод выглядит следующим образом –
A B C 0 2012-01-01 0 days 2012-01-01 1 2012-01-02 1 days 2012-01-03 2 2012-01-03 2 days 2012-01-05
Операция вычитания
Live Demo
import pandas as pd s = pd.Series(pd.date_range('2012-1-1', periods=3, freq='D')) td = pd.Series([ pd.Timedelta(days=i) for i in range(3) ]) df = pd.DataFrame(dict(A = s, B = td)) df['C']=df['A']+df['B'] df['D']=df['C']+df['B'] print df
Его вывод выглядит следующим образом –
A B C D 0 2012-01-01 0 days 2012-01-01 2012-01-01 1 2012-01-02 1 days 2012-01-03 2012-01-04 2 2012-01-03 2 days 2012-01-05 2012-01-07
Python Pandas – категорические данные
Часто в режиме реального времени данные включают в себя текстовые столбцы, которые являются повторяющимися. Такие функции, как пол, страна и коды, всегда повторяются. Это примеры для категориальных данных.
Категориальные переменные могут принимать только ограниченное и обычно фиксированное количество возможных значений. Помимо фиксированной длины, категориальные данные могут иметь порядок, но не могут выполнять числовые операции. Категориальными являются данные типа Pandas.
Категориальный тип данных полезен в следующих случаях:
-
Строковая переменная, состоящая только из нескольких разных значений. Преобразование такой строковой переменной в категориальную переменную сэкономит некоторую память.
-
Лексический порядок переменной не совпадает с логическим порядком («один», «два», «три»). При преобразовании в категориальный и указании порядка в категориях сортировка и min / max будут использовать логический порядок вместо лексического порядка.
-
В качестве сигнала для других библиотек Python, что этот столбец следует рассматривать как категориальную переменную (например, использовать подходящие статистические методы или типы графиков).
Строковая переменная, состоящая только из нескольких разных значений. Преобразование такой строковой переменной в категориальную переменную сэкономит некоторую память.
Лексический порядок переменной не совпадает с логическим порядком («один», «два», «три»). При преобразовании в категориальный и указании порядка в категориях сортировка и min / max будут использовать логический порядок вместо лексического порядка.
В качестве сигнала для других библиотек Python, что этот столбец следует рассматривать как категориальную переменную (например, использовать подходящие статистические методы или типы графиков).
Создание объекта
Категориальный объект может быть создан несколькими способами. Различные способы были описаны ниже –
категория
Указав dtype в качестве «категории» при создании объекта pandas.
Live Demo
import pandas as pd s = pd.Series(["a","b","c","a"], dtype="category") print s
Его вывод выглядит следующим образом –
0 a 1 b 2 c 3 a dtype: category Categories (3, object): [a, b, c]
Число элементов, переданных объекту серии, равно четырем, а категорий – только три. Соблюдайте то же самое в выходных категориях.
pd.Categorical
Используя стандартный конструктор категорий pandas, мы можем создать объект категории.
pandas.Categorical(values, categories, ordered)
Давайте возьмем пример –
Live Demo
import pandas as pd cat = pd.Categorical(['a', 'b', 'c', 'a', 'b', 'c']) print cat
Его вывод выглядит следующим образом –
[a, b, c, a, b, c] Categories (3, object): [a, b, c]
Давайте иметь другой пример –
Live Demo
import pandas as pd cat = cat=pd.Categorical(['a','b','c','a','b','c','d'], ['c', 'b', 'a']) print cat
Его вывод выглядит следующим образом –
[a, b, c, a, b, c, NaN] Categories (3, object): [c, b, a]
Здесь второй аргумент обозначает категории. Таким образом, любое значение, которое отсутствует в категориях, будет рассматриваться как NaN .
Теперь взглянем на следующий пример:
Live Demo
import pandas as pd cat = cat=pd.Categorical(['a','b','c','a','b','c','d'], ['c', 'b', 'a'],ordered=True) print cat
Его вывод выглядит следующим образом –
[a, b, c, a, b, c, NaN] Categories (3, object): [c < b < a]
Логически, порядок означает, что a больше, чем b, а b больше, чем c .
Описание
Используя команду .describe () для категориальных данных, мы получаем аналогичный вывод для Series или DataFrame строки типа .
Live Demo
import pandas as pd import numpy as np cat = pd.Categorical(["a", "c", "c", np.nan], categories=["b", "a", "c"]) df = pd.DataFrame({"cat":cat, "s":["a", "c", "c", np.nan]}) print df.describe() print df["cat"].describe()
Его вывод выглядит следующим образом –
cat s count 3 3 unique 2 2 top c c freq 2 2 count 3 unique 2 top c freq 2 Name: cat, dtype: object
Получить свойства категории
Команда obj.cat.categories используется для получения категорий объекта .
Live Demo
import pandas as pd import numpy as np s = pd.Categorical(["a", "c", "c", np.nan], categories=["b", "a", "c"]) print s.categories
Его вывод выглядит следующим образом –
Index([u'b', u'a', u'c'], dtype='object')
Команда obj.ordered используется для получения порядка объекта.
Live Demo
import pandas as pd import numpy as np cat = pd.Categorical(["a", "c", "c", np.nan], categories=["b", "a", "c"]) print cat.ordered
Его вывод выглядит следующим образом –
False
Функция вернула false, потому что мы не указали ни одного заказа.
Переименование категорий
Переименование категорий выполняется путем присвоения новых значений свойству series.cat.categories series.cat.categories.
Live Demo
import pandas as pd s = pd.Series(["a","b","c","a"], dtype="category") s.cat.categories = ["Group %s" % g for g in s.cat.categories] print s.cat.categories
Его вывод выглядит следующим образом –
Index([u'Group a', u'Group b', u'Group c'], dtype='object')
Начальные категории [a, b, c] обновляются свойством объекта s.cat.categories .
Добавление новых категорий
Используя метод Categoryorical.add.categories (), можно добавлять новые категории.
Live Demo
import pandas as pd s = pd.Series(["a","b","c","a"], dtype="category") s = s.cat.add_categories([4]) print s.cat.categories
Его вывод выглядит следующим образом –
Index([u'a', u'b', u'c', 4], dtype='object')
Удаление категорий
Используя метод Categoryorical.remove_categories () , нежелательные категории могут быть удалены.
Live Demo
import pandas as pd s = pd.Series(["a","b","c","a"], dtype="category") print ("Original object:") print s print ("After removal:") print s.cat.remove_categories("a")
Его вывод выглядит следующим образом –
Original object: 0 a 1 b 2 c 3 a dtype: category Categories (3, object): [a, b, c] After removal: 0 NaN 1 b 2 c 3 NaN dtype: category Categories (2, object): [b, c]
Сравнение категориальных данных
Сравнение категориальных данных с другими объектами возможно в трех случаях –
-
сравнение равенства (== и! =) со спискообразным объектом (list, Series, array, …) той же длины, что и категориальные данные.
-
все сравнения (==,! =,>,> =, <и <=) категориальных данных с другой категориальной серией, если они упорядочены == True и категории одинаковы.
-
все сравнения категориальных данных со скаляром.
сравнение равенства (== и! =) со спискообразным объектом (list, Series, array, …) той же длины, что и категориальные данные.
все сравнения (==,! =,>,> =, <и <=) категориальных данных с другой категориальной серией, если они упорядочены == True и категории одинаковы.
все сравнения категориальных данных со скаляром.
Взгляните на следующий пример –
Live Demo
import pandas as pd cat = pd.Series([1,2,3]).astype("category", categories=[1,2,3], ordered=True) cat1 = pd.Series([2,2,2]).astype("category", categories=[1,2,3], ordered=True) print cat>cat1
Его вывод выглядит следующим образом –
0 False 1 False 2 True dtype: bool
Python Pandas – Визуализация
Основное изображение: сюжет
Эта функциональность в Series и DataFrame представляет собой простую оболочку для метода plot () из библиотек matplotlib .
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(10,4),index=pd.date_range('1/1/2000', periods=10), columns=list('ABCD')) df.plot()
Его вывод выглядит следующим образом –
Если индекс состоит из дат, он вызывает gct (). Autofmt_xdate () для форматирования оси X, как показано на иллюстрации выше.
Мы можем построить один столбец по сравнению с другим, используя ключевые слова x и y .
Методы печати позволяют использовать несколько стилей печати, отличных от линейного графика по умолчанию. Эти методы могут быть предоставлены в качестве аргумента типа «ключевое слово» для plot () . К ним относятся –
- бар или бар для баров
- гистограмма для гистограммы
- коробка для бокса
- «площадь» для участков
- «разброс» для точечных графиков
Бар Участок
Давайте теперь посмотрим, что такое «Барный участок», создав его. Гистограмма может быть создана следующим образом –
import pandas as pd import numpy as np df = pd.DataFrame(np.random.rand(10,4),columns=['a','b','c','d') df.plot.bar()
Его вывод выглядит следующим образом –
Чтобы создать гистограмму с накоплением, передайте stacked = True –
import pandas as pd df = pd.DataFrame(np.random.rand(10,4),columns=['a','b','c','d') df.plot.bar(stacked=True)
Его вывод выглядит следующим образом –
Чтобы получить горизонтальные столбцы, используйте метод Барх –
import pandas as pd import numpy as np df = pd.DataFrame(np.random.rand(10,4),columns=['a','b','c','d') df.plot.barh(stacked=True)
Его вывод выглядит следующим образом –
Гистограммы
Гистограммы могут быть построены с использованием метода plot.hist () . Мы можем указать количество бинов.
import pandas as pd import numpy as np df = pd.DataFrame({'a':np.random.randn(1000)+1,'b':np.random.randn(1000),'c': np.random.randn(1000) - 1}, columns=['a', 'b', 'c']) df.plot.hist(bins=20)
Его вывод выглядит следующим образом –
Чтобы построить различные гистограммы для каждого столбца, используйте следующий код –
import pandas as pd import numpy as np df=pd.DataFrame({'a':np.random.randn(1000)+1,'b':np.random.randn(1000),'c': np.random.randn(1000) - 1}, columns=['a', 'b', 'c']) df.diff.hist(bins=20)
Его вывод выглядит следующим образом –
Коробочные участки
Boxplot можно нарисовать, вызвав Series.box.plot () и DataFrame.box.plot () или DataFrame.boxplot () для визуализации распределения значений в каждом столбце.
Например, вот блок-график, представляющий пять испытаний из 10 наблюдений равномерной случайной величины на [0,1).
import pandas as pd import numpy as np df = pd.DataFrame(np.random.rand(10, 5), columns=['A', 'B', 'C', 'D', 'E']) df.plot.box()
Его вывод выглядит следующим образом –
Площадь участка
График области может быть создан с использованием методов Series.plot.area () или DataFrame.plot.area () .
import pandas as pd import numpy as np df = pd.DataFrame(np.random.rand(10, 4), columns=['a', 'b', 'c', 'd']) df.plot.area()
Его вывод выглядит следующим образом –
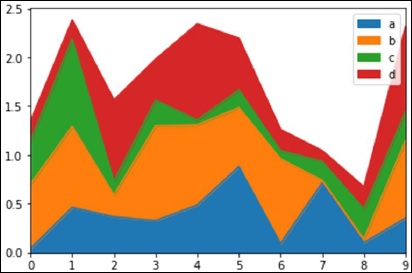
Scatter Plot
Точечный график может быть создан с использованием методов DataFrame.plot.scatter () .
import pandas as pd import numpy as np df = pd.DataFrame(np.random.rand(50, 4), columns=['a', 'b', 'c', 'd']) df.plot.scatter(x='a', y='b')
Его вывод выглядит следующим образом –
Круговая диаграмма
Круговая диаграмма может быть создана с использованием метода DataFrame.plot.pie () .
import pandas as pd import numpy as np df = pd.DataFrame(3 * np.random.rand(4), index=['a', 'b', 'c', 'd'], columns=['x']) df.plot.pie(subplots=True)
Его вывод выглядит следующим образом –
Python Pandas – IO Tools
Pandas I / O API – это набор функций считывателя верхнего уровня, доступный как pd.read_csv (), которые обычно возвращают объект Pandas.
Две функции рабочей лошадки для чтения текстовых файлов (или плоских файлов) – read_csv () и read_table () . Они оба используют один и тот же код для интеллектуального преобразования табличных данных в объект DataFrame –
pandas.read_csv(filepath_or_buffer, sep=',', delimiter=None, header='infer', names=None, index_col=None, usecols=None
pandas.read_csv(filepath_or_buffer, sep='t', delimiter=None, header='infer', names=None, index_col=None, usecols=None
Вот как выглядят данные файла CSV:
S.No,Name,Age,City,Salary 1,Tom,28,Toronto,20000 2,Lee,32,HongKong,3000 3,Steven,43,Bay Area,8300 4,Ram,38,Hyderabad,3900
Сохраните эти данные как temp.csv и выполните операции с ними.
S.No,Name,Age,City,Salary 1,Tom,28,Toronto,20000 2,Lee,32,HongKong,3000 3,Steven,43,Bay Area,8300 4,Ram,38,Hyderabad,3900
Сохраните эти данные как temp.csv и выполните операции с ними.
read.csv
read.csv считывает данные из файлов csv и создает объект DataFrame.
import pandas as pd df=pd.read_csv("temp.csv") print df
Его вывод выглядит следующим образом –
S.No Name Age City Salary 0 1 Tom 28 Toronto 20000 1 2 Lee 32 HongKong 3000 2 3 Steven 43 Bay Area 8300 3 4 Ram 38 Hyderabad 3900
пользовательский индекс
Это указывает столбец в файле CSV для настройки индекса с помощью index_col.
import pandas as pd df=pd.read_csv("temp.csv",index_col=['S.No']) print df
Его вывод выглядит следующим образом –
S.No Name Age City Salary 1 Tom 28 Toronto 20000 2 Lee 32 HongKong 3000 3 Steven 43 Bay Area 8300 4 Ram 38 Hyderabad 3900
Преобразователи
D-тип столбцов может быть передан как dict.
import pandas as pd df = pd.read_csv("temp.csv", dtype={'Salary': np.float64}) print df.dtypes
Его вывод выглядит следующим образом –
S.No int64 Name object Age int64 City object Salary float64 dtype: object
По умолчанию d-тип столбца Salary – int , но результат показывает его как float, потому что мы явно приводили тип.
Таким образом, данные выглядят как float –
S.No Name Age City Salary 0 1 Tom 28 Toronto 20000.0 1 2 Lee 32 HongKong 3000.0 2 3 Steven 43 Bay Area 8300.0 3 4 Ram 38 Hyderabad 3900.0
header_names
Укажите имена заголовков, используя аргумент names.
import pandas as pd df=pd.read_csv("temp.csv", names=['a', 'b', 'c','d','e']) print df
Его вывод выглядит следующим образом –
a b c d e 0 S.No Name Age City Salary 1 1 Tom 28 Toronto 20000 2 2 Lee 32 HongKong 3000 3 3 Steven 43 Bay Area 8300 4 4 Ram 38 Hyderabad 3900
Обратите внимание, что к именам заголовков добавляются пользовательские имена, но заголовок в файле не был удален. Теперь мы используем аргумент заголовка, чтобы удалить это.
Если заголовок находится в строке, отличной от первой, передайте номер строки в заголовок. Это пропустит предыдущие строки.
import pandas as pd df=pd.read_csv("temp.csv",names=['a','b','c','d','e'],header=0) print df
Его вывод выглядит следующим образом –
a b c d e 0 S.No Name Age City Salary 1 1 Tom 28 Toronto 20000 2 2 Lee 32 HongKong 3000 3 3 Steven 43 Bay Area 8300 4 4 Ram 38 Hyderabad 3900
SkipRows
skiprows пропускает указанное количество строк.
import pandas as pd df=pd.read_csv("temp.csv", skiprows=2) print df
Его вывод выглядит следующим образом –
2 Lee 32 HongKong 3000 0 3 Steven 43 Bay Area 8300 1 4 Ram 38 Hyderabad 3900
Python Pandas – разреженные данные
Разреженные объекты «сжимаются», когда любые данные, соответствующие определенному значению (NaN / отсутствующее значение, хотя любое значение может быть выбрано), опущены. Специальный объект SparseIndex отслеживает, где данные были «очищены». Это будет иметь гораздо больше смысла в примере. Все стандартные структуры данных Pandas применяют метод to_sparse –
Live Demo
import pandas as pd import numpy as np ts = pd.Series(np.random.randn(10)) ts[2:-2] = np.nan sts = ts.to_sparse() print sts
Его вывод выглядит следующим образом –
0 -0.810497 1 -1.419954 2 NaN 3 NaN 4 NaN 5 NaN 6 NaN 7 NaN 8 0.439240 9 -1.095910 dtype: float64 BlockIndex Block locations: array([0, 8], dtype=int32) Block lengths: array([2, 2], dtype=int32)
Разреженные объекты существуют по соображениям эффективности памяти.
Давайте теперь предположим, что у вас был большой DataFrame NA, и выполните следующий код:
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(10000, 4)) df.ix[:9998] = np.nan sdf = df.to_sparse() print sdf.density
Его вывод выглядит следующим образом –
0.0001
Любой разреженный объект можно преобразовать обратно в стандартную плотную форму, вызвав to_dense –
Live Demo
import pandas as pd import numpy as np ts = pd.Series(np.random.randn(10)) ts[2:-2] = np.nan sts = ts.to_sparse() print sts.to_dense()
Его вывод выглядит следующим образом –
0 -0.810497 1 -1.419954 2 NaN 3 NaN 4 NaN 5 NaN 6 NaN 7 NaN 8 0.439240 9 -1.095910 dtype: float64
Разреженные Dtypes
Разреженные данные должны иметь тот же тип d, что и их плотное представление. В настоящее время поддерживаются float64, int64 и booldtypes . В зависимости от исходного dtype, значение fill_value по умолчанию меняется –
-
float64 – np.nan
-
int64 – 0
-
bool – False
float64 – np.nan
int64 – 0
bool – False
Давайте выполним следующий код, чтобы понять то же самое –
Live Demo
import pandas as pd import numpy as np s = pd.Series([1, np.nan, np.nan]) print s s.to_sparse() print s
Его вывод выглядит следующим образом –
0 1.0 1 NaN 2 NaN dtype: float64 0 1.0 1 NaN 2 NaN dtype: float64
Python Pandas – Предостережения и Gotchas
Предостережения означают предупреждение, а гоча означает невидимую проблему.
Использование заявления If / Truth с пандами
Pandas следует соглашению об ошибке, когда вы пытаетесь преобразовать что-то в bool . Это происходит в случае, если или когда используются логические операции, и, или , или нет . Не ясно, каким должен быть результат. Должно ли это быть Истиной, потому что это не нулевая длина? Ложь, потому что есть Ложные значения? Неясно, поэтому вместо этого Pandas вызывает ValueError –
Live Demo
import pandas as pd if pd.Series([False, True, False]): print 'I am True'
Его вывод выглядит следующим образом –
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool() a.item(),a.any() or a.all().
В каких условиях неясно, что с этим делать. Ошибка наводит на мысль о том, использовать ли None или любой из них .
Live Demo
import pandas as pd if pd.Series([False, True, False]).any(): print("I am any")
Его вывод выглядит следующим образом –
I am any
Чтобы оценить одноэлементные объекты панд в логическом контексте, используйте метод .bool () –
Live Demo
import pandas as pd print pd.Series([True]).bool()
Его вывод выглядит следующим образом –
True
Побитовый логический
Побитовые логические операторы, такие как == и ! = вернет логический ряд, который почти всегда является тем, что требуется в любом случае.
Live Demo
import pandas as pd s = pd.Series(range(5)) print s==4
Его вывод выглядит следующим образом –
0 False 1 False 2 False 3 False 4 True dtype: bool
Операция isin
Это возвращает логический ряд, показывающий, содержится ли каждый элемент в Серии точно в переданной последовательности значений.
Live Demo
import pandas as pd s = pd.Series(list('abc')) s = s.isin(['a', 'c', 'e']) print s
Его вывод выглядит следующим образом –
0 True 1 False 2 True dtype: bool
Переиндексация против ix Gotcha
Многие пользователи обнаружат, что используют возможности индексирования ix в качестве краткого средства выбора данных из объекта Pandas –
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(6, 4), columns=['one', 'two', 'three', 'four'],index=list('abcdef')) print df print df.ix[['b', 'c', 'e']]
Его вывод выглядит следующим образом –
one two three four
a -1.582025 1.335773 0.961417 -1.272084
b 1.461512 0.111372 -0.072225 0.553058
c -1.240671 0.762185 1.511936 -0.630920
d -2.380648 -0.029981 0.196489 0.531714
e 1.846746 0.148149 0.275398 -0.244559
f -1.842662 -0.933195 2.303949 0.677641
one two three four
b 1.461512 0.111372 -0.072225 0.553058
c -1.240671 0.762185 1.511936 -0.630920
e 1.846746 0.148149 0.275398 -0.244559
Это, конечно, полностью эквивалентно в этом случае использованию метода переиндексации –
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(6, 4), columns=['one', 'two', 'three', 'four'],index=list('abcdef')) print df print df.reindex(['b', 'c', 'e'])
Его вывод выглядит следующим образом –
one two three four
a 1.639081 1.369838 0.261287 -1.662003
b -0.173359 0.242447 -0.494384 0.346882
c -0.106411 0.623568 0.282401 -0.916361
d -1.078791 -0.612607 -0.897289 -1.146893
e 0.465215 1.552873 -1.841959 0.329404
f 0.966022 -0.190077 1.324247 0.678064
one two three four
b -0.173359 0.242447 -0.494384 0.346882
c -0.106411 0.623568 0.282401 -0.916361
e 0.465215 1.552873 -1.841959 0.329404
Некоторые могут прийти к выводу, что ix и reindex на 100% эквивалентны на основании этого. Это верно, за исключением случая целочисленной индексации. Например, вышеуказанная операция может альтернативно быть выражена как –
Live Demo
import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(6, 4), columns=['one', 'two', 'three', 'four'],index=list('abcdef')) print df print df.ix[[1, 2, 4]] print df.reindex([1, 2, 4])
Его вывод выглядит следующим образом –
one two three four
a -1.015695 -0.553847 1.106235 -0.784460
b -0.527398 -0.518198 -0.710546 -0.512036
c -0.842803 -1.050374 0.787146 0.205147
d -1.238016 -0.749554 -0.547470 -0.029045
e -0.056788 1.063999 -0.767220 0.212476
f 1.139714 0.036159 0.201912 0.710119
one two three four
b -0.527398 -0.518198 -0.710546 -0.512036
c -0.842803 -1.050374 0.787146 0.205147
e -0.056788 1.063999 -0.767220 0.212476
one two three four
1 NaN NaN NaN NaN
2 NaN NaN NaN NaN
4 NaN NaN NaN NaN
Важно помнить, что переиндексация – это только строгая индексация меток . Это может привести к некоторым неожиданным результатам в патологических случаях, когда индекс содержит, скажем, как целые числа, так и строки.
Python Pandas – Сравнение с SQL
Поскольку многие потенциальные пользователи Pandas немного знакомы с SQL, на этой странице приведены некоторые примеры того, как различные операции SQL могут выполняться с помощью pandas.
import pandas as pd url = 'https://raw.github.com/pandasdev/ pandas/master/pandas/tests/data/tips.csv' tips=pd.read_csv(url) print tips.head()
Его вывод выглядит следующим образом –
total_bill tip sex smoker day time size 0 16.99 1.01 Female No Sun Dinner 2 1 10.34 1.66 Male No Sun Dinner 3 2 21.01 3.50 Male No Sun Dinner 3 3 23.68 3.31 Male No Sun Dinner 2 4 24.59 3.61 Female No Sun Dinner 4
ВЫБРАТЬ
В SQL выбор осуществляется с помощью списка столбцов, разделенных запятыми, которые вы выбираете (или *, чтобы выбрать все столбцы) –
SELECT total_bill, tip, smoker, time FROM tips LIMIT 5;
В Pandas выбор столбцов выполняется путем передачи списка имен столбцов в ваш DataFrame –
tips[['total_bill', 'tip', 'smoker', 'time']].head(5)
Давайте проверим полную программу –
import pandas as pd url = 'https://raw.github.com/pandasdev/ pandas/master/pandas/tests/data/tips.csv' tips=pd.read_csv(url) print tips[['total_bill', 'tip', 'smoker', 'time']].head(5)
Его вывод выглядит следующим образом –
total_bill tip smoker time 0 16.99 1.01 No Dinner 1 10.34 1.66 No Dinner 2 21.01 3.50 No Dinner 3 23.68 3.31 No Dinner 4 24.59 3.61 No Dinner
Вызов DataFrame без списка имен столбцов покажет все столбцы (сродни SQL *).
ГДЕ
Фильтрация в SQL выполняется с помощью предложения WHERE.
SELECT * FROM tips WHERE time = 'Dinner' LIMIT 5;
Кадры данных могут быть отфильтрованы несколькими способами; наиболее интуитивно понятный из которых использует логическое индексирование.
tips[tips['time'] == 'Dinner'].head(5)
Давайте проверим полную программу –
import pandas as pd url = 'https://raw.github.com/pandasdev/ pandas/master/pandas/tests/data/tips.csv' tips=pd.read_csv(url) print tips[tips['time'] == 'Dinner'].head(5)
Его вывод выглядит следующим образом –
total_bill tip sex smoker day time size 0 16.99 1.01 Female No Sun Dinner 2 1 10.34 1.66 Male No Sun Dinner 3 2 21.01 3.50 Male No Sun Dinner 3 3 23.68 3.31 Male No Sun Dinner 2 4 24.59 3.61 Female No Sun Dinner 4
Вышеприведенный оператор передает серию объектов True / False в DataFrame, возвращая все строки с True.
Группа по
Эта операция извлекает количество записей в каждой группе в наборе данных. Например, запрос, извлекающий нам количество советов, оставленных полом –
SELECT sex, count(*) FROM tips GROUP BY sex;
Эквивалент панд будет:
tips.groupby('sex').size()
Давайте проверим полную программу –
import pandas as pd url = 'https://raw.github.com/pandasdev/ pandas/master/pandas/tests/data/tips.csv' tips=pd.read_csv(url) print tips.groupby('sex').size()
Его вывод выглядит следующим образом –
sex Female 87 Male 157 dtype: int64
Топ N строк
SQL возвращает верхние n строк, используя LIMIT –
SELECT * FROM tips LIMIT 5 ;
Эквивалент панд будет:
tips.head(5)
Давайте проверим полный пример –
import pandas as pd url = 'https://raw.github.com/pandas-dev/pandas/master/pandas/tests/data/tips.csv' tips=pd.read_csv(url) tips = tips[['smoker', 'day', 'time']].head(5) print tips
Его вывод выглядит следующим образом –
smoker day time 0 No Sun Dinner 1 No Sun Dinner 2 No Sun Dinner 3 No Sun Dinner 4 No Sun Dinner
Это те немногие основные операции, которые мы сравнили, которые мы изучили в предыдущих главах Библиотеки Панд.