Мы составили гайд по GraphQL для начинающих. GraphQL — это язык запросов с открытым исходным кодом, создавался как более эффективная альтернатива REST для разработки и использования программных интерфейсов приложений.
- С чего начать?
- Схема
- Типы
- Запросы
- Изменения
- Подписки
- Заключение
GraphQL обладает множеством достоинств, например:
- Вы получаете информацию именно в том объёме, в котором запрашиваете..
- Вам будет необходима всего одна конечная точка.
- GraphQL — сильно типизированный язык, что позволяет предварительно оценить корректность запроса в рамках системы типов синтаксиса.
С чего начать?
Чтобы понять, как применять стандарт на практике, используем сервер в базовой конфигурации — Graphpack.
Нужно создать новую папку для проекта. В данном случае имя папки будет graphql-server, однако название не принципиально. Откройте терминал и введите:
mkdir graphql-serverНа компьютере должен быть установлен npm или yarn. Перейдите в созданную папку и введите команду в зависимости от используемого менеджера:
npm init -yили
yarn init npm создаст файл package.json, в котором будут храниться все созданные вами зависимости и команды. Теперь нужно установить одну зависимость, которую мы будем использовать в рамках этой статьи.
Graphpack позволяет создать сервер GraphQL с базовой конфигурацией. Используя терминал, в корневой папке проекта установите Graphpack с помощью команды:
npm install --save-dev graphpackЕсли вы используете yarn:
yarn add --dev graphpackПерейдите к файлу package.json и добавьте следующий код:
"scripts": {
"dev": "graphpack",
"build": "graphpack build"
}Создайте на сервере папку src. В этом примере это будет единственная папка на сервере, в которой необходимо создать три файла. В src создайте файл schema.graphql. В файл добавьте код:
type Query {
hello: String
}В этом файле будет находиться вся схема GraphQL.
Создайте второй файл в той же папке, назовите его resolvers.js. Разместите там следующий код:
import { users } from "./db";
const resolvers = {
Query: {
hello: () => "Hello World!"
}
};
export default resolvers;В этом файле будут размещены инструкции по выполнению операций GraphQL.
Создайте третий файл, db.js, содержащий код:
export let users = [
{ id: 1, name: "John Doe", email: "john@gmail.com", age: 22 },
{ id: 2, name: "Jane Doe", email: "jane@gmail.com", age: 23 }
];Для тестирования работы GraphQL начинающим специалистам нет нужды использовать настоящие данные. Этот файл нужен для симуляции обращений к базе данных.
После выполнения операций папка src должна выглядеть следующим образом:
src
|--db.js
|--resolvers.js
|--schema.graphqlТеперь выполните команду npm run dev для npm или yarn dev для yarn. Терминал должен вывести информацию об успешном запуске сервера: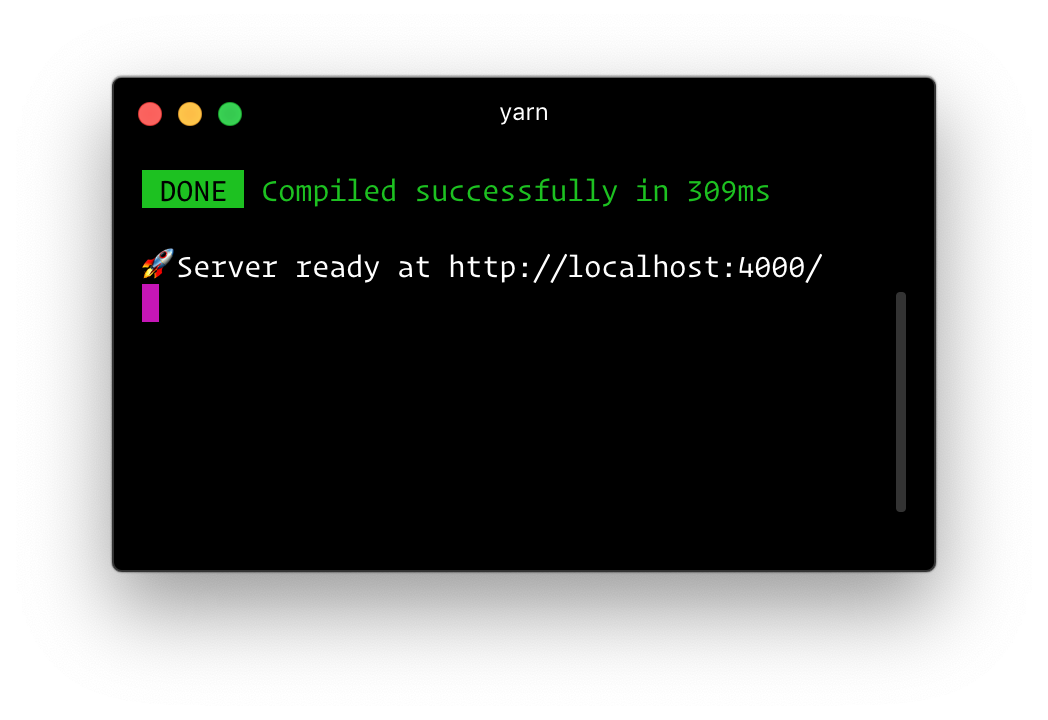
Теперь можно перейти к localhost:4000. Система готова к работе над GraphQL API. Для разработки используется IDE GraphQL Playground.
Схема
GraphQL прост для начинающих благодаря собственному языку — Schema Definition Language (SDL). SDL обладает интуитивно понятным синтаксисом и универсален для любой используемой технологии.
Типы
Типы — одна из основных особенностей языка запросов GraphQL. Это кастомные объекты, которые определяют, как будет выглядеть GraphQL API. Например, при разработке программного интерфейса для приложения, взаимодействующего с соцсетями, в API стоит объявить типы Posts, Users, Likes, Groups.
В типах есть поля, возвращающие определённые разновидности данных. Например, при создании типа User, в него стоит включить поля name, email, и age. Поля типов могут быть любыми и всегда возвращают данные в формате Int, Float, String, Boolean, ID, List of Object Types, или Custom Objects Types.
Чтобы создать первый тип, откройте файл schema.graphql и замените ранее прописанный там тип Query следующим кодом:
type User {
id: ID!
name: String!
email: String!
age: Int
}Каждая запись типа User должна иметь идентификационный номер, поэтому поле id содержит данные соответствующего типа. Поля name и email содержат String (переменную типа строки символов), а age — целочисленную переменную.
Восклицательный знак в конце определения поля означает, что это поле не может быть пустым. Единственное поле без восклицательного знака — age.
Язык запросов GraphQL оперирует тремя основными концепциями:
- queries, запросы — с их помощью получают данные с сервера.
- mutations, изменения — модификация данных на сервере и их обновление.
- subscriptions , подписки — методы поддержания постоянной связи с сервером.
Запросы
Откройте файл schema.graphql и добавьте тип Query:
type Query {
users: [User!]!
}Запрос users будет возвращать массив из одной и более записей типа User. Поскольку в определении использованы восклицательные знаки, ответ на запрос не может быть пустым.
Для получения конкретной записи User необходимо создать соответствующий запрос. В данном случает это будет запрос user в типе Query. Добавьте в код следующую строку:
user(id: ID!): User!Теперь код должен выглядеть так:
type Query {
users: [User!]!
user(id: ID!): User!
}Как видите, в запросах GraphQL можно передавать аргументы. В данном случае для получения конкретной записи в запросе в качестве аргумента используется её поле id.
Местонахождение данных, которые будут обрабатываться в соответствии с запросом, определяется в файле resolvers.js. Откройте этот файл и импортируйте учебную базу данных db.js:
import { users } from "./db";
const resolvers = {
Query: {
hello: () => "Hello World!"
}
};
export default resolvers;Затем замените функцию hello на user и users:
import { users } from "./db";
const resolvers = {
Query: {
user: (parent, { id }, context, info) => {
return users.find(user => user.id === id);
},
users: (parent, args, context, info) => {
return users;
}
}
};
export default resolvers;В каждом резолвере запроса есть четыре аргумента. В запросе user в качестве аргумента передаётся содержимое поля id записи базы данных. Сервер возвращает содержимое подходящей записи. Запрос users не содержит аргументов и всегда возвращает весь массив целиком.
Для тестирования получившегося кода перейдите к localhost:4000.
Следующий код должен вернуть список всех записей db.js:
query {
users {
id
name
email
age
}
}Получить первую запись из базы можно с помощью этого кода:
query {
user(id: 1) {
id
name
email
age
}
}Изменения
В GraphQL изменения — способ модифицировать данные на сервере и получить обработанную информацию. Этот процесс можно рассматривать как аналогичный концепции CUD (Create, Update, Delete) в стандарте REST.
Для создания изменения откройте файл schema.graphqlи добавьте новый тип mutation:
type Mutation {
createUser(id: ID!, name: String!, email: String!, age: Int): User!
updateUser(id: ID!, name: String, email: String, age: Int): User!
deleteUser(id: ID!): User!
}В данном случае указано три различных изменения:
createUser: необходимо передать значение полейid,name,emailиage. Функция возвращает запись типаUser.updateUser: необходимо передать значение поляid, новое значение поляname,emailилиage. Функция возвращает запись типаUser.deleteUser: необходимо передать значение поляid. Функция возвращает запись типаUser.
Теперь откройте файл resolvers.js и ниже объекта Query создайте новый объект mutation:
Mutation: {
createUser: (parent, { id, name, email, age }, context, info) => {
const newUser = { id, name, email, age };
users.push(newUser);
return newUser;
},
updateUser: (parent, { id, name, email, age }, context, info) => {
let newUser = users.find(user => user.id === id);
newUser.name = name;
newUser.email = email;
newUser.age = age;
return newUser;
},
deleteUser: (parent, { id }, context, info) => {
const userIndex = users.findIndex(user => user.id === id);
if (userIndex === -1) throw new Error("User not found.");
const deletedUsers = users.splice(userIndex, 1);
return deletedUsers[0];
}
}
Полный код файла resolvers.js должен выглядеть так:
import { users } from "./db";
const resolvers = {
Query: {
user: (parent, { id }, context, info) => {
return users.find(user => user.id === id);
},
users: (parent, args, context, info) => {
return users;
}
},
Mutation: {
createUser: (parent, { id, name, email, age }, context, info) => {
const newUser = { id, name, email, age };
users.push(newUser);
return newUser;
},
updateUser: (parent, { id, name, email, age }, context, info) => {
let newUser = users.find(user => user.id === id);
newUser.name = name;
newUser.email = email;
newUser.age = age;
return newUser;
},
deleteUser: (parent, { id }, context, info) => {
const userIndex = users.findIndex(user => user.id === id);
if (userIndex === -1) throw new Error("User not found.");
const deletedUsers = users.splice(userIndex, 1);
return deletedUsers[0];
}
}
};
export default resolvers;Сделайте запрос к localhost:4000:
mutation {
createUser(id: 3, name: "Robert", email: "robert@gmail.com", age: 21) {
id
name
email
age
}
}Он должен вернуть новую запись типа User. Опробуйте также остальные функции изменения.
Подписки
С помощью подписок поддерживается постоянная связь между клиентами и сервером. Базовая подписка выглядит следующим образом:
subscription {
users {
id
name
email
age
}
}Несмотря на то что этот код выглядит похожим на запрос, работает он несколько иначе. При обновлении данных сервер выполняет определённый в подписке запрос GraphQL и рассылает обновлённые данные клиентам.
Заключение
GarphQL набирает популярность. В рамках опроса State of JavaScript, проведённого среди JS-разработчиков, более половины респондентов указали, что слышали об этой технологии и хотели бы с ней ознакомиться, а пятая часть уже её использует и не намерена отказываться.
Надеемся, что наше руководство по GraphQL для начинающих окажется полезным и заинтересует в дальнейшем изучении.
Перевод статьи A Beginner’s Guide to GraphQL
Это руководство по GraphQL. Из него вы узнаете базовую теорию, а также научитесь писать простые запросы с помощью GraphQL.
- Что такое GraphQL: теоретический ликбез
- Query: запросы в GraphQL
- Mutation: мутации в GraphQL
- Subscription: подписки в GraphQL
- Как работать с сервером GraphQL
- База данных
- Схема
- Resolver
- REST vs. GraphQL
- Заключение
Что такое GraphQL: теоретический ликбез
Прежде чем рассматривать GraphQL, давайте уделим внимание исторической базе. Что такое SQL — structured query language или язык структурированных запросов?
SQL — декларативный язык программирования, который применяется для создания, изменения и управления данными в базах данных. Этот язык поддерживает четыре базовых оператора запросов: SELECT, INSERT, UPDATE и DELETE. С помощью SQL мы можем запросить из базы данных (БД) именно то, что нам необходимо.
Прокачивайте свой уровень программирования:
На Хекслете есть несколько десятков треков — специальных курсов для опытных программистов, позволяющие повысить уровень компетентности разработчика в разных направлениях.
Например, когда необходимо «достать» из БД всех пользователей с именем Maria, это можно сделать с помощью запроса:
SELECT * FROM USERS WHERE FirstName = "Maria"
Решить эту задачу с помощью REST можно несколькими способами:
- Определить endpoint на сервере, который будет отдавать из базы данных пользователей с
fnameMaria. - Определить общий endpoint для получения всех пользователей и фильтровать полученный список на стороне клиента.
users.filter(user => user.fname === "Maria");
При этом в каждом из вариантов есть свои минусы. Первый подход нельзя масштабировать, так как нет возможности создать endpoint для каждого пользователя. Если мы используем второй подход, повышается нагрузка на сеть, а также появляется необходимость в постобработке на стороне клиента.
А теперь представьте инструмент, который объединяет возможности SQL и REST на стороне клиента. Вы уже догадались, что он называется GraphQL. Этот инструмент берёт идеи, разработанные для манипуляции данными в БД, и использует их в вебе. Поэтому с помощью одного запроса GraphQL можно получить сразу все необходимые данные.
Ниже представлена информация, необходимая для начала работы с GraphQL.
Query: запросы в GraphQL
С помощью запросов GraphQL получает необходимые данные с сервера. Тип запроса Query в GraphQL — аналог GET в REST. Запросы — строки, которые отправляются в теле HTTP POST-запроса.
Примечание — Обратите внимание, все типы запросов в GraphQL отправляются через POST.
Query описывает данные, которые необходимо получить с сервера. Например, с помощью кода ниже можно получить fname и age всех пользователей в базе данных.
query {
users {
fname
age
}
}
В ответ на этот запрос сервер присылает данные в формате JSON. Структура ответа соответствует структуре запроса.
data : {
users [
{
"fname": "Joe",
"age": 23
},
{
"fname": "Betty",
"age": 29
}
]
}
Успешные операции возвращают JSON с ключом «data» и с ключом «error», а неуспешные возвращают JSON с ключом и сообщением об ошибке. Благодаря этому удобно обрабатывать ошибки на стороне клиента.
Mutation: мутации в GraphQL
Mutation — ещё один root types. С его помощью можно добавлять данные в БД. Mutation — аналог POST и PUT в REST. Ниже пример кода.
mutation createUser{
addUser(fname: "Richie", age: 22) {
id
}
}
Здесь создаётся мутация createUser, которая добавляет в БД пользователя с fname Richie и age 22. В ответ на этот запрос сервер присылает JSON с id записи. Ответ выглядит так:
data : {
addUser : "a36e4h"
}
Subscription: подписки в GraphQL
Subscription — третий тип операций в GraphQL. С его помощью клиент слушает изменения в БД в режиме реального времени. Под капотом подписки используют вебсокеты. Пример кода:
subscription listenLikes {
listenLikes {
fname
likes
}
}
С помощью этого запроса можно получать список пользователей с именами и количеством лайков каждый раз, когда оно меняется.
Например, когда пользователь с fname Richie получает лайк, ответ будет таким:
data: {
listenLikes: {
"fname": "Richie",
"likes": 245
}
}
Подобный запрос можно использовать для обновления количества лайков в режиме реального времени в соответствующем интерфейсе, например, в форме с результатами голосования на сайте.
Выше представлены три основных типа запросов в GraphQL. Несмотря на поверхностное знакомство, вы получили достаточно знаний, чтобы начать работать со схемой GraphQL.
Как работать с сервером GraphQL
Рассмотрим ответ на этот вопрос на конкретном примере.
Цель: настроить сервер GraphQL, который отвечает на три типа запросов к БД NoSQL, в которой есть список пользователей с такой структурой:
[{
"id": 1,
"fname": "Richie",
"age": 27,
"likes": 8
},
{
"id": 2,
"fname": "Betty",
"age": 20,
"likes": 205
},
{
"id" : 3,
"fname": "Joe",
"age": 28,
"likes": 10
}]
Также в базе данных есть списки постов, которые опубликовали пользователи.
[{
id: 1,
userId: 2,
body: "Hello how are you?"
},
{
id: 1,
userId: 3,
body: "What's up?"
},
{
id: 1,
userId: 1,
body: "Let's learn GraphQL"
}]
Для дальнейшей работы понадобится сервер Apollo. Это сервер GraphQL с открытым исходным кодом.
Настройте проект и установите зависимости:
> mkdir graphql-server-example
> cd graphql-server-example
> npm init -y
Вы создали пустой проект. Теперь установите GraphQL, Apollo и nodemon для отслеживания изменений в файлах.
> npm install apollo-server graphql nodemon
Чтобы nodemon работал, добавьте в package.json запись:
"scripts": "start": "nodemon -e js, json, graphql"
База данных
Данные в этом примере поместим в переменную JSON. В реальных проектах данные обычно хранятся в БД. В тестовом проекте данные хранятся в index.js. Вот они:
const users = [
{
id: 1,
fname: 'Richie',
age: 27,
likes: 0,
},
{
id: 2,
fname: 'Betty',
age: 20,
likes: 205,
},
{
id: 3,
fname: 'Joe',
age: 28,
likes: 10,
},
];
const posts = [
{
id: 1,
userId: 2,
body: "Hello how are you?"
},
{
id: 1,
userId: 3,
body: "What's up?"
},
{
id: 1,
userId: 1,
body: "Let's learn GraphQL"
},
]
Теперь можно перейти к работе с сервером GraphQL.
Схема
Работа с сервером GraphQL всегда начинается с разработки схемы (Schema). Она состоит из двух взаимосвязанных объектов: TypeDefs и Resolvers.
Выше были описаны основные типы GraphQL. Чтобы сервер мог с ними работать, эти типы необходимо определить. Объект typeDef определяет список типов, которые доступны в проекте. Код выглядит так:
const typeDefs = gql`
type User {
id: Int
fname: String
age: Int
likes: Int
posts: [Post]
}
type Post {
id: Int
user: User
body: String
}
type Query {
users(id: Int!): User!
posts(id: Int!): Post!
}
type Mutation {
incrementLike(fname: String!) : [User!]
}
type Subscription {
listenLikes : [User]
}
`;
В примере выше определяется тип User, в котором указываются fname, age, likes и другие данные. Для каждого поля определяется тип данных: String или Int. GraphQL поддерживает четыре типа данных: String, Int, Float, Boolean. Если в поле указан восклицательный знак, оно становится обязательным.
Также в примере выше определяются типы Query,Mutation и Subscription.
Первый тип, который содержит внутри себя тип Query, называется users. Он принимает id и возвращает объект с данными соответствующего пользователя. Это обязательное поле. Ещё один тип Query называется posts. Он устроен так же, как users.
type Query {
users(id: Int!): User!
posts(id: Int!): Post!
}
Тип Mutation называется incrementLike. Он принимает параметр fname и возвращает список пользователей.
type Mutation {
incrementLike(fname: String!) : [User!]
}
Тип Subscription называется listenLikes. Он возвращает список пользователей.
type Subscription {
listenLikes : [User]
}
После определения типов необходимо добавить их логику. Это нужно, чтобы сервер знал, как отвечать на запросы клиента. Эта задача решается с помощью Resolvers.
Также полезно
Когда Gatsby заменит WordPress: интервью с GraphQL-гуру Михаилом Новиковым.
Resolver
Resolver или распознаватель — функция, которая возвращает данные для определённого поля. Resolver’ы возвращают данные того типа, который определён в схеме. Распознаватели могут быть асинхронными. С их помощью можно получать данные из REST API, базы данных или другого источника.
Определим Resolver’ы:
const resolvers = {
Query: {
users(root, args) { return users.filter(user => user.id === args.id)[0] },
posts(root, args) { return posts.filter(post => post.id === args.id)[0] }
},
User: {
posts: (user) => {
return posts.filter(post => post.userId === user.id)
}
},
Post: {
user: (post) => {
return users.filter(user => user.id === post.userId)[0]
}
},
Mutation: {
incrementLike(parent, args) {
users.map((user) => {
if(user.fname === args.fname) user.likes++
return user
})
pubsub.publish('LIKES', {listenLikes: users});
return users
}
},
Subscription: {
listenLikes: {
subscribe: () => pubsub.asyncIterator(['LIKES'])
}
}
};
В примере выше есть шесть функций:
- запрос
usersвозвращает объект пользователя, соответствующий переданному id; - запрос
postsвозвращает объект поста, соответствующий переданному id; - в поле
postsUserраспознаватель принимает данные пользователя и возвращает список его постов; - в поле
userPostsфункция принимает данные поста и возвращает пользователя, который опубликовал пост; - мутация
incrementLikeизменяет объектusers: увеличивает количествоlikesдля пользователя с соответствующимfname. После этогоusersпубликуются вpubsubс названиемLIKES; - подписка
listenLikesслушаетLIKESи отвечает при обновленииpubsub.
Два слова о pubsub. Этот инструмент представляет собой систему передачи информации в режиме реального времени с использованием вебсокетов. pubsub удобно использовать, так как всё, что касается вебсокетов, вынесено в отдельные абстракции.
Итак, работа с типами и распознавателями завершена. Теперь можно запустить сервер.

Запускаем сервер
Откройте http://localhost:4000/ в браузере. Благодаря Apollo вы можете полноценно протестировать сервер GraphQL.
Потратили 15 минут на настройку сервера и, вуаля, написали первый запрос. Полная версия кода опубликована здесь.
REST vs. GraphQL
Что делать, если нам нужно найти пользователя, который опубликовал пост с id x? Рассмотрим, как эта задача решается с помощью REST. Вот данные:
Users:
{
"id": 1,
"fname": "Richie",
"age": 27,
"likes": 8
},
{
"id": 2,
"fname": "Betty",
"age": 20,
"likes": 205
},
{
"id" : 3,
"fname": "Joe",
"age": 28,
"likes": 10
}
Posts:
{
id: 1,
userId: 2,
body: "Hello how are you?"
},
{
id: 1,
userId: 3,
body: "What's up?"
},
{
id: 1,
userId: 1,
body: "Let's learn GraphQL"
}
Сначала необходимо определить endpoint’ы GET:
> https://localhost:4000/users/:id
> https://localhost:4000/posts/:id
Когда необходимо получить данные о пользователе, который опубликовал пост с id 1, запрос выглядит так:
GET https://localhost:4000/posts/1
Response:
{
id: 1,
userId: 2,
body: "Hello how are you?"
}
GET https://localhost:4000/users/2
Response:
{
"id": 2,
"fname": "Betty",
"age": 20,
"likes": 205
}
Чтобы получить нужные данные, приходится дважды обращаться к серверу.
Что делать, если нужно получить только имя пользователя? Конечно, можно использовать данные поля fname. Но мы уже получили дополнительные данные: id, likes, age. Операция становится слишком дорогой.
Можно попробовать использовать endpoint, который получает только данные из поля fname:
https://localhost:4000/userByfname/:id
Это решает проблему. Но сложность в том, что вам придётся создавать endpoint для каждого типа информации. Это неудобно.
Давайте посмотрим, как можно решить задачу с помощью GraphQL. Всё, что вам требуется — простой запрос:
{
posts(id: 1) {
body
user {
fname
}
}
}
Если нужно получить age пользователя, который опубликовал пост с id 1, запрос будет таким:
{
posts(id: 1) {
body
user {
age
}
}
}
Поле user в запросе определено в схеме. Поэтому вы можете получать нужную информацию без использования endpoint’ов и повторных обращений к серверу.
Изучайте Node.js на Хекслете
Первые курсы в профессии «Node.js-программист» доступны бесплатно. Регистрируйтесь и начинайте учиться.
Заключение
В руководстве рассмотрена базовая информация о GraphQL: краткая теория, типы, отличия от REST. В комментариях можно поделиться впечатлениями о GraphQL и опытом применения этого инструмента.
Адаптированный перевод статьи So, What the Heck is GraphQL by Karthik Kalyanaraman. Мнение автора оригинальной публикации может не совпадать с мнением администрации «Хекслета».
Никогда не останавливайтесь:
В программировании говорят, что нужно постоянно учиться даже для того, чтобы просто находиться на месте. Развивайтесь с нами — на Хекслете есть сотни курсов по разработке на разных языках и технологиях.
GraphQL сейчас, без преувеличения, это — последний писк IT-моды. И если вы пока не знаете о том, что это за технология, о том, как ей пользоваться, и о том, почему она может вам пригодиться, значит статья, перевод которой мы сегодня публикуем, написана специально для вас. Здесь мы разберём основы GraphQL на примере реализации схемы данных для API компании, которая занимается попкорном. В частности, поговорим о типах данных, запросах и мутациях.

Что такое GraphQL?
GraphQL — это язык запросов, используемый клиентскими приложениями для работы с данными. C GraphQL связано такое понятие, как «схема» — это то, что позволяет организовывать создание, чтение, обновление и удаление данных в вашем приложении (то есть — перед нами четыре базовые функции, используемые при работе с хранилищами данных, которые обычно обозначают акронимом CRUD — create, read, update, delete).
Выше было сказано, что GraphQL используется для работы с данными в «вашем приложении», а не «в вашей базе данных». Дело в том, что GraphQL — это система, независимая от источников данных, то есть, для организации её работы неважно — где именно хранятся данные.
Если взглянуть, ничего не зная о GraphQL, на название этой технологии, то может показаться, что перед нами что-то очень сложное и запутанное. В названии технологии имеется слово «Graph». Означает ли это, что для того, чтобы её освоить, придётся учиться работать с графовыми базами данных? А то, что в названии есть «QL» (что может значить «query language», то есть — «язык запросов»), означает ли, что тем, кто хочет пользоваться GraphQL, придётся осваивать совершенно новый язык программирования?
Эти страхи не вполне оправданы. Для того чтобы вас успокоить — вот жестокая правда об этой технологии: она представляет собой всего лишь приукрашенные GET или POST запросы. В то время как GraphQL, в целом, вводит некоторые новые концепции, касающиеся организации данных и взаимодействия с ними, внутренние механизмы этой технологии полагаются на старые добрые HTTP-запросы.
Переосмысление технологии REST
Гибкость — это то, что отличает технологию GraphQL от широко известной технологии REST. При использовании REST, если всё сделано правильно, конечные точки обычно создают с учётом особенностей некоего ресурса или типа данных приложения.
Например, при выполнении GET-запроса к конечной точке /api/v1/flavors ожидается, что она отправит ответ, выглядящий примерно так:
[
{
"id": 1,
"name": "The Lazy Person's Movie Theater",
"description": "That elusive flavor that you begrudgingly carted yourself to the theater for, now in the comfort of your own home, you slob!"
}, {
"id": 2,
"name": "What's Wrong With You Caramel",
"description": "You're a crazy person that likes sweet popcorn. Congratulations."
}, {
"id": 3,
"name": "Gnarly Chili Lime",
"description": "The kind of popcorn you make when you need a good smack in the face."}
]В таком ответе ничего катастрофически неправильного нет, но подумаем о пользовательском интерфейсе, или скорее о том, как мы намереваемся потреблять эти данные.
Если мы хотим вывести в интерфейсе простой список, который содержит лишь названия имеющихся видов попкорна (и ничего другого), то этот список может выглядеть так, как показано ниже.

Список видов попкорна
Видно, что тут мы попали в непростую ситуацию. Мы вполне можем решить не использовать поле description, но собираемся ли мы сидеть сложа руки и делать вид, будто мы не отправляли это поле клиенту? А что нам ещё остаётся делать? А когда нас, через несколько месяцев, спросят о том, почему приложение так медленно работает у пользователей, нам останется лишь дать дёру и больше не встречаться с руководством компании, для которой мы сделали это приложение.
На самом деле, то, что сервер отправляет в ответ на запрос клиента ненужные данные, это не полностью наша вина. REST — это механизм получения данных, который можно сравнить с рестораном, в котором официант спрашивает посетителя: «Чего вы хотите?», и, не особенно обращая внимание на его пожелания, говорит ему: «Я принесу вам то, что у нас есть».
Если же отбросить в сторону шутки, то в реальных приложениях подобное может вести к проблемным ситуациям. Например, мы можем выводить различные дополнительные сведения о каждом виде попкорна, наподобие сведений о цене, информации о производителе или диетологических сведений («Веганский попкорн!»). При этом негибкие конечные точки REST сильно усложняют получение специфических данных о конкретных видах попкорна, что ведёт к неоправданно высокой нагрузке на системы и к тому, что получающиеся решения оказываются далеко не такими, которыми разработчики могли бы гордиться.
Как технология GraphQL улучшает то, для чего использовалась технология REST
При поверхностном анализе вышеописанной ситуации может показаться, что перед нами всего лишь незначительная проблема. «Что плохого в том, что мы отправляем клиенту ненужные данные?». Для того чтобы понять масштабы, в которых «ненужные данные» могут стать большой проблемой, вспомним о том, что технология GraphQL была разработана компанией Facebook. Этой компании приходится обслуживать миллионы запросов в секунду.
Что это значит? А то, что при таких объёмах значение имеет каждая мелочь.
GraphQL, если продолжить аналогию с рестораном, вместо того, чтобы «нести» посетителю «то, что есть», приносит именно то, что посетитель заказывает.
Мы можем получить от GraphQL ответ, ориентированный на тот контекст, в котором используются данные. При этом нам не нужно добавлять в систему «одноразовые» точки доступа, выполнять множество запросов или писать многоэтажные условные конструкции.
Как работает GraphQL?
Как мы уже говорили, GraphQL, для передачи данных клиенту и получения их от него, полагается на простые GET или POST-запросы. Если подробнее рассмотреть эту мысль, то оказывается, что в GraphQL есть два вида запросов. К первому виду относятся запросы на чтение данных, которые в терминологии GraphQL называются просто запросами (query) и относятся к букве R (reading, чтение) акронима CRUD. Запросы второго вида — это запросы на изменение данных, которые в GraphQL называют мутациями (mutation). Они относятся к буксам C, U и D акронима CRUD, то есть — с их помощью выполняют операции создания (create), обновления (update) и удаления (delete) записей.
Все эти запросы и мутации отправляют на URL GraphQL-сервера, который, например, может выглядеть как https://myapp.com/graphql, в виде GET или POST-запросов. Подробнее об этом мы поговорим ниже.
Запросы GraphQL
Запросы GraphQL — это сущности, представляющие собой запрос к серверу на получение неких данных. Например, у нас есть некий пользовательский интерфейс, который мы хотим заполнить данными. За этими данными мы и обращаемся к серверу, выполняя запрос. При использовании традиционных REST API наш запрос принимает вид GET-запроса. При работе с GraphQL используется новый синтаксис построения запросов:
{
flavors {
name
}
}Это что, JSON? Или JavaScript-объект? Ни то и ни другое. Как мы уже говорили, в названии технологии GraphQL две последние буквы, QL, означают «query language», то есть — язык запросов. Речь идёт, в буквальном смысле, о новом языке написания запросов на получение данных. Звучит всё это как описание чего-то довольно сложного, но на самом деле ничего сложного тут нет. Разберём вышеприведённый запрос:
{
// Сюда помещают описания полей, которые нужно получить.
}
Все запросы начинаются с «корневого запроса», а то, что нужно получить в ходе выполнения запроса, называется полем. Для того чтобы избавить себя от путаницы, лучше всего называть эти сущности «полями запроса в схеме». Если вам такое наименование кажется непонятным — подождите немного — ниже мы подробнее поговорим о схеме. Здесь мы, в корневом запросе, запрашиваем поле flavors.
{
flavors {
// Вложенные поля, которые мы хотим получить для каждого значения flavor.
}
}Запрашивая некое поле, мы, кроме того, должны указать вложенные поля, которые нужно получить для каждого объекта, который приходит в ответе на запрос (даже если ожидается, что в ответ на запрос придёт всего один объект).
{
flavors {
name
}
}Что в итоге получится? После того, как мы отправим такой запрос GraphQL-серверу, мы получим хорошо оформленный аккуратный ответ наподобие следующего:
{
"data": {
"flavors": [
{ "name": "The Lazy Person's Movie Theater" },
{ "name": "What's Wrong With You Caramel" },
{ "name": "Gnarly Chili Lime" }
]
}
}Обратите внимание на то, что здесь нет ничего лишнего. Для того чтобы было понятнее — вот ещё один запрос, выполняемый для получения данных на другой странице приложения:
{
flavors {
id
name
description
}
}В ответ на этот запрос мы получим следующее:
{
"data": {
"flavors": [
{ "id": 1, "name": "The Lazy Person's Movie Theater", description: "That elusive flavor that you begrudgingly carted yourself to the theater for, now in the comfort of your own home, you slob!" },
{ "id": 2, "name": "What's Wrong With You Caramel", description: "You're a crazy person that likes sweet popcorn. Congratulations." },
{ "id": 3, "name": "Gnarly Chili Lime", description: "A friend told me this would taste good. It didn't. It burned my kernels. I haven't had the heart to tell him." }
]
}
}Как видите, GraphQL — очень мощная технология. Обращаемся мы к одной и той же конечной точке, а ответы на запросы в точности соответствуют тому, что нужно для наполнения той страницы, с которой выполняются эти запросы.
Если нам нужно получить лишь один объект flavor, то мы можем воспользоваться тем фактом, что GraphQL умеет работать с аргументами:
{
flavors(id: "1") {
id
name
description
}
}
Тут мы жёстко задали в коде конкретный идентификатор (id) объекта, сведения о котором нам нужны, но в подобных случаях можно использовать и динамические идентификаторы:
query getFlavor($id: ID) {
flavors(id: $id) {
id
name
description
}
}
Здесь, в первой строке, мы даём запросу имя (имя выбирается произвольным образом, getFlavor можно заменить на нечто вроде pizza, и запрос останется работоспособным) и объявляем переменные, которые ожидает запрос. В данном случае предполагается, что запросу будет передан идентификатор (id) скалярного типа ID (о типах мы поговорим ниже).
Независимо от того, статический или динамический id используется при выполнении запроса, вот как будет выглядеть ответ на подобный запрос:
{
"data": {
"flavors": [
{ "id": 1, "name": "The Lazy Person's Movie Theater", description: "That elusive flavor that you begrudgingly carted yourself to the theater for, now in the comfort of your own home, you slob!" }
]
}
}
Как видите, всё устроено очень удобно. Вероятно, вы уже начинаете размышлять о применении GraphQL в собственном проекте. И, хотя то, о чём мы уже говорили, выглядит замечательно, красота GraphQL по-настоящему проявляется там, где работают с вложенными полями. Предположим, что в нашей схеме есть ещё одно поле, которое называется nutrition и содержит сведения о пищевой ценности разных видов попкорна:
{
flavors {
id
name
nutrition {
calories
fat
sodium
}
}
}
Может показаться, что в нашем хранилище данных, в каждом объекте flavor, будет содержаться вложенный объект nutrition. Но это не совсем так. Используя GraphQL можно комбинировать обращения к самостоятельным, но связанным источникам данных в одном запросе, что позволяет получать ответы, дающие удобство работы с вложенными данными без необходимости денормализации базы данных:
{
"data": {
"flavors": [
{
"id": 1,
"name": "The Lazy Person's Movie Theater",
"nutrition": {
"calories": 500,
"fat": 12,
"sodium": 1000
}
},
...
]
}
}Это способно значительно увеличить продуктивность труда программиста и скорость работы системы.
До сих пор мы говорили о запросах на чтение. А как насчёт запросов на обновление данных? Их использование даёт нам те же удобства?
Мутации GraphQL
В то время как запросы GraphQL выполняют загрузку данных, мутации ответственны за внесение в данные изменений. Мутации могут быть использованы в виде базового механизма RPC (Remote Procedure Call, вызов удалённых процедур) для решения различных задач наподобие отправки данных пользователя API стороннего разработчика.
При описании мутаций используется синтаксис, напоминающий тот, который мы применяли при формировании запросов:
mutation updateFlavor($id: ID!, $name: String, $description: String) {
updateFlavor(id: $id, name: $name, description: $description) {
id
name
description
}
}
Здесь мы объявляем мутацию updateFlavor, указывая некоторые переменные — id, name и description. Действуя по той же схеме, которая применяется при описании запросов, мы «оформляем» изменяемые поля (корневую мутацию) с помощью ключевого слова mutation, за которым следует имя, описывающее мутацию, и набор переменных, которые нужны для формирования соответствующего запроса на изменение данных.
Эти переменные включают в себя то, что мы пытаемся изменить, или то, мутацию чего мы хотим вызвать. Обратите внимание также и на то, что после выполнения мутации мы можем запросить возврат некоторых полей.
В данном случае нам нужно получить, после изменения записи, поля id, name и description. Это может пригодиться при разработке чего-то вроде оптимистичных интерфейсов, избавляя нас от необходимости выполнять запрос на получение изменённых данных после их изменения.
Разработка схемы и подключение её к GraphQL-серверу
До сих пор мы говорили о том, как GraphQL работает на клиенте, о том, как выполняют запросы. Теперь поговорим о том, как на эти запросы реагировать.
▍GraphQL-сервер
Для того, чтобы выполнить GraphQL-запрос, нужен GraphQL-сервер, которому можно такой запрос отправить. GraphQL-сервер представляет собой обычный HTTP-сервер (если вы пишете на JavaScript — то это может быть сервер, созданный с помощью Express или Hapi), к которому присоединена GraphQL-схема.
import express from 'express'
import graphqlHTTP from 'express-graphql'
import schema from './schema'
const app = express()
app.use('/graphql', graphqlHTTP({
schema: schema,
graphiql: true
}))
app.listen(4000)Под «присоединением» схемы мы понимаем механизм, который пропускает через схему запросы, полученные от клиента, и возвращает ему ответы. Это похоже на воздушный фильтр, через который воздух поступает в помещение.
Процесс «фильтрации» связан с запросами или мутациями, отправляемыми клиентом на сервер. И запросы и мутации разрешаются с использованием функций, связанных с полями, определёнными в корневом запросе или в корневой мутации схемы.
Выше приведён пример каркаса HTTP-сервера, созданного с помощью JavaScript-библиотеки Express. Используя функцию graphqlHTTP из пакета express-graphql от Facebook, мы «прикрепляем» схему (предполагается, что она описана в отдельном файле) и запускаем сервер на порту 4000. То есть, клиенты, если говорить о локальном использовании этого сервера, смогут отправлять запросы по адресу http://localhost:4000/graphql.
▍Типы данных и распознаватели
Для того чтобы обеспечить работу GraphQL-сервера, нужно подготовить схему и присоединить её к нему.
Вспомните о том, что выше мы говорили об объявлении полей в корневом запросе или в корневой мутации.
import gql from 'graphql-tag'
import mongodb from '/path/to/mongodb’ // Это - лишь пример. Предполагается, что `mongodb` даёт нам подключение к MongoDB.
const schema = {
typeDefs: gql`
type Nutrition {
flavorId: ID
calories: Int
fat: Int
sodium: Int
}
type Flavor {
id: ID
name: String
description: String
nutrition: Nutrition
}
type Query {
flavors(id: ID): [Flavor]
}
type Mutation {
updateFlavor(id: ID!, name: String, description: String): Flavor
}
`,
resolvers: {
Query: {
flavors: (parent, args) => {
// Предполагается, что args равно объекту, наподобие { id: '1' }
return mongodb.collection('flavors').find(args).toArray()
},
},
Mutation: {
updateFlavor: (parent, args) => {
// Предполагается, что args равно объекту наподобие { id: '1', name: 'Movie Theater Clone', description: 'Bring the movie theater taste home!' }
// Выполняем обновление.
mongodb.collection('flavors').update(args)
// Возвращаем flavor после обновления.
return mongodb.collection('flavors').findOne(args.id)
},
},
Flavor: {
nutrition: (parent) => {
return mongodb.collection('nutrition').findOne({
flavorId: parent.id,
})
}
},
},
}
export default schema
Определение полей в схеме GraphQL состоит из двух частей — из объявлений типов (typeDefs) и распознавателей (resolver). Сущность typeDefs содержит объявления типов для данных, используемых в приложении. Например, ранее мы говорили о запросе на получение с сервера списка объектов flavor. Для того чтобы к нашему серверу можно было бы выполнить подобный запрос, нужно сделать следующие три шага:
- Сообщить схеме о том, как выглядят данные объектов
flavor(в примере, приведённом выше, это выглядит как объявление типаtype Flavor). - Объявить поле в корневом поле
type Query(это свойствоflavorsзначенияtype Query). - Объявить функцию-распознаватель объекта
resolvers.Query, написанную в соответствии с полями, объявленными в корневом полеtype Query.
Обратим теперь внимание на typeDefs. Здесь мы сообщаем схеме сведения о форме (shape) наших данных. Другими словами, мы сообщаем GraphQL о разных свойствах, которые могут содержаться в сущностях соответствующего типа.
type Flavor {
id: ID
name: String
description: String
nutrition: Nutrition
}
Объявление type Flavor указывает на то, что объект flavor может содержать поле id типа ID, поле name типа String, поле description типа String и поле nutrition типа Nutrition.
В случае с nutrition мы используем здесь имя другого типа, объявленного в typeDefs. Здесь конструкция type Nutrition описывает форму данных о пищевой ценности попкорна.
Обратите внимание на то, что мы тут, как и в самом начале этого материала, говорим о «приложении», а не о «базе данных». В вышеприведённом примере предполагается, что у нас есть база данных, но данные в приложение могут поступать из любого источника. Это может быть даже API стороннего разработчика или статический файл.
Так же, как мы поступали в объявлении type Flavor, здесь мы указываем имена полей, которые будут содержаться в объектах nutrition, используя, в качестве типов данных этих полей (свойств) то, что в GraphQL называется скалярными типами данных. На момент написания этого материала в GraphQL поддерживалось 5 встроенных скалярных типов данных:
Int: целое 32-битное число со знаком.Float: число двойной точности с плавающей точкой со знаком.String: последовательность символов в кодировке UTF-8.Boolean: логическое значениеtrueилиfalse.ID: уникальный идентификатор, часто используемый для многократной загрузки объектов или в качестве ключа в кэше. Значения типаIDсериализуются так же, как строки, однако указание на то, что некое значение имеет типID, подчёркивает тот факт, что это значение предназначено не для показа его людям, а для использования в программах.
В дополнение к этим скалярным типам мы можем назначать свойствам и типы, определённые нами самостоятельно. Именно так мы поступили, назначив свойству nutrition, описанному в конструкции type Flavor, тип Nutrition.
type Query {
flavors(id: ID): [Flavor]
}
В конструкции type Query, в которой описывается корневой тип Query (тот «корневой запрос», о котором мы говорили ранее), мы объявляем имя поля, которое может быть запрошено. Объявляя это поле, мы, кроме того, вместе с типом данных, который ожидаем вернуть, указываем аргументы, которые могут поступить в запросе.
В данном примере мы ожидаем возможного поступления аргумента id скалярного типа ID. В качестве ответа на такой запрос ожидается массив объектов, устройство которых напоминает устройство типа Flavor.
▍Подключение распознавателя запросов
Теперь, когда в корневом type Query имеется определение поля field, нам нужно описать то, что называется функцией-распознавателем.
Это — то место, где GraphQL, более или менее, «останавливается». Если мы посмотрим на объект resolvers схемы, а затем на объект Query, вложенный в него, мы можем увидеть там свойство flavors, которому назначена функция. Эта функция и называется распознавателем для поля flavors, которое объявлено в корневом type Query.
typeDefs: gql`…`,
resolvers: {
Query: {
flavors: (parent, args) => {
// Предполагается, что args равно объекту наподобие { id: '1' }
return mongodb.collection('flavors').find(args).toArray()
},
},
…
},
Эта функция-распознаватель принимает несколько аргументов. Аргумент parent — это родительский запрос, если таковой существует, аргумент args тоже передаётся запросу в том случае, если он существует. Здесь ещё может использоваться аргумент context, который в нашем случае не представлен. Он даёт возможность работать с различными «контекстными» данными (например — со сведениями о текущем пользователе в том случае, если сервер поддерживает систему учётных записей пользователей).
Внутри распознавателя мы делаем всё, что нужно для того, чтобы выполнить запрос. Именно здесь GraphQL «перестаёт беспокоиться» о происходящем и позволяет нам выполнять загрузку и возврат данных. Тут, повторимся, можно работать с любыми источниками данных.
Хотя GraphQL и не интересуют источники поступления данных, эту систему чрезвычайно сильно интересует то, что именно мы возвращаем. Мы можем вернуть JSON-объект, массив JSON-объектов, промис (его разрешение GraphQL берёт на себя).
Тут мы используем мок-обращение к коллекции flavors базы данных MongoDB, передавая args (если соответствующий аргумент передан распознавателю) в вызов .find() и возвращая то, что будет найдено в результате выполнения этого вызова, в виде массива.
▍Получение данных для вложенных полей
Выше мы уже разобрали кое-что, относящееся к GraphQL, но сейчас, возможно, пока непонятно то, как быть с вложенным полем nutrition. Помните о том, что данные, представленные полем Nutrition, мы, на самом деле, не храним совместно с основными данными, описывающими сущность flavor. Мы исходим из предположения о том, что эти данные хранятся в отдельной коллекции/таблице базы данных.
Хотя мы сообщили GraphQL о том, что type Flavor может включать в себя данные nutrition в форме type Nutrition, мы не пояснили системе порядок получения этих данных из хранилища. Эти данные, как уже было сказано, хранятся отдельно от данных сущностей flavor.
typeDefs: gql`
type Nutrition {
flavorId: ID
calories: Int
fat: Int
sodium: Int
}
type Flavor {
[…]
nutrition: Nutrition
}
type Query {…}
type Mutation {…}
`,
resolvers: {
Query: {
flavors: (parent, args) => {…},
},
Mutation: {…},
Flavor: {
nutrition: (parent) => {
return mongodb.collection('nutrition').findOne({
flavorId: parent.id,
})
}
},
},
Если присмотреться повнимательнее к объекту resolvers в схеме, то можно заметить, что тут имеются вложенные объекты Query, Mutation и Flavor. Они соответствуют типам, которые мы объявили выше в typeDefs.
Если посмотреть на объект Flavors, то окажется, что поле nutrition в нём объявлено как функция-распознаватель. Заметной особенностью такого решения является тот факт, что мы объявляем функцию непосредственно в типе Flavor. Другими словами, мы говорим системе: «Мы хотим, чтобы ты загрузила поле nutrition именно так для любого запроса, использующего type Flavor».
В этой функции мы выполняем обычный запрос к MongoDB, но тут обратите внимание на то, что мы используем аргумент parent, переданный функции-распознавателю. То, что представлено здесь аргументом parent, представляет собой то, что содержится в полях, имеющихся во flavors. Например, если нам нужны все сущности flavor, мы выполним такой запрос:
{
flavors {
id
name
nutrition {
calories
}
}
}
Каждое поле flavor, возвращённое из flavors, мы пропустим через распознаватель nutrition, при этом данное значение будет представлено аргументом parent. Если присмотреться к этой конструкции, то окажется, что мы, в запросе к MongoDB, используем поле parent.id, которое представляет собой id сущности flavor, обработкой которой мы занимаемся в данный момент.
Идентификатор parent.id передаётся в запросе к базе данных, где производится поиск записи nutrition с идентификатором flavorId, которая соответствует обрабатываемой сущности flavor.
▍Подключение мутаций
То, что мы уже знаем о запросах, отлично переносится и на мутации. На самом деле, процесс подготовки мутаций практически полностью совпадает с процессом подготовки запросов. Если взглянуть на корневую сущность type Mutation, то можно увидеть, что мы объявили в ней поле updateFlavor, принимающее аргументы, задаваемые на клиенте.
type Mutation {
updateFlavor(id: ID!, name: String, description: String): Flavor
}
Этот код можно расшифровать так: «Мы ожидаем, что мутация updateFlavor принимает id типа ID (восклицательный знак, !, сообщает GraphQL о том, что это поле необходимо), name типа String и description типа String». Кроме того, после завершения выполнения мутации мы ожидаем возврат некоторых данных, структура которых напоминает тип Flavor (то есть — объект, который содержит свойства id, name, description, и, возможно, nutrition).
{
typeDefs: gql`…`,
resolvers: {
Mutation: {
updateFlavor: (parent, args) => {
// Предполагается, что args равно объекту наподобие { id: '1', name: 'Movie Theater Clone', description: 'Bring the movie theater taste home!' }
// Выполняем обновление.
mongodb.collection('flavors').update(
{ id: args.id },
{
$set: {
...args,
},
},
)
// Возвращаем flavor после обновления.
return mongodb.collection('flavors').findOne(args.id)
},
},
},
}
Внутри функции-распознавателя для мутации updateFlavor мы делаем именно то, чего от подобной функции можно ожидать: организуем взаимодействие с базой данных для того, чтобы изменить в ней, то есть — обновить, сведения об интересующей нас сущности flavor.
Обратите внимание на то, что сразу же после выполнения обновления обновление мы выполняем обращение к базе данных для того, чтобы снова найти ту же сущность flavor и вернуть её из распознавателя. Почему это так?
Вспомните о том, что на клиенте мы ожидаем получить объект в том состоянии, в которое он был приведён после завершения мутации. В данном примере мы ожидаем, что будет возвращена сущность flavor, которую мы только что обновили.
Можно ли просто вернуть объект args? Да, можно. Причина, по которой мы решили в данном случае этого не делать, заключается в том, что мы хотим быть на 100% уверенными в том, что операция обновления информации в базе данных прошла успешно. Если мы прочтём из базы данных информацию, которая должна быть изменённой, и окажется, что она и правда изменена, тогда можно сделать вывод о том, что операция выполнена успешно.
Зачем может понадобиться использовать GraphQL?
Хотя то, созданием чего мы только что занимались, выглядит не особенно масштабно, сейчас у нас есть функционирующее, хотя и простое, GraphQL-API.
Как и в случае с любой новой технологией, после первого знакомства с GraphQL вы можете задаться вопросом о том, зачем вам может пригодиться нечто подобное. Честно говоря, на этот вопрос нельзя дать однозначного и простого ответа. Очень уж много всего нужно учесть для того, чтобы такой ответ найти. И можно, кстати, подумать о том, чтобы вместо GraphQL просто выбрать проверенную временем технологию REST или напрямую обращаться к базе данных. Собственно говоря, вот несколько идей, над которыми стоит поразмыслить в поисках ответа на вопрос о том, нужна ли вам технология GraphQL.
▍Вы стремитесь уменьшить количество запросов, выполняемых с клиента
Многие приложения страдают от того, что им приходится выполнять слишком много HTTP-запросов, от того, что делать это приходится слишком часто, и от того, что это — сложные запросы. В то время как использование технологии GraphQL не позволяет полностью отказаться от выполнения запросов, эта технология, если ей правильно пользоваться, способна значительно уменьшить количество запросов, выполняемых со стороны клиента (во многих случаях для получения некоего набора связанных данных достаточно лишь одного запроса).
Является ли ваш проект приложением с множеством пользователей, или приложением, обрабатывающим огромные объёмы данных (например — это нечто вроде системы для работы с медицинскими данными), использование GraphQL определённо улучшит производительность его клиентской части.
▍Вы хотите избежать денормализации данных, проводимой лишь ради того, чтобы оптимизировать работу механизмов построения пользовательского интерфейса
В приложениях, в которых используются большие объёмы реляционных данных, часто может возникать «ловушка денормализации». Хотя такой подход и оказывается рабочим, он, вне всякого сомнения, далёк от идеала. Его применение может плохо влиять на производительность систем. Благодаря использованию GraphQL и вложенных запросов необходимость в денормализации данных значительно уменьшается.
▍У вас есть множество источников информации, к которым вы обращаетесь из разных приложений
Эта проблема может быть частично решена с помощью традиционных REST API, но даже при таком подходе одна проблема всё ещё остаётся: единообразие запросов, выполняемых с клиентской стороны. Предположим, что в ваш проект входят веб-приложение, приложения для iOS и Android, а также API для разработчиков. В подобных условиях вам, вероятнее всего, придётся, на каждой платформе, «мастерить из подручных материалов» средства для выполнения запросов.
Это ведёт к тому, что приходится поддерживать, на разных платформах, несколько реализаций HTTP, это означает отсутствие единообразия в средствах выполнения запросов и наличие запутанных конечных точек API (вы, наверняка, такое уже видели).
▍Может быть технология GraphQL — это верх совершенства? Стоит ли мне прямо сейчас выбросить мой REST API и перейти на GraphQL?
Нет, конечно. Ничто не совершенно. И, надо отметить, работать с GraphQL не так уж и просто. Для того чтобы создать работающую схему GraphQL, нужно выполнить множество обязательных шагов. Так как вы только изучаете данную технологию, это может вывести вас из равновесия, так как нелегко бывает понять то, чего именно не хватает в вашей схеме для правильной работы системы. При этом сообщения об ошибках, возникающих на клиенте и на сервере, могут оказаться не особенно полезными.
Далее, использование GraphQL на клиенте, в том, что выходит за рамки языка запросов, не стандартизовано. Хотя работу с GraphQL могут облегчить различные библиотеки, самыми популярными из которых являются Apollo и Relay, каждая из них отличается собственными специфическими особенностями.
GraphQL — это, кроме того, всего лишь спецификация. Пакеты вроде graphql (этот пакет используется внутри пакета express-graphql, применённого в нашем примере) — это всего лишь реализации данной спецификации. Другими словами, разные реализации GraphQL для разных языков программирования могут по-разному интерпретировать спецификацию. Это может привести к возникновению проблем, идёт ли речь о разработчике-одиночке, или о команде, в которой, при работе над разными проектами, используются разные языки программирования.
Итоги
Несмотря на то, что внедрение GraphQL может оказаться непростой задачей, эта технология представляет собой впечатляющий шаг вперёд в сфере обработки данных. GraphQL нельзя назвать лекарством от всех болезней, но с этой технологией, определённо, стоит поэкспериментировать. Начать можно, например, поразмыслив о самой запутанной и неопрятной подсистеме, используемой в вашем проекте при работе с данными, и попытавшись реализовать эту подсистему средствами GraphQL.
Кстати, тут у меня для вас приятная новость: GraphQL можно реализовывать инкрементно. Для того чтобы извлечь выгоды из применения этой технологии нет нужды переводить на GraphQL абсолютно всё. Так, постепенно вводя в проект GraphQL, можно разобраться с этой технологией самому, заинтересовать команду, и, если то, что получится, всех устроит, двигаться дальше.
Главное — помните о том, что GraphQL — это, в конечном счёте, всего лишь инструмент. Применение GraphQL не означает необходимости в полной переработке всего, что было раньше. При этом надо отметить, что GraphQL — это технология, с которой, определённо, стоит познакомиться. Многим стоит подумать и о применении этой технологии в своих проектах. В частности, если ваши проекты кажутся не особенно производительными, если вы занимаетесь разработкой сложных интерфейсов, наподобие панелей управления, лент новостей или профилей пользователей, то вы уже знаете о том, где именно вы можете опробовать GraphQL.
Уважаемые читатели! Если сегодня состоялось ваше первое знакомство с GraphQL — просим рассказать нам о том, планируете ли вы использовать эту технологию в своих проектах.


by Leonardo Maldonado
One of the most commonly discussed terms today is the API. A lot of people don’t know exactly what an API is. Basically, API stands for Application Programming Interface. It is, as the name says, an interface with which people — developers, users, consumers — can interact with data.
You can think of an API as a bartender. You ask the bartender for a drink, and they give you what you wanted. Simple. So why is that a problem?
Since the start of the modern web, building APIs has not been as hard as it sounds. But learning and understanding APIs was. Developers form the majority of the people that will use your API to build something or just consume data. So your API should be as clean and as intuitive as possible. A well-designed API is very easy to use and learn. It’s also intuitive, a good point to keep in mind when you’re starting to design your API.
We’ve been using REST to build APIs for a long time. Along with that comes some problems. When building an API using REST design, you’ll face some problems like:
1) you’ll have a lot of endpoints
2) it’ll be much harder for developers to learn and understand your API
3) there is over- and under-fetching of information
To solve these problems, Facebook created GraphQL. Today, I think GraphQL is the best way to build APIs. This article will tell you why you should start to learn it today.
In this article, you’re going to learn how GraphQL works. I’m going to show you how to create a very well-designed, efficient, powerful API using GraphQL.
You’ve probably already heard about GraphQL, as a lot of people and companies are using it. Since GraphQL is open-source, its community has grown huge.
Now, it’s time for you start to learn in practice how GraphQL works and all about its magic.
What is GraphQL?
GraphQL is an open-source query language developed by Facebook. It provides us with a more efficient way design, create, and consume our APIs. Basically, it’s the replacement for REST.
GraphQL has a lot of features, like:
- You write the data that you want, and you get exactly the data that you want. No more over-fetching of information as we are used to with REST.
- It gives us a single endpoint, no more version 2 or version 3 for the same API.
- GraphQL is strongly-typed, and with that you can validate a query within the GraphQL type system before execution. It helps us build more powerful APIs.
This is a basic introduction to GraphQL — why it’s so powerful and why it’s gaining a lot of popularity these days. If you want to learn more about it, I recommend you to go the GraphQL website and check it out.
Getting started
The main objective in this article is not to learn how to set up a GraphQL server, so we’re not getting deep into that for now. The objective is to learn how GraphQL works in practice, so we’re gonna use a zero-configuration GraphQL server called ☄️ Graphpack.
To start our project, we’re going to create a new folder and you can name it whatever you want. I’m going to name it graphql-server:
Open your terminal and type:
mkdir graphql-serverNow, you should have npm or yarn installed in your machine. If you don’t know what these are, npm and yarn are package managers for the JavaScript programming language. For Node.js, the default package manager is npm.
Inside your created folder type the following command:
npm init -yOr if you use yarn:
yarn init npm will create a package.json file for you, and all the dependencies that you installed and your commands will be there.
So now, we’re going to install the only dependency that we’re going to use.
☄️Graphpack lets you create a GraphQL server with zero configuration. Since we’re just starting with GraphQL, this will help us a lot to go on and learn more without getting worried about a server configuration.
In your terminal, inside your root folder, install it like this:
npm install --save-dev graphpackOr, if you use yarn, you should go like this:
yarn add --dev graphpackAfter Graphpack is installed, go to our scripts in package.json file, and put the following code there:
"scripts": {
"dev": "graphpack",
"build": "graphpack build"
}We’re going to create a folder called src, and it’s going to be the only folder in our entire server.
Create a folder called src, after that, inside our folder, we’re going to create three files only.
Inside our src folder create a file called schema.graphql. Inside this first file, put the following code:
type Query {
hello: String
}In this schema.graphql file is going to be our entire GraphQL schema. If you don’t know what it is, I’ll explain later — don’t worry.
Now, inside our src folder, create a second file. Call it resolvers.js and, inside this second file, put the following code:
import { users } from "./db";
const resolvers = {
Query: {
hello: () => "Hello World!"
}
};
export default resolvers;This resolvers.js file is going to be the way we provide the instructions for turning a GraphQL operation into data.
And finally, inside your src folder, create a third file. Call this db.js and, inside this third file, put the following code:
export let users = [
{ id: 1, name: "John Doe", email: "john@gmail.com", age: 22 },
{ id: 2, name: "Jane Doe", email: "jane@gmail.com", age: 23 }
];In this tutorial we’re not using a real-world database. So this db.js file is going to simulate a database, just for learning purposes.
Now our src folder should look like this:
src
|--db.js
|--resolvers.js
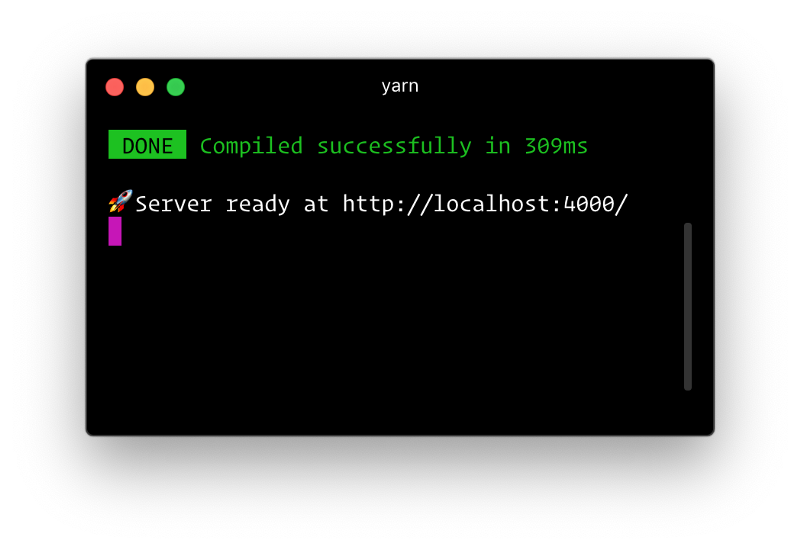
|--schema.graphqlNow, if you run the command npm run dev or, if you’re using yarn, yarn dev, you should see this output in your terminal:
You can now go to localhost:4000 . This means that we’re ready to go and start writing our first queries, mutations, and subscriptions in GraphQL.
You see the GraphQL Playground, a powerful GraphQL IDE for better development workflows. If you want to learn more about GraphQL Playground, click here.
Schema
GraphQL has its own type of language that’s used to write schemas. This is a human-readable schema syntax called Schema Definition Language (SDL). The SDL will be the same, no matter what technology you’re using — you can use this with any language or framework that you want.
This schema language its very helpful because it’s simple to understand what types your API is going to have. You can understand it just by looking right it.
Types
Types are one of the most important features of GraphQL. Types are custom objects that represent how your API is going to look. For example, if you’re building a social media application, your API should have types such as Posts, Users, Likes, Groups.
Types have fields, and these fields return a specific type of data. For example, we’re going to create a User type, we should have some name, email, and age fields. Type fields can be anything, and always return a type of data as Int, Float, String, Boolean, ID, a List of Object Types, or Custom Objects Types.
So now to write our first Type, go to your schema.graphql file and replace the type Query that is already there with the following:
type User {
id: ID!
name: String!
email: String!
age: Int
}Each User is going to have an ID, so we gave it an ID type. User is also going to have a name and email, so we gave it a String type, and an age, which we gave an Int type. Pretty simple, right?
But, what about those ! at the end of every line? The exclamation point means that the fields are non-nullable, which means that every field must return some data in each query. The only nullable field that we’re going to have in our User type will be age.
In GraphQL, you will deal with three main concepts:
- queries — the way you’re going to get data from the server.
- mutations — the way you’re going to modify data on the server and get updated data back (create, update, delete).
- subscriptions — the way you’re going to maintain a real-time connection with the server.
I’m going to explain all of them to you. Let’s start with Queries.
Queries
To explain this in a simple way, queries in GraphQL are how you’re going to get data. One of the most beautiful things about queries in GraphQL is that you are just going to get the exact data that you want. No more, no less. This has a huge positive impact in our API — no more over-fetching or under-fetching information as we had with REST APIs.
We’re going to create our first type Query in GraphQL. All our queries will end up inside this type. So to start, we’ll go to our schema.graphql and write a new type called Query:
type Query {
users: [User!]!
}It’s very simple: the users query will return to us an array of one or more Users. It will not return null, because we put in the ! , which means it’s a non-nullable query. It should always return something.
But we could also return a specific user. For that we’re going to create a new query called user. Inside our Query type, put the following code:
user(id: ID!): User!
Now our Query type should look like this:
type Query {
users: [User!]!
user(id: ID!): User!
}As you see, with queries in GraphQL we can also pass arguments. In this case, to query for a specific user, we’re going to pass its ID.
But, you may be wondering: how does GraphQL know where get the data? That’s why we should have a resolvers.js file. That file tells GraphQL how and where it’s going to fetch the data.
First, go to our resolvers.js file and import the db.js that we just created a few moments ago. Your resolvers.js file should look like this:
import { users } from "./db";
const resolvers = {
Query: {
hello: () => "Hello World!"
}
};
export default resolvers;Now, we’re going to create our first Query. Go to your resolvers.js file and replace the hello function. Now your Query type should look like this:
import { users } from "./db";
const resolvers = {
Query: {
user: (parent, { id }, context, info) => {
return users.find(user => user.id === id);
},
users: (parent, args, context, info) => {
return users;
}
}
};
export default resolvers;Now, to explain how is it going to work:
Each query resolver has four arguments. In the user function, we’re going to pass id as an argument, and then return the specific user that matches the passed id. Pretty simple.
In the users function, we’re just going to return the users array that already exists. It’ll always return to us all of our users.
Now, we’re going to test if our queries are working fine. Go to localhost:4000 and put in the following code:
query {
users {
id
name
email
age
}
}It should return to you all of our users.
Or, if you want to return a specific user:
query {
user(id: 1) {
id
name
email
age
}
}Now, we’re going to start learning about mutations, one of the most important features in GraphQL.
Mutations
In GraphQL, mutations are the way you’re going to modify data on the server and get updated data back. You can think like the CUD (Create, Update, Delete) of REST.
We’re going to create our first type mutation in GraphQL, and all our mutations will end up inside this type. So, to start, go to our schema.graphql and write a new type called mutation:
type Mutation {
createUser(id: ID!, name: String!, email: String!, age: Int): User!
updateUser(id: ID!, name: String, email: String, age: Int): User!
deleteUser(id: ID!): User!
}As you can see, we’re going to have three mutations:
createUser: we should pass an ID, name, email, and age. It should return a new user to us.
updateUser: we should pass an ID, and a new name, email, or age. It should return a new user to us.
deleteUser: we should pass an ID. It should return a new user to us.
Now, go to our resolvers.js file and below the Query object, create a new mutation object like this:
Mutation: {
createUser: (parent, { id, name, email, age }, context, info) => {
const newUser = { id, name, email, age };
users.push(newUser);
return newUser;
},
updateUser: (parent, { id, name, email, age }, context, info) => {
let newUser = users.find(user => user.id === id);
newUser.name = name;
newUser.email = email;
newUser.age = age;
return newUser;
},
deleteUser: (parent, { id }, context, info) => {
const userIndex = users.findIndex(user => user.id === id);
if (userIndex === -1) throw new Error("User not found.");
const deletedUsers = users.splice(userIndex, 1);
return deletedUsers[0];
}
}Now, our resolvers.js file should look like this:
import { users } from "./db";
const resolvers = {
Query: {
user: (parent, { id }, context, info) => {
return users.find(user => user.id === id);
},
users: (parent, args, context, info) => {
return users;
}
},
Mutation: {
createUser: (parent, { id, name, email, age }, context, info) => {
const newUser = { id, name, email, age };
users.push(newUser);
return newUser;
},
updateUser: (parent, { id, name, email, age }, context, info) => {
let newUser = users.find(user => user.id === id);
newUser.name = name;
newUser.email = email;
newUser.age = age;
return newUser;
},
deleteUser: (parent, { id }, context, info) => {
const userIndex = users.findIndex(user => user.id === id);
if (userIndex === -1) throw new Error("User not found.");
const deletedUsers = users.splice(userIndex, 1);
return deletedUsers[0];
}
}
};
export default resolvers;Now, we’re going to test if our mutations are working fine. Go to localhost:4000 and put in the following code:
mutation {
createUser(id: 3, name: "Robert", email: "robert@gmail.com", age: 21) {
id
name
email
age
}
}It should return a new user to you. If you want to try making new mutations, I recommend you to try for yourself! Try to delete this same user that you created to see if it’s working fine.
Finally, we’re going to start learning about subscriptions, and why they are so powerful.
Subscriptions
As I said before, subscriptions are the way you’re going to maintain a real-time connection with a server. That means that whenever an event occurs in the server and whenever that event is called, the server will send the corresponding data to the client.
By working with subscriptions, you can keep your app updated to the latest changes between different users.

A basic subscription is like this:
subscription {
users {
id
name
email
age
}
}You will say it’s very similar to a query, and yes it is. But it works differently.
When something is updated in the server, the server will run the GraphQL query specified in the subscription, and send a newly updated result to the client.
We’re not going to work with subscriptions in this specific article, but if you want to read more about them click here.
Conclusion
As you have seen, GraphQL is a new technology that is really powerful. It gives us real power to build better and well-designed APIs. That’s why I recommend you start to learn it now. For me, it will eventually replace REST.
Thanks for reading the article.
Follow me on Twitter!
Follow me on GitHub!
I’m looking for a remote opportunity, so if have any I’d love to hear about it, so please contact me at my Twitter!
Learn to code for free. freeCodeCamp’s open source curriculum has helped more than 40,000 people get jobs as developers. Get started
Learn useful terminology and concepts for using the GitHub GraphQL API.
GraphQL terminology
The GitHub GraphQL API represents an architectural and conceptual shift from the GitHub REST API. You will likely encounter some new terminology in the GraphQL API reference docs.
Schema
A schema defines a GraphQL API’s type system. It describes the complete set of possible data (objects, fields, relationships, everything) that a client can access. Calls from the client are validated and executed against the schema. A client can find information about the schema via introspection. A schema resides on the GraphQL API server. For more information, see «Discovering the GraphQL API.»
Field
A field is a unit of data you can retrieve from an object. As the official GraphQL docs say:
«The GraphQL query language is basically about selecting fields on objects.»
The official spec also says about fields:
All GraphQL operations must specify their selections down to fields which return scalar values to ensure an unambiguously shaped response.
This means that if you try to return a field that is not a scalar, schema validation will throw an error. You must add nested subfields until all fields return scalars.
Argument
An argument is a set of key-value pairs attached to a specific field. Some fields require an argument. Mutations require an input object as an argument.
Implementation
A GraphQL schema may use the term implements to define how an object inherits from an interface.
Here’s a contrived example of a schema that defines interface X and object Y:
interface X {
some_field: String!
other_field: String!
}
type Y implements X {
some_field: String!
other_field: String!
new_field: String!
}
This means object Y requires the same fields/arguments/return types that interface X does, while adding new fields specific to object Y. (The ! means the field is required.)
In the reference docs, you’ll find that:
-
Each object lists the interface(s) from which it inherits under Implements.
-
Each interface lists the objects that inherit from it under Implementations.
Connection
Connections let you query related objects as part of the same call. With connections, you can use a single GraphQL call where you would have to use multiple calls to a REST API. For more information, see «Migrating from REST to GraphQL.»
It’s helpful to picture a graph: dots connected by lines. The dots are nodes, the lines are edges. A connection defines a relationship between nodes.
Edge
Edges represent connections between nodes. When you query a connection, you traverse its edges to get to its nodes. Every edges field has a node field and a cursor field. Cursors are used for pagination.
Node
Node is a generic term for an object. You can look up a node directly, or you can access related nodes via a connection. If you specify a node that does not return a scalar, you must include subfields until all fields return scalars. For information on accessing node IDs via the REST API and using them in GraphQL queries, see «Using global node IDs.»
Discovering the GraphQL API
GraphQL is introspective. This means you can query a GraphQL schema for details about itself.
-
Query
__schemato list all types defined in the schema and get details about each:query { __schema { types { name kind description fields { name } } } } -
Query
__typeto get details about any type:query { __type(name: "Repository") { name kind description fields { name } } } -
You can also run an introspection query of the schema via a
GETrequest:$ curl -H "Authorization: bearer TOKEN" https://api.github.com/graphqlNote: If you get the response
"message": "Bad credentials"or401 Unauthorized, check that you are using a valid token. The GraphQL API only supports authentication using a personal access token (classic). For more information, see «Creating a personal access token.»The results are in JSON, so we recommend pretty-printing them for easier reading and searching. You can use a command-line tool like jq or pipe the results into
python -m json.toolfor this purpose.Alternatively, you can pass the
idlmedia type to return the results in IDL format, which is a condensed version of the schema:$ curl -H "Authorization: bearer TOKEN" -H "Accept: application/vnd.github.v4.idl" https://api.github.com/graphqlNote: The introspection query is probably the only
GETrequest you’ll run in GraphQL. If you’re passing a body, the GraphQL request method isPOST, whether it’s a query or a mutation.For more information about performing queries, see «Forming calls with GraphQL.»